This is a guest post by Phil Cherry from Nolio
A discussion of process-based, package-based, declarative, imperative and generic approaches to application release automation.
Application Release Automation is a relatively new, but rapidly maturing area of IT. As with all new areas there is plenty of confusion around what Application Release Automation really is and the best way to go about it. There are those who come at it with a very developer-centric mind-set, there are those who embrace the modern DevOps concept and even those who attempt to apply server based automation tools to the application space.
Having worked with many companies of various sizes, technologies, cultures and mind-sets; both as they select an ARA (Application Release Automation) tool and as they move on to implement their chosen tool, I have had many opportunities to assess the various approaches. In this short blog I will discuss the pro’s and con’s of each approach.
Package-Based
Package-based automation is a technique that was originally designed for automating the server layer. Due to its success at this, some have attempted to adapt it to automate the application layer as well. Packages encapsulate all the changes that need to be performed on a single server, and can include the pre-requisite checks that need to take place, as well as the post-deployment verifications. When patching a server this makes complete sense, there are no dependencies between the patched server and all the others in the same data centre, and so applying all the required changes for that patch (or patches) in a bundle in one go is possible. The package can then be applied to all appropriate servers without modification. At this layer there is little difference between one Windows Server 2008 and the next, even though the applications on top may be completely different.
The benefit of this packaging approach is the easy rollback capability. If required the package can be easily rolled back to the original server state, but on the other hand it treats each server as an island with no dependency to another server. It assumes that all changes on that server can be done in one go. This type of automation is offered by companies like BMC Bladelogic and IBM Tivoli Provisioning Manager (TPM).
Declarative-Based
Declarative-based automation comes from a similar mindset to package-based but takes a different route to the solution. It also originally came out of the need to automate the server layer and a subsequent attempt to apply it to the application layer. With declarative-based automation, the desired state of the server is defined down to every individual configuration item (registry key, dll, config file entry) etc. Most declarative-based tools require you to describe the desired state by writing what is effectively a piece of ‘code’. Some solutions, for example Puppet, offer a simplified proprietary DSL (Domain Specific Language) but this does not allow you to do everything, and so keeps Ruby as a backup. The downside of this is that the user has to learn at least one programming language (or you have to employ people with that knowledge already) and so does not readily open the automation to non-developers. This approach also has the same downside as package-based automation in that it assumes each server can be configured independently and all in one go. But it also has the same benefits, in that automatic rollback is conceptually a lot easier.
Imperative-Based
Imperative-based automation is more familiar as the structure of the language is closer to traditional programming languages (such as Java, C++, Perl etc). In this approach a programming language is used to describe what needs to be done to the target servers in a series of steps executed in a specific sequence. Chef is an example of an imperative automation tool (the programming language which is based on Ruby). As with declarative-based, the code created (or recipe as it is called in Chef) is still very much focused on making changes to a single isolated server, and the assumption is that those same changes will be applied to multiple servers of the same type. There is limited understanding of making dependant changes across multiple servers, because that was not required at the server layer. It is only important when you move up to the application layer. And of course, the current offerings available still require you to be familiar with, or learn, a programming language to use them.
Generic and Custom-Built Approaches
Often, people try to apply generic approaches (such as Powershell, DOS batch scripts, Perl etc) to the task of automation, or even to write their own automation tool using a compiled language such as Java, C++ etc. As any developer will tell you, they can go and write something that will deploy your application. They can use their preferred language rather than having to use the language supported by the automation platform being employed. And they are right, a development team can indeed write a fully capable deployment tool but the question is: does it really benefit the company to take up development time building and maintaining a deployment tool rather than focusing on the development of their own applications? Even then they will have many issues to face in enabling parallel execution, reporting and auditing, access and permissions control, and importantly synchronising activity across multiple servers. The original intention of these approaches was once again focused on a specific server and not on the cross-server nature of application deployment.
Process-Based
Process-based automation is a different approach, which was created more recently, to address the needs of application release automation. ARA platforms such as DeployIt and UrbanDeploy and, of course, our own tool Nolio all take this approach. These tools seek to support currently existing application deployment processes, the ones that operators could/would normally step through manually. The focus is on processes, and the tools allow an operator to define them in a visual way, with an understanding of the cross-server nature of application deployments. Let’s say that you need to do something on an application’s web server, then the application server, then update tables in the database, then a second change to the application server and finally another change to the web server. With a server-centric approach (such as those discussed above) it is very hard to orchestrate activities across multiple different servers, to synchronise the changes so they happen at the right time in relation to each other, and even to pass information between those servers. With a process-based system this is straightforward – you define the different server types, drop the relevant steps onto each one and draw links to define the synchronisation points (i.e. only do the db steps once the application server steps have been completed).
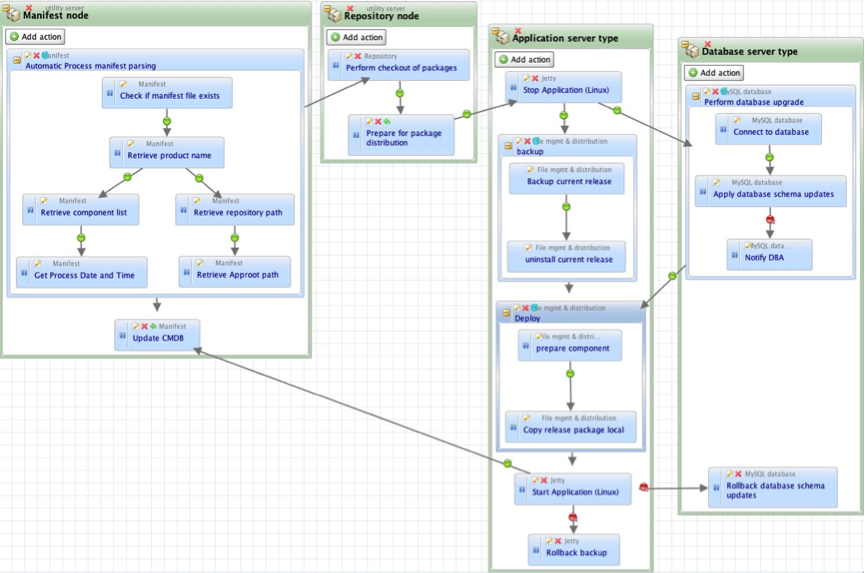
Diagram 1 – Screenshot of a Nolio deployment process, including activity on 4 different server types.
The issues mentioned above such as parallel execution, cross-server synchronisation etc. should already have been dealt with by the ARA platform, rather than having to be created on top of a more generic platform. As you see from the diagram above, with an ARA platform cross-server synchronisation is simply a case of drawing a dependency link between an action on one server type to an action on another server type. Now “Stop Application” action on the “Application Server Type” will not run until “Prepare for package distribution” on “Repository node” has been completed.
In addition to this, process-based automation brings the following benefits: there is no need to modify the deployment process to fit the automation tools’ inability to synchronise activity across multiple servers, thus ensuring the consistency between manual and automated approaches is maintained; the defined process can be used as documentation for how the deployment should be done as it is inherently very readable; there is a detailed and relevant audit trail because the process is inline with how the deployment would be done manually, and it is much easier to diagnose issues because the process follows the expected steps.
You can read more articles on Application Release Automation on Nolio’s Blog Site.
