Many of the hallmarks of modern application development that drive efficiencies in the software development life cycle (agile, CI/CD, microservices, cloud infrastructure, open source libraries and third-party APIs) also create significant data leakage risks. Meanwhile, the EU’s General Data Protection Regulation (GDPR), which took effect May 25, creates a need to protect more types of data than ever before and comes with the strongest penalties for non-compliance: €20 million or up to 4 percent of a company’s global revenue.
Preventing Data Leakage Getting More Difficult
There are three primary reasons why data leakage has become more challenging for developers: complexity, speed and external services.
Applications themselves have become more complex as organizations adopt microservices architectures. While this enables developers to be more efficient, it also often leads to more siloed views of the application while the data flows become more complex. For example, how many organizations understand every entry point, exit point and handling of variables across every microservice in their broader application? And, organizations that adopt open source to increase efficiency by not having to reinvent non-differentiating code often fail to comprehensively understand the third-party code in depth. This makes understanding data flows even more difficult.
The increasing pace of releases exacerbates complexity issues. Many organizations now release monthly, weekly or even daily. With less time to focus on anything beyond meeting feature deadlines, mapping data flows often becomes an afterthought. Furthermore, even if an organization is able to thoroughly map their data flows for any given point in time, the rate of change makes it impossible to stay on top.
As organizations adopt third-party services for key functions such as code repositories, logging, databases and analytics, the consequences of leaking data become severe. For example, Uber leaked AWS credentials into GitHub, from which bad actors were able to initiate an attack that lead to 57 million records being compromised—simply by logging in.




Why GDPR is Different
GDPR is a significant expansion of previous data protection regulations in a number of ways. Unlike the Health Insurance Portability and Accountability Act (HIPAA) and Payment Card Industry Data Security Standard (PCI DSS) in the United States, GDPR applies globally and across industries. Any company that holds or processes data on an EU resident is subject to the regulation. Cloud-based software is inherently more global, and many U.S. or Asian-based organizations have users that are EU residents.
GDPR expands the definition of what needs to be protected in a big way. HIPAA and PCI DSS formalized rules around protecting healthcare and credit card data. However, GDPR expands data that must be protected to include anything that can be used to identify a person—anything from a name, a photo, an email address, bank details, posts on social networking websites, medical information or a computer IP address.
And GDPR has real teeth. Companies can be fined up to 4 percent of their annual global revenue or €20 million for major breaches and 2 percent of their global revenue for minor breaches. Given the global nature of modern cloud applications, the potential impact of GDPR is far-reaching.
Traditional Approaches to Preventing Data Leakages
Traditional approaches to preventing data leakage have been focused primarily on acting as a proxy between the application and the rest of the world. In such a position, the proxy can attempt to filter data and look for patterns. These approaches are outside-in. They do not attempt to understand the application itself; rather, they inspect traffic flowing from the application without context.
First, let’s clarify that despite the similar sounding name, preventing data leakage is not the same as data loss prevention (DLP). Traditional DLP vendors such as Vontu (now Symantec) and cloud access security brokers (CASBs) are solving a different problem. They are an IT-centric solution to preventing malicious or accidental data breaches that are typically driven by end-users moving documents via email or file sharing. These tools aren’t designed to prevent the applications themselves leaking data and they are of little use to developers.
The more application-specific attempts to identify data leakage have been via web application firewalls (WAFs). As proxies, WAFs often employ pattern matching techniques such as looking for 16-digit numbers on the assumption it may be a payment card, keyword matching, fingerprinting and other statistical content analysis techniques. In practice, these methods are ineffective because they create far too many false positives. Furthermore, encryption is problematic in that the WAF either can’t inspect the data or a man in the middle decryption must be set up, which is computationally expensive and can add latency. Latency may not matter for traditional DLP solutions monitoring email, but it’s vitally important to developers managing cloud applications.
One traditional method for identifying data leakage that does take and inside-out approach is taint tracking, which evaluates pre-existing binaries. In reality, taint tracking is impractical because of excessive performance costs and numerous false positives due to taint proliferation (transitively from application to web framework to kernel).
Taint and information-flow analysis approaches track the flow of data through the program, assuming that the data originated from untrusted sources. Sources are where such data flows enter the program, and sinks are where they leave the program.
Several publications define sinks informally as “data that leaves the system,” which is too imprecise to train a machine-learning based classifier; such classifiers are only as good as their training data.
Dynamic taint tracking by plain instrumented emulation is extremely expensive and tend to slow systems. Such a slowdown is unacceptable in practice and significantly hinders the adoption of dynamic taint tracking systems for everyday use. Such taint proliferation can substantially impair the performance of the running system.
Mapping Data Flows with Semantic Graphing
To truly prevent data leakage, you must first map data flows. You must understand the building blocks of the application, including its security DNA. However, the difficulty comes from balancing comprehensiveness with speed. Simply put, to account for all possible leakages in a rapidly evolving application you must automate.

Semantic graphing is based on a simple observation: There are many different graph representations of code, and patterns in code often can be expressed as patterns in these graphs. It is a graph of graphs that, for the first time, enables automatically creating profiles that understand the context of an application. Semantic graphing is language-neutral intermediary representation designed for code querying, which focuses on what the program is designed to do, what it is not supposed to do and how it functions. Because semantic graphing identifies which variables are sensitive and how they flow across each microservice, it then becomes possible to visually represent data paths and identity leakage/violations.
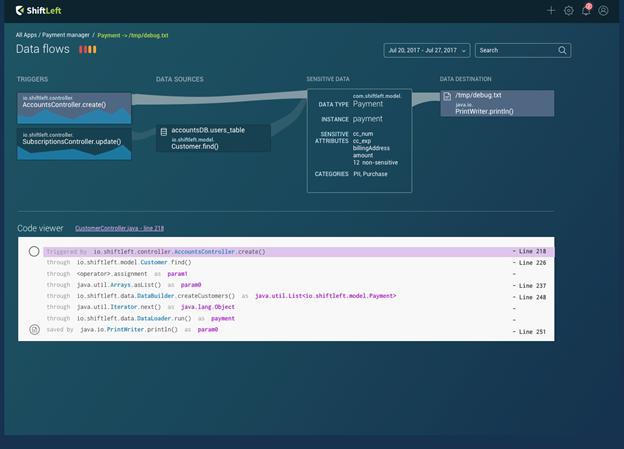
In this instance, we seek to understand data flows and prevent leakages. However, the ability to understand an application’s context in code is fundamentally the foundation for DevSecOps. AppSec remains manual primarily because humans must apply the application’s context either through configuring rulesets or wading through false positives, both of which are impossible tasks. Beyond just data leakage, semantic graphing has the potential to deliver security at the speed of DevOps.