We live in an application-driven world. Applications power businesses, provide connectivity, and help fulfill goals and customer needs. In a competitive world, needs evolve quickly as our users demand more features — all the while expecting around-the-clock availability and reliability, whether they use smartphones, tablets, or computers.
Keeping Up With User Demands
As IT folk — irrespective of whether we are in development or operations — we need to deliver new apps and features frequently to satisfy our users’ needs or else we risk losing them to competitors or alternatives. What do we do to stay ahead? We release updates faster by:
- Organizing around small teams and delivering more agile releases
- Automating where possible (test and release processes)
- Deploying updates into production when available
However, the unfortunate truth is that frequent changes often cause errors and instability in production. We need to mitigate risk by taking a close look at our processes and practices before we hit the gas.
Preparing for fast and frequent application releases
Here are two issues (amongst many others!) that hold us back from delivering frequent updates, while ensuring reliability:
- Tedious release processes: Developers have a multitude of collaboration tools, Kanban boards, build tools, and agile practices, and can build features quickly. But once it comes to releasing these changes through QA, staging, and production, the process is more manual, ad hoc, and slow.
- Unreliability in production: Code that runs as expected in development sometimes falls short in production. Production environments are subject to limitations imposed by third-party services, regional ISPs, firewalls, and so on. They are often quite different from development and QA environments.
Collaborate on a singular goal
Development and operations teams come from different schools of thought. Devs push for change and ops drive for stability. While they both aspire to offer superior software that adds value to users, their goals are diametrically opposed! What we need is a culture where development and operations teams draw from each other’s experiences, perspectives, concerns, and continuously improve processes to build and deliver resilient applications rapidly, into the hands of their customers. This requires discipline, a sense of mutual respect, focus on the big picture, and a strong commitment toward delivering on business goals.
Streamline and automate releases
Developers enjoy streamlined processes with their collaboration and build tools to produce releases effectively. However, the operations folk do not share the same good fortune. Quite often, they get artifacts, scripts, and resources from different members of the team, and run them in sequence in order to deploy and test the application. This lack of coordination and automation greatly slows down the release process. Here’s how you can begin to address this issue:
- Critique your processes: Where do the dependencies lie? Are there any redundancies that can be consolidated? Where are the bottlenecks, what’s causing them, and how expensive are they? Start with small opportunities that can bring big improvements.
- Automate: Once you have optimized release processes, look to automating them. Time and effort saved from repetitive tasks can be put toward innovating and adding value.
Once released, monitor for quality
By automating steps within the release pipeline, you set yourself up for increasing release velocity while ensuring optimal quality. However, no amount of preparation can guarantee expected results in production. Elements out of your control — like network traffic, third-party services, local ISPs, or browsers — can potentially impact user experience or disrupt service. Many of these outages have been very public. What we need is a strong feedback loop with every release that measures metrics around performance, exceptions, and, most importantly, end-user experience. 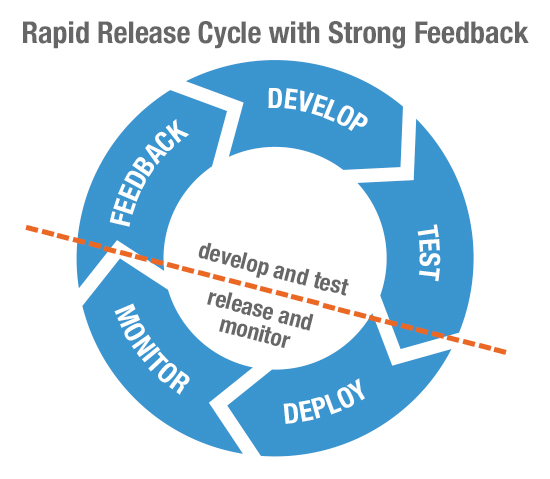 Watch out for subtle changes in performance Subtle changes can alter your application’s end-user experience, costing you customer acquisition and brand loyalty. It is death by a million pinpricks. Slow applications, JavaScript errors, and 404s are very effective in turning users away. Here is where application performance monitoring tools — like Riverbed SteelCentral™ AppInternals — help diagnose problems that degrade application performance and behavior. They monitor end-user experience from your users’ devices, trace transactions through the application tiers and infrastructure, and diagnose performance problems down to application code. These insights gives developers the visibility they need to quickly fix problems that occur in production without going through the painful process of recreating and analyzing them.
Watch out for subtle changes in performance Subtle changes can alter your application’s end-user experience, costing you customer acquisition and brand loyalty. It is death by a million pinpricks. Slow applications, JavaScript errors, and 404s are very effective in turning users away. Here is where application performance monitoring tools — like Riverbed SteelCentral™ AppInternals — help diagnose problems that degrade application performance and behavior. They monitor end-user experience from your users’ devices, trace transactions through the application tiers and infrastructure, and diagnose performance problems down to application code. These insights gives developers the visibility they need to quickly fix problems that occur in production without going through the painful process of recreating and analyzing them.
Monitor end-to-end application performance continuously
Monitor your application for performance and behavior in production. Make this an ongoing activity during peak and off-peak hours alike. A keen insight into your application and infrastructure health can reveal snags that would otherwise go unnoticed. You really want to look for symptoms that compromise end-user experience, such as:
- How are my servers and infrastructure performing at current capacity?
- How are users in one location faring compared to others?
- What parts of my application — internal or third party — impact performance?
Diagnose problems with performance monitoring tools
Diagnose where and why these symptoms occur. Are they because of poor code, network conditions, server capacity, or third-party services? What is the context in which these issues occur? Which code segment, SQL query, or app component is at fault? You will be able to package up everything the development team needs to fix the problem and prevent it from recurring. Many of these tools, like AppInternals, allow developers can view this information from within IDEs like Eclipse and Visual Studio.
In conclusion, aim for continuous improvement
Particularly in the case of rapid release cycles, constant monitoring is a necessity. Identify symptoms in runtime — in QA and production — and quickly fix them using diagnostic data captured by your tools. This will keep the backlog low, your IT team productive and focused delivering new features, and your customers happy.
