Recently, I have found myself reflecting on the statement, “Be a force multiplier.” This usually comes to mind when faced with some sort of burnout: hearing it indirectly from a colleague or friend, or experiencing it firsthand. The intent is good and aligns well with some core tenants of DevOps. Force multiplication fits into the DevOps ethos by encouraging the need to cross-train and collaborate. By working together and sharing knowledge about respective domains (development or operations), team members gain empathy for each other. This in turn has a downstream effect of now enabling better collaboration around the repair/growth/operation/expansion of the delivery pipeline.
The only challenge I have seen over and over again is that one or more major bottlenecks exist by the time this idea of “force multiplication” is needed in a team. These bottlenecks are often real and result from an imbalance of resources: servers arriving faster than there are resources to rack/stack/configure/turn up. Database administrators cannot handle the number of schema changes needed to be reviewed/tested/deployed. Developers must wait on a certain person or people who have access to publish a package before it can “go live.” You probably have your own bottleneck that you see very clearly in your own mind.
The next question: Have you (or someone you know) attempted to be a “force multiplier”? The answer always is complex, but a there is always a common theme in noble attempts at team cleanup: lack of training. Think about it: Have you been taught how to be a force multiplier? How to build well-formed teams? How to effectively pass on knowledge? To compound issues even further, our current incentive structure actually celebrates the “heroes” and “unicorns” of the world, calling out these as examples of success. Our economy rewards those first to market, and team-building and normalization often are not high priorities for budding startups today. Unless improvement efforts have a direct impact on the bottom line, often it isn’t a priority. The folks that are brave enough to still even take on the challenge of being a “force multiplier” in these conditions often find little success because knowledge transfer must happen in synchronous fashions: code-pairing, over-the-shoulder demonstrations, etc. These are expensive activities in both time and energy. Opportunity cost is now lost because one resource is cross-training another. Eventually the benefits will be realized, but not today …
The amount of work is too large. As a result, the can is kicked down the road until such a time that the pain is unbearable and something must be done. At this point, everyone wants to burn down the offending code and start again. But next time, we’ll learn. We won’t make the same mistakes we did last time.
Bite-sized changes
The problem is that when looking at the road in front of you, you’re constantly optimizing for the next day or week as opposed to months and years ahead. In the world of quarterly returns, this is the incentive that drives us. Thus, by the time problems are real problems, it is easy to immediately begin the bikeshed conversation and begin designing v2. The next step is to re-adjust the optimization factor. Growing the meat-cloud and getting additional resources often takes too long (three-to-six month onboard time, at least), the time cost of cross-training can be too much, and overworking resources can only go so far. What is the answer?




Level the playing field
One of the ideas that I share around ChatOps and Event Driven Automation is to expose small tasks to users. By doing this, you allow team members and others in your company to “consume” actions that you curate. As the curator, you can expose safe actions to users and allow them to do things once relegated to a single individual or team. I’d like to share a real-world story with you and show you how we solved it.
Bottlenecks at StackStorm
Recently, our team was bottlenecked in releasing updates to our Puppet module for StackStorm. The team could make changes all day long in the test environment, but getting changes out to the world depended on a single person releasing code to the Puppet Forge. Obviously, this was not ideal.
Let’s break it down. To release a module to the forge, a user must know:
- Know how to make a change to the puppet module
- Update module itself
- Update metadata
- Update git repository (tags)
- Know how properly package up the module for release to the forge
- Know the credentials for the Puppet Forge
At face value, this seems minor—just throw these commands into a README, and let others just copy/paste commands. But, my team is not full of Puppet experts. They are developers, eager to help solve interesting problems. But because of this barrier to release, the natural reaction was to shy away from making changes—not because of capability or willingness, but to avoid the pain of friction involved with releasing the code. This meant that any change to the codebase usually required at least two people (change and release). Likewise, any changes that were small or simple naturally got relegated to Puppet people because they knew how to manage the debt and navigate the waters.
Instead, let’s sprinkle some magic ChatOps dust.
The Setup
First, let’s set up our user interface: ChatOps. User experience is a topic that will come up over and over again with ChatOps, so the best place to begin is to decide how to expose commands to colleagues and users. The first thing to set up is the ChatOps Alias.

I want an all-encompasing command that a user should have to input a minimal amount of information toward. The goal is to have a big red button that can be mashed, and magically a Puppet module is released. This should now happen anytime a user types in !puppet publish puppet-st2 … StackStorm will run the stackstorm.publish-puppet-st2 action with the branch attribute set to whatever the user types in. We choose to reuse the puppet namespace since it is already populated with similar actions.
The next step is to set up some accompanying Action Metadata for the new stackstorm.publish-puppet-st2 action. We’ll want this to run a new workflow that will take care of all the actions we discussed above. The only variable that I need to get from the user is the branch parameter, so writing the metadata should be a snap. We’ll only take a look at the workflow today.
