Kubernetes is rapidly emerging as the standard for application management in the data center. Kubernetes defines applications in a container model for deployment and delivers most of the software-as-a-service features of virtualized infrastructure at a lower cost and with less performance degradation. In this article we’ll cover the intersection of Kubernetes and scale-out data-intensive applications, what problems Kubernetes solves for those applications and why composable infrastructure provides the remaining piece for a total solution.
For heavy-duty data-intensive applications, such as Spark, Kafka, Aerospike, Vertica, Cassandra and Elasticsearch, ML-model training/service with TensorFlow, Kubernetes promises a common application orchestration solution. These applications are termed scale-out because they allow additional performance and capacity to meet any use case simply by adding more nodes. The challenge introduced by these applications is managing large production deployments of each application, compounded by managing multiple applications each with their own configuration requirements. Kubernetes provides an answer here for managing these disparate data-intensive, scale-out applications with a common container orchestration platform.
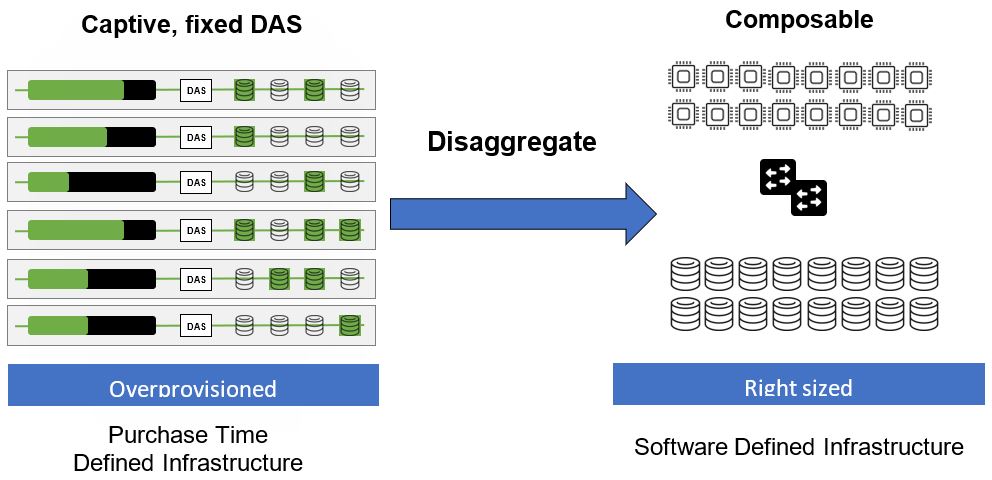
Scale-out applications are distinguished from typical enterprise applications in three ways. First, scale-out applications take a divide-and-conquer approach to problem solving: if you have a bigger problem simply deploy additional capacity and performance by adding nodes. Second, since performance and data capacity are simply increased by adding building blocks, you can exploit cheap commodity-off-the-shelf (COTS) nodes, avoiding the money pit that is the case in big iron hardware purchases required by traditional scale-up applications. Third, the data-intensive applications typically integrate an optimized storage stack within the application itself that effectively uses the cheap local storage available within the COTS nodes. The last point has become a problematic area for scale-out application deployment as overprovisioning is now common to overcome the difficulty in predicting workload behavior at initial deployment time.
Composable infrastructure tackles the last problem presented by embedded local storage for data intensive applications. Looking back over various transformations in the data center, one thing the legacy enterprise storage vendors got right was separating compute and storage. Both during acquisition and throughout the application lifecycle, separating persistent storage components from compute nodes running the actual application yields opportunities for cost efficiencies and flexibility.
Composable infrastructure brings the capability of separating compute from storage for these scale-out applications, which sport their own embedded optimized storage software stack because it does not dictate a new storage architecture, it simply says “take your existing servers with embedded local storage and disaggregate them”–placing the storage on the ubiquitous high-speed low-latency fabric you’ve already deployed for your applications: Ethernet. From the application perspective in a composable infrastructure, storage still appears local and the application runs as it did before.
In this way, applications run unchanged and the infrastructure they run on can be expanded, reduced or replaced in real-time. This is true software-defined infrastructure where infrastructure is treated as code. Being able to modify the node configuration ratio of compute and storage dynamically avoids the issues of purchase time lock-in of possibly under-provisioned nodes (which has simply led to overprovisioning). Composable infrastructure eliminates the downside of purchasing static resources that define the resources available before the workload is run.
Kubernetes launched not long ago in 2015. Many of the early adopters of Kubernetes focused on stateless applications that did not depend on persistent storage to deliver useful services. It is only recently that support for persistent storage emerged (an obvious requirement for data-intensive applications). After a couple of approaches to persistent storage integration, the key players in Kubernetes (and other container orchestration platforms) settled on an orchestration-independent persistent storage API, the Container Storage Interface (CSI). The CSI provides a standard method for storage providers–and composable infrastructure providers–to define and attach persistent storage to containers.
Why should you be interested in composable infrastructure when considering how to deploy your data-intensive applications on Kubernetes? Because Kubernetes only provides application and container orchestration–it does not fundamentally change the way the application works. These data-intensive applications were defined to exploit, and are most efficiently deployed, over COTS node and commodity storage. Each application still has its own storage stack, each carefully optimized for their particular workload. It is likely that deploying storage appliances, or software-defined storage solutions that aggregate pools of HDDs or SSDs, under data-intensive applications will only result in degraded performance and unnecessary costs.
A composable infrastructure solution is only useful as an underlayment for a Kubernetes deployment if it meets several requirements.
First and foremost, the composable infrastructure must scale to 100,000s of devices in support of the applications being deployed on top of the platform.
Second, the composable infrastructure platform must not destabilize or diminish Kubernetes capabilities and scale accordingly with commodity networking in mind. The composable infrastructure solution must share a similar design philosophy with Kubernetes, allowing it to scale. Kubernetes implements a distributed desired state model where work is distributed amongst the mostly autonomous nodes to reach a desired deployment configuration. Such an approach provides scaling on the order required by hyperscalers. You must ensure the composable infrastructure solution you choose provides a similar scalable approach.
Third, Kubernetes emphasizes a configuration state that is durable in the face of any individual node failure or network partitions. Durable configuration state in the face of large, highly interconnected commodity component deployment is critical for correct automatic operation at scale of business-critical applications, and your composable infrastructure solution must similarly support this.
Fourth, Kubernetes defines a model for application deployment in terms of groups of containers called Pods. For a manageable persistent storage solution, the support for CSI and Kubernetes must provide a native Pod view of the storage bindings since the Pod (the managed set of containers) is the proxy for an application node instance and the unit of expansion and migration.
Kubernetes has ushered in an exciting new chapter in data center architecture by providing a lightweight, richly featured application software orchestration platform. Think of Kubernetes as the ideal software application orchestration platform. What is missing is the scalable hardware orchestration solution that supports the dynamic model for application orchestration that Kubernetes defines. A feature rich, well-integrated composable infrastructure platform provides the needed hardware orchestration to enable the application migration and elasticity promised by the Kubernetes solution.
