Science teaches us to formulate hypotheses and test them experimentally to advance systematically. While this sounds logical, DevOps—and software architecture in particular—does not follow this approach because current tools make this too cumbersome. So, architecture choices are frequently made by HiPPO (highest paid person’s opinion).
However, the rate of development, especially in the serverless or function-as-a-service (FaaS) space, makes it difficult to gather all necessary information for HiPPO to work effectively. For example, according to AWS, it publishes on average two new cloud services per day, with similar development rates at other public cloud providers. With so many very nuanced choices, picking the optimal architecture without experimentally testing them is impossible.
We propose a fundamentally different approach for developing efficient and robust serverless architectures: hypothesis-driven architecture evolution, which consists of the steps deploy, evolve, measure, evaluate and iterate. In this blog post, we will go through each component and demonstrate how this can be done in an automated fashion to bring out the inner scientists in all of us.
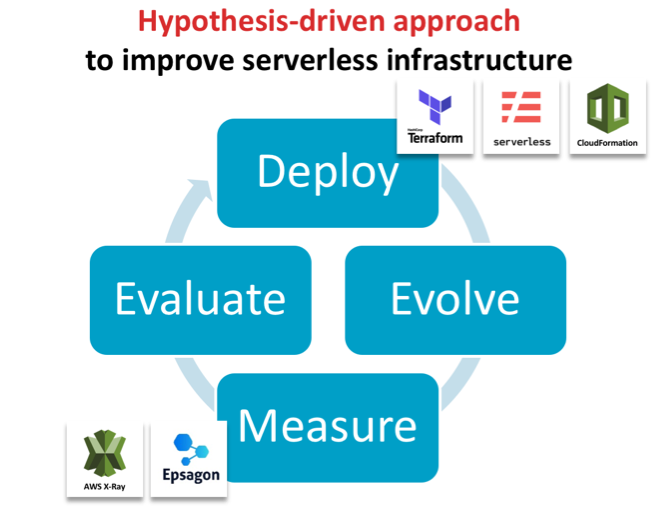
Deploy with Code as Text
To deploy easily and consistently, the serverless architecture stack needs to be fully defined through code/text. This is widely known as infrastructure as code (IaC) and comprises the full infrastructure, from the computational core in the serverless functions all the way to permissions, databases and connecting services. Frameworks such as Serverless Framework and Terraform or vendor-specific tools such as AWS CloudFormation enable this by allowing a single file to define the infrastructure used and to automatically deploy these services. This ensures that multiple versions can be deployed in isolation even though they are hosted to the same availability zone for reducing confounding factors when comparing performance.
Evolve the IaC for Hypothesis-Driven Advancements
This infrastructure file can then be modified and re-deployed to systematically test hypotheses, such as whether an algorithm is faster or a particular autoscaling group is more efficient. This idea was proposed first by James Lewis from ThoughtWorks in the context of general software architecture development, but is particularly applicable for the serverless space.
Measure Performance of the Newly Evolved Architecture
The second key element to this novel way of evolving architecture is the automatic evaluation of any newly deployed architecture without manually recording runtime or specifying interactions between services. Here, tools such as Epsagon can help in automatically detecting the workflows in architectures and analyzing their performance.
Evaluate and Iterate
In this approach, evaluation needs to keep pace with the overall process. To be effective, it is imperative to be able to identify errors and bottlenecks across the entire architecture in a timely fashion. In serverless architectures, most tools focus on the individual function rather than a full transaction from end to end. You may be made aware of a long-running function but you have to scrape logs and go through your code to perform root cause analysis. Tools such as Honycomb or Epsagon help to collide errors across multiple layers or the entire data flow.
Case Study: Improve Runtime Performance of a Bioinformatics Tool
We now describe the two key aspects (deploy and evaluate) on a practical example showcasing how it has helped improve the runtime of a serverless application. We chose the bioinformatics software framework GT-Scan, which is used by Australia’s premier research organization to conduct medical research, to improve its runtime by 85 percent.
GT-Scan was one of the first serverless architectures (Jeff Barr Blog) with a focus on burstable web services that conducts data- and compute-intensive tasks. As such, it relies heavily on all of its components to be as time- and resource-efficient as possible.
We contrast the automated approach against a previous approach in which the performance was evaluated using AWS X-Ray (AWS Public Sector Blog) and summarize our three learning outcomes:
Visualizing the Current Architecture Automatically is Important
Key to rapid architecture evolution visual feedback, especially so if only small changes to the architecture are evaluated. Hence having a visual representation of the architecture helps differentiate deployments and focuses in on differences.

