After a service upgrade the pods are taking too long to serve traffic. What would you need to find out to debug?
1. The validating webhook for pods has failed
2. The cluster doesn’t have enough CPU/memory to schedule the pod to a node
3. The new code added an init container and the init container is taking a long time to finish
4. The new deployment changed the readiness probe
5. There is a bug in the code
100 people answered the question. And their answers are reflected in the chart below.
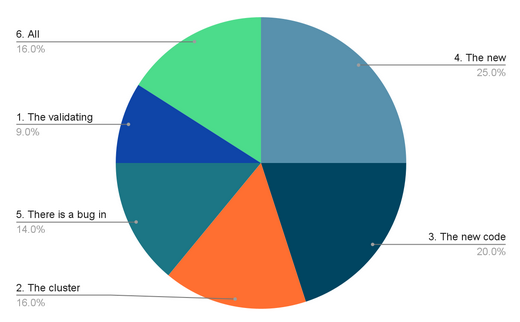
Each of the provided choices is indeed a correct answer – meaning 16 people got the right answer. Let’s breakdown each of the choices in the context of troubleshooting slow pod response times after a service upgrade:
The validating webhook for pods has failed: Validating webhooks in Kubernetes are responsible for ensuring that pods conform to certain policies before being created. If the validating webhook fails, it can prevent pod creation altogether, which would certainly impact the ability of new pods to serve traffic. Therefore, this is a correct choice to consider when debugging service issues.
The cluster doesn’t have enough CPU/memory to schedule the pod to a node: When a service is upgraded, its resource requirements may change. If the cluster lacks the necessary CPU or memory resources to schedule the new pods, it can lead to delayed pod scheduling and slow response times. This is a common issue that SREs and DevOps need to investigate when traffic-serving problems arise after an upgrade.
The new code added an init container, and the init container is taking a long time to finish: Init containers are executed before the main application containers in a pod. If a new init container is introduced during an upgrade and it takes an extended time to complete its tasks, it can indeed cause delays in the pod becoming ready to serve traffic. This is a relevant consideration when diagnosing slow response times post-upgrade.
The new deployment changed the readiness probe: The readiness probe determines when a pod is ready to accept traffic. If the readiness probe is modified during an upgrade and is now misconfigured, it can delay the point at which the pod is considered ready to serve traffic.
Therefore, this is an accurate choice for troubleshooting slow response times.
One of our earlier quiz questions dealt with a similar issue which we discussed in the following blog: https://webb.ai/blog/quiz-1-aug-1-23-healthcheck-port-mismatch/
There is a bug in the code: While the broadest option, it’s also valid. Code bugs can absolutely result in slow response times. However, it’s crucial to note that this choice doesn’t specify what type of bug or where in the code it might be. It highlights the importance of code review and debugging as part of the troubleshooting process.
In summary, all the provided choices are correct because they represent various potential causes of slow pod response times after a service upgrade. Troubleshooting such issues often requires considering a combination of factors, from resource constraints to configuration changes and code-related problems. SREs and DevOps professionals must approach the problem with a holistic perspective to identify and address the root causes effectively.
There are additional reasons, not included in the options provided, for slow pod response times after a service upgrade:
Network Latency/Issues: Connectivity problems, network misconfigurations, or high network latency between pods and services can cause delays in serving traffic.
Storage Latency: Slow storage I/O or inadequate storage resources can impact data retrieval and processing, affecting pod performance.
Resource Contentions: Other resource-intensive workloads on the same nodes can lead to resource contentions, resulting in slow pod response times due to competition for CPU, memory, or disk resources.
Analyzing each potential root cause for each failure is not possible in today’s highly dynamic environments. Leveraging software and the recent advancements in AI to automate root cause analysis is one way to reduce toil and increase productivity allowing SRE and DevOps to become proactive and focus on addressing more complex failure scenarios.
–
In a Kubernetes environment, a recent pod scheduling failure occurred due to a specific configuration. Which Kubernetes resource type, often associated with node constraints, might have caused this failure, especially if it wasn’t defined correctly?
- A) NodeSelector B) ResourceQuota C) PriorityClass D) Taint E) PodDisruptionBudget
From an SRE perspective, let’s explain why “Taint” is the right answer in the context of a pod scheduling failure due to a specific configuration, and why the other choices are not as suitable:
Taint (Correct Answer):
Taints in Kubernetes are node-level attributes that can be applied to nodes to affect pod scheduling. When a node is tainted, it essentially broadcasts a constraint to pods that they should not be scheduled on that node unless they have a corresponding “toleration.” Here’s why taints are the correct answer:
Node Constraints: Taints are directly related to node constraints. They allow you to specify criteria that restrict which pods can run on specific nodes based on attributes like hardware, software, or other node characteristics. This makes them a crucial resource for controlling where certain workloads are placed within the cluster.
Pod Scheduling: When taints are applied to nodes and pods do not have matching tolerations, they will not be scheduled on those tainted nodes. If a pod is failing to schedule due to a node constraint issue, it’s likely because of taints.
NodeSelector (Not the Best Choice):
NodeSelector is a Kubernetes feature that allows you to set node affinity for your pods based on labels assigned to nodes. While it does influence pod scheduling, it is not primarily associated with node constraints set at the node level like taints.
Node Affinity: NodeSelector is more about node affinity (i.e., preferring nodes with certain labels) rather than constraints. It doesn’t directly prevent pod scheduling but rather guides the scheduler’s preference.
ResourceQuota (Not Related to Node Constraints):
ResourceQuotas are Kubernetes objects that limit resource consumption (CPU, memory, etc.) within namespaces. They do not directly influence pod scheduling based on node constraints, making them less relevant to the given scenario.
Resource Limitation: ResourceQuotas control resource usage within namespaces, but they do not define node-specific constraints or affect where pods can be scheduled within the cluster.
PriorityClass (Not Related to Node Constraints):
PriorityClasses are used to prioritize pods in scheduling order, but they do not define node constraints like taints. They affect the order in which pods are scheduled but do not directly relate to why a pod may fail to schedule due to node-specific constraints.
Scheduling Priority: PriorityClasses are about setting scheduling priorities, not specifying where pods can or cannot run based on node characteristics.
PodDisruptionBudget (Not Related to Node Constraints):
PodDisruptionBudgets are used to control the disruption of pods during voluntary disruptions (e.g., draining a node). They are not associated with node constraints or pod scheduling based on node attributes.
Disruption Control: PodDisruptionBudgets are for controlling disruptions during node maintenance or other planned events, but they do not deal with node constraints affecting pod scheduling.
In summary, when debugging a pod scheduling failure due to a specific configuration, especially one related to node constraints, “Taint” is the most appropriate answer because taints directly influence pod scheduling based on node attributes, whereas the other options are not primarily associated with this aspect of Kubernetes resource management.