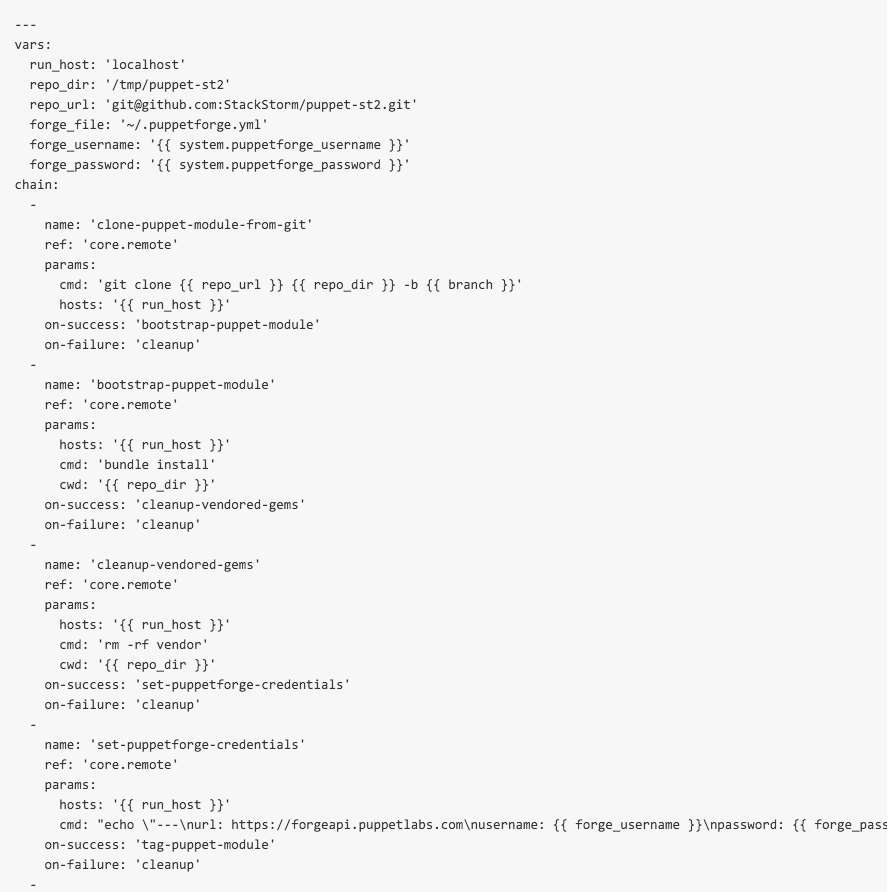
At the top of the file includes our vars section. The puppet-blacksmith application was not built to be run with multiple users, so our workflow needs to be able to adapt. As such, we need to know that the gem will expect a credential file (forge_file) with a username (forge_username) and password (forge_password). We also need to know where our staging directory is (repo_dir), where the upstream target is (repo_url). Simple enough. The next few steps, clone-puppet-module-from-git, bootstrap-puppet-module, cleanup-vendored-gems and set-puppetforge-credentials ensure the build host is setup properly. These actions serially download the repository from Upstream, runs all bootstrap commands, attempts to ensure a pristine directory, and then sets up the puppet-blacksmith forge file. At this point, nothing has actually been done, just some preparation.
It’s important to note the third step here (cleanup-vendored-gems): This was a small step that often was forgotten and ended up creating archives in the size of megabytes as opposed to kilobytes, which is more reasonable and expected.