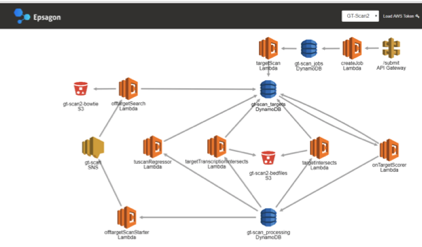
Figure 1: X-Ray view of the functional architecture vs the view of Epsagon’s automatically detected architecture
Use Invocation Count and Runtime to Identify Which Function is the Bottleneck
To identify the bottlenecks in the system, a tabular view over the runtimes of all functions is essential. This also allows us to weed out obsolete or unused functions. A similar analysis can be done for memory use.
We therefore sort by invocation count, which allows us to focus in on the most frequently used methods to target optimization efforts. We can now compare the old and new deployment side by side, by labeling one as “legacy.”
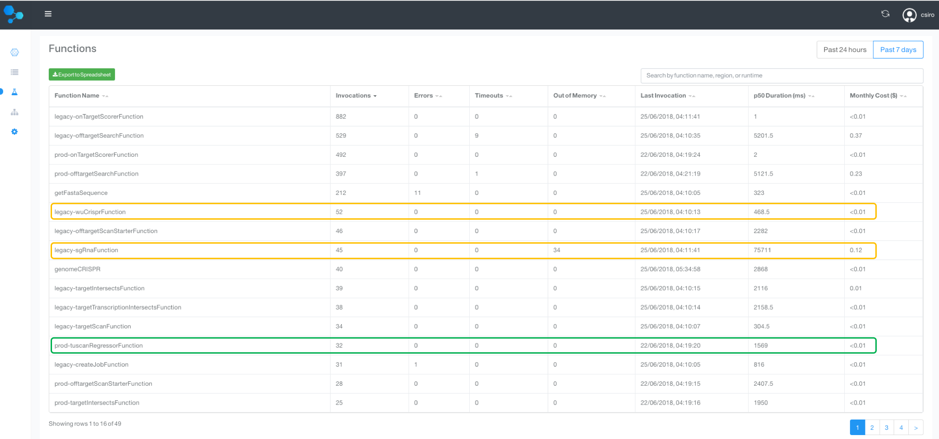
Figure 2: A tabular view of all Lambda functions and their invocation count and runtime
As seen in the functions table, the longest running function and its precursor is from the legacy deployment with its median (p50) duration :
- legacy-sgRnaFunction: 75.7 seconds
- legacy-wuCrisperFunction: 468 ms
- Total: 76 seconds
In contrast, the new tuscanRegressorFunction, which replaces the two legacy-functions, runs in just 1.6 seconds! This is a 97.8 percent reduced running time, which is 47x faster!
Assess Entire Data Flows to Target Top-Down Improvement Efforts
Complex production applications typically contain many managed services and asynchronous events, whose interplay determines the overall performance. In addition to spotting individually slow functions, it is worthwhile to evaluate entire workflows to prioritize optimization efforts to the main data flows.
For each of the GT-scan deployments, the solution identifies two flows: one comprising services watching DynamoDB and the other the API-gateway.
Comparing the two deployments at this level reveals that the main flow in GT-Scan2_legacy takes on average 97.7 seconds before the optimization, while the average runtime for the corresponding data flow in GT-Scan2_prod is 14.1 seconds—a reduction of 85.5 percent—and an overall runtime improvement of 7x!


Figure 3: Comparison between the automatically detected data flows between the prod and legacy deployment.
Visualizing the data flow of the two architectures highlights that our optimization efforts were indeed targeted at the root problem: The legacy deployment uses the two inefficient Lamdba functions, while the production deployment contains only a single more efficient function.


Figure 4: Architecture comparison of the transaction containing the difference between the prod and legacy deployment.
Bringing It All Together
Improving serverless architecture can be done systematically and efficiently by deploying the entire cloud infrastructure stack through code and using an evaluation system to automatically interrogate runtime. Specialized tools such as Epsagon can offer substantial improvements over AWS X-Ray for the evaluation step, by providing a tabular view to easily identify underperforming Lambda functions and offer an interpretable view of the architecture. Detecting data flows in the system helps prioritize optimization efforts to the main transactions of the architecture. Specialized tools help developers save time when documenting performance improvements; using hypothesis-driven evolution principles, we were able to improve the efficiency of GT-scan’s serverless system by 85 percent.
This article was co-authored by the following:
 Aidan O’Brien is the main developer on the GT-Scan2 project. He is a Doctoral research student with joint appointment at CSIRO and one of the most impactful CRISPR research facilities in Australia.
Aidan O’Brien is the main developer on the GT-Scan2 project. He is a Doctoral research student with joint appointment at CSIRO and one of the most impactful CRISPR research facilities in Australia.
 Nitzan Shapira is co-founder and the CEO of Epsagon. He is a software engineer, highly experienced in infrastructure technologies and cyber-security.
Nitzan Shapira is co-founder and the CEO of Epsagon. He is a software engineer, highly experienced in infrastructure technologies and cyber-security.
 Shannon Brown is the Senior Director of Growth of Epsagon. She is a software engineer with over 20 years of experience in software development, management, and sales.
Shannon Brown is the Senior Director of Growth of Epsagon. She is a software engineer with over 20 years of experience in software development, management, and sales.
