DevOps is all about increasing the feedback loop from idea to customer and back again. Tremendous gains have been achieved in automation and tools to drastically reduce the amount of manual labor involved in progressing down the release pipeline. But mission-critical applications in a highly competitive market cannot afford to go down. Complex applications, environments and infrastructure increase risk, which can cause failure.
The failure rate of production deployments is still too large. Studies show that the average cost of a production outage is roughly $5,000 per minute, while the average cost of a critical application failure per hour is $500,000 to $1 million.
Why so much failure? All too often we’re still seeing a lack of consistency across the release pipeline. Many times the provisioning and deployment processes are very different at the opposite ends of the pipeline. But by shifting left the operations concerns, you can achieve much more success in production.
Understanding How to Shift Left
The term “shift left” refers to a practice in software development in which teams focus on quality, work on problem prevention instead of detection, and begin testing earlier than ever before. The goal is to increase quality, shorten long test cycles and reduce the possibility of unpleasant surprises at the end of the development cycle—or, worse, in production.
Shifting left requires two key DevOps practices: continuous testing and continuous deployment. Continuous testing involves automating tests and running those tests as early and often as possible, along with service virtualization to mimic unavailable systems. Continuous deployment automates the provisioning and deployment of new builds, enabling continuous testing to happen quickly and efficiently.
The first and most obvious way to shift left operations is to work side by side with development in creating the deployment and testing processes. Failures observed in production often are not seen earlier in the life cycle. Many times these failures can be attributed directly to differences in deployment procedures. Development may create its own deployment procedures that are very different from those used by operations for production. Sometimes production procedures are much more manual and may even use different tooling. Operations and development need to take ownership in building standard deployment procedures. The deployment process is then practiced potentially hundreds of times in test environments before reaching production. You then have much more confidence that the production deployment will be successful.
Another way to reduce the failure rate is to make all environments in the pipeline look as much like production as possible. This is almost impossible using traditional provisioning processes. Production environments usually are much heavier and detailed than are needed by development. But by using cloud and pattern capabilities, you can get much closer.
The ability to use patterns to define consistent environments eliminates the failures that occur simply by configuration inconsistencies. This again requires operations and development to work together in creating the provisioning process so developers create their test environments the same way they are created in production. Using IBM UrbanCode as an example, this can be done by connecting UrbanCode Deploy to an automated self-service provisioning system such as OpenStack HEAT or IBM Cloud Orchestrator connected to OpenStack.
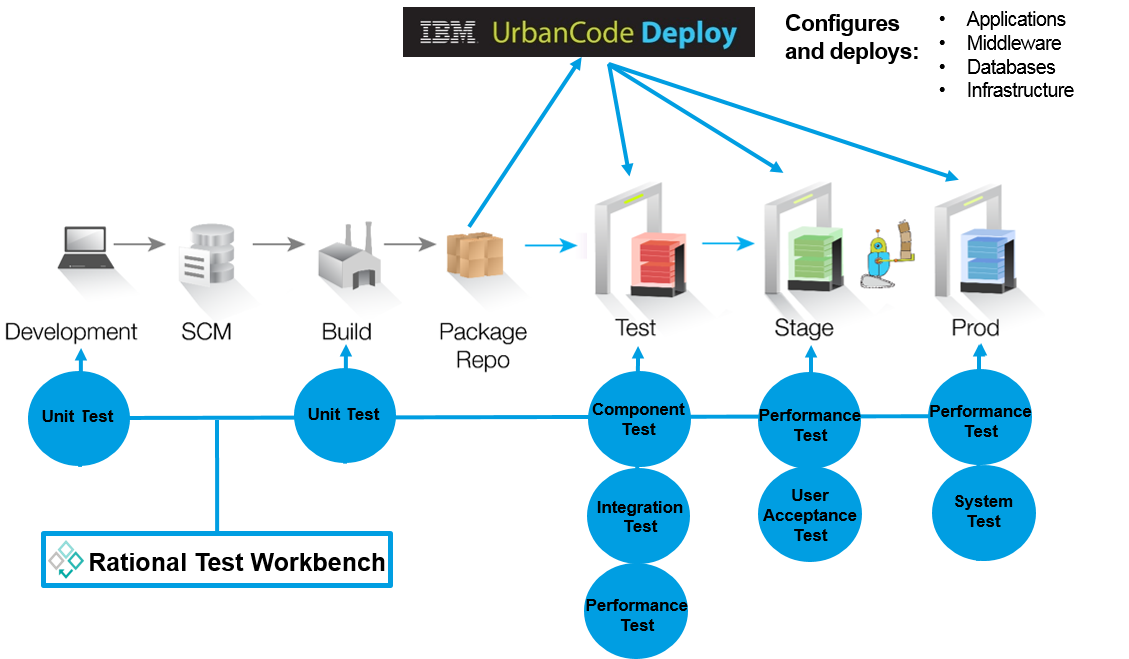
These standard patterns can be used to create environments for all stages of the pipeline. And by using cloud capabilities you can deprovision these environments as fast as you can create them. This also allows the enterprise to have confidence in their environment patterns. They are tested on a daily basis and, therefore, operations can feel confident that testing is done on production-like environments.
No one wants to experience production failures—and it is in everyone’s best interest to do all they can to prevent them. At the root of DevOps is the removal of those silos between development and operations. By applying these shift left operations principles you are well on your way to reducing your failure rate.
The ingredients to make shift left are real and available: automated testing and deployment tools, service virtualization technology, agile practices and cloud environments. The main obstacle that remains is the mindset of delivery organizations. Learn more from the newly updated Application Deployment and Release for Dummies ebook to find out more.
About the author / Dr. Darrell R. Schrag

Dr. Darrell R. Schrag (@devopsdrs) is an experienced software lifecycle consultant specializing in the IBM cloud solution, helping customers establish their cloud strategy across the enterprise. He’s focused on implementing continuous delivery of software applications through the delivery pipeline incorporating cloud and provisioning solutions. He’s experienced in helping clients transition to “born on the cloud” applications utilizing microservices to take advantage of a flexible and nimble cloud platform.