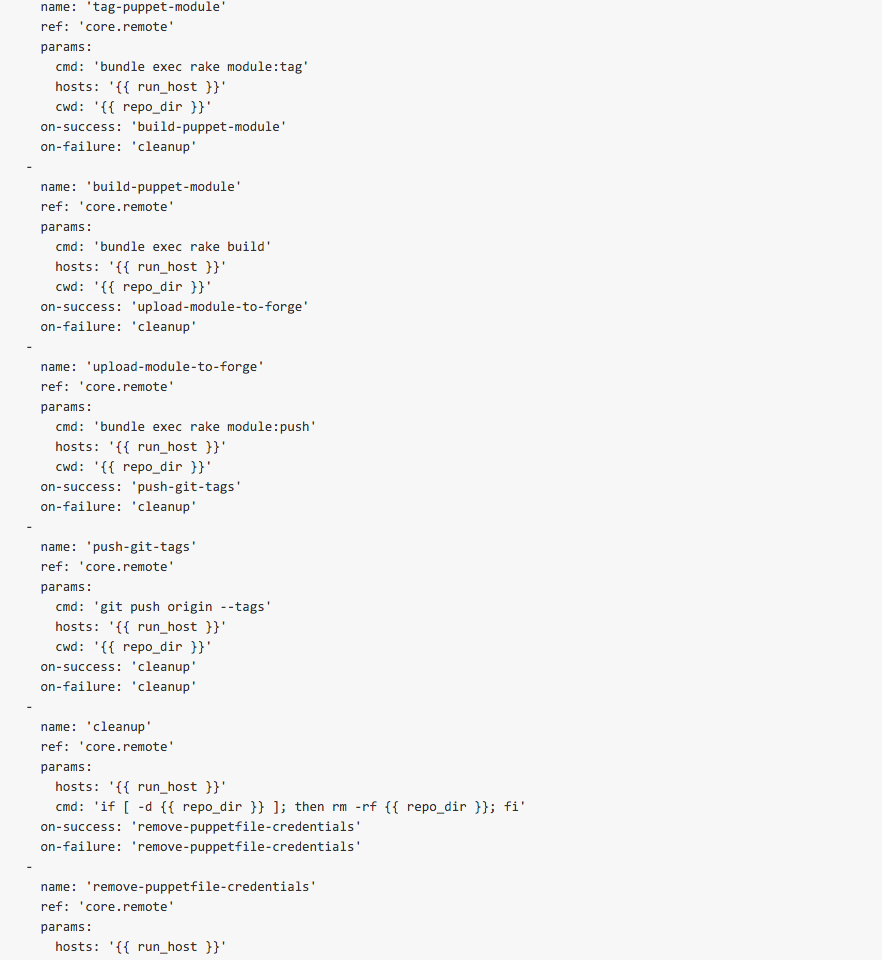
The final steps—tag-puppet-module, build-puppet-module, upload-module-to-forge and push-git-tags—are where the bulk of work occurs. The next steps are focused on running several rake tasks, as well as then tagging the git repository and republishing the package upstream. Most of these actions were enabled by the puppet-blacksmith gem, but now are encapsulated in a nice workflow that is easily consumable.
And sure enough, if you build it, they will come …
slack slack_1
Techniques like this directly enable force multiplication within your team. Essentially, your role shifts from a person “responsible” for delivering to the person for “enabling” delivery. This is a very small example, but powerful. Enabling others on your team to be a force multiplier enables them to keep working, enables you to focus on more important things and also creates a new degree of transparency that may not have existed before. Everyone knows when software is released; anyone has the ability to do this. Add up enough of these small building blocks, and suddenly team members are more apt to take risk and help drive change knowing there is a safety net behind them.
Worth consideration
Two very interesting points were presented to me that are worth discussion here:
Agile Manifesto, rule #1: Individuals and interactions over processes and tools. Tools that try to enforce a workflow of a human? GTFO!
How far does this paradigm extend? For sure, “process” is the worst. When invoked, it usually means a large amount of paperwork or rules that must be strictly adhered to. The downside is that many of said process are manual in nature and, as a result, error-prone. Likewise, in companies that implement a tool before understanding what they want to achieve or, at the very least, defining a set of principles, the tools end up shaping how the company works rather than the other way around. The point here is that humans are in charge.
Agreed. What is unreasonable here is the underlying expectation that exists here and across the IT industry: technologists must know an immense amount about an immense number of things. Even in my own domains of expertise, I can think of nothing more demotivating than trying to remember how to deploy code that I haven’t touched in three-plus months. Eventually I’ll remember, but it’s a drag and introduces unnecessary friction. Now, play that out in a larger team and multiply.
‘I will become redundant’: I have yet to see this happen. What instead happens is collaboration. Developers can focus on shipping and keeping their code up to date without bugging operations, and operations can care about aggregate problems (capacity, power, storage) as opposed to transactional tasks such as “push this code” or “reset this password.” Most devs I know are not afraid to get dirty, but it’s not where they would rather spend time. Devs want to develop. If you can enable them with better tools to do exactly that, everyone wins. The glucose you were once burning on smaller tasks can and often do become self-service, and you get to go and create even more cool interfaces for users to consume.
Wrap Up
Bottlenecks exist. They can and will continue to pop up as companies grow and expand. Sometimes you may find yourself in a situation where bottlenecks accumulate over time as a result of technical debt, while other times you join a new team and that debt may already be gaining interest on amounts owed. Either way, the situation exists where something needs to be done. Instead of going directly for the RPG, burning down the house and starting over, consider smaller approaches to enable others to do the things you do.
Some thoughts to take with you today:
- Tend your technology garden: curate, don’t operate
- Make small, transparent changes for lasting effect
- Grow it together: don’t control the change
Until next time!
About the Author/James Fryman
 Now a senior DevOps engineer at StackStorm, James most recently worked at GitHub assisting in the development and curation of systems scaling within the Operations group. James is also a frequent speaker on the topic of automation at conferences throughout the world.
Now a senior DevOps engineer at StackStorm, James most recently worked at GitHub assisting in the development and curation of systems scaling within the Operations group. James is also a frequent speaker on the topic of automation at conferences throughout the world.