Or How I learned to stop worrying and love the auto-remediation
These days StackStorm – and other approaches to auto-remediation and event driven automation more generally – are getting broadly adopted.
Everyone from Facebook through Netflix and WebEx (yeah users!) are not just better “managing” their 2am pages (although that’s cool too PagerDuty) – they are exterminating them.
And as they adopt StackStorm for remediation inevitably a discussion emerges about monitoring vs. fixing. Why?
At some level it is because of the excellent work that has been done recently in response to monitoring sucks. Thanks Sensu, thanks SignalFX, NewRelic, DataDog, AppDynamic, Splunk, the entire ELK stack, and the other >150 monitoring solutions I’ve left out.
But at another level it is because of OODA tells us that all that observing and orienting is only as good as the decisions and actions you take.
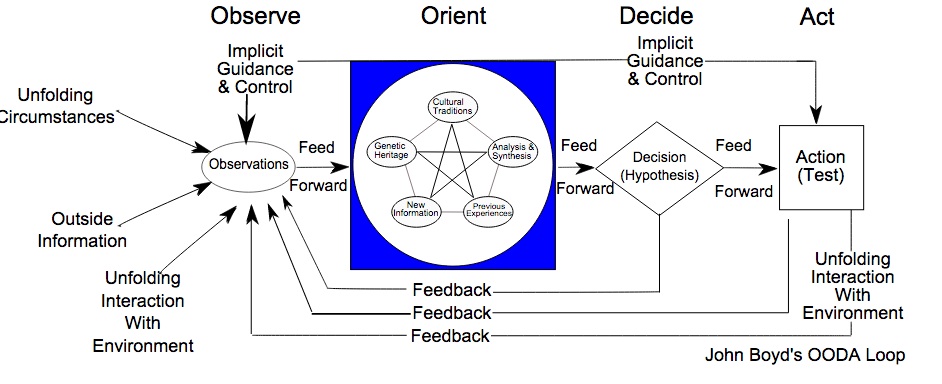
The thing is, even though folks gradually are coming to realize that good event-driven automation INCLUDES the D in it – and does not purely rely on the smarts of monitoring since with event driven automation it is possible to run a routine that validates events before acting upon them, most people still miss the fundamental insight of ODDA. And it is an insight that is crucial especially if you, like those users above and many folks in the world of active cyber-defense, are going hand to hand with smart actors and otherwise are in a world in which what goes wrong is changing.
Here is that perhaps non-intuitive insight that, again, I’ve learned from folks that live the OODA against tricky actors (human and the entropy of scale and creeping complexity) everyday:
Make your false positives and the creation and control of your actions cheap and you can move fast to fix, way before a root cause analysis (RCA) would typically have completed.
Some of the tips that even the wikipedia on ODDA repeats for actual war fighters utilizing the ODDA is “embrace the chaos” – don’t wait to know what is happening before your act because the pace of your actions is itself a key determinate in whether you triumph or not.
One way to think of it is that you have a budget from O through A and the total of those steps is your Mean Time To Recover (MTTR).
If you spend all of your MTTR budget on O and O then your D and A will be too little, too late.
Returning to the world of infrastructure and DevOps – here are some drivers pushing us all to focus more on the D and the A and to obsess less over the O and the other O:
- Docker and containers and cloud itself. Now compute can be ephemeral (sometimes). Same deal with lots else that can be software defined. Even storage! (hi Nexenta ;))
- Imperative stuff exposed via APIs and declarative systems. Yes, this is a StackStorm plug. U R surprise? Check it – when Netflix knows that there is a happy API there that will do the care and feeding of their Cassandra reliably even when AWS is doing an AWS entropy dance, they can obsess slightly less over RCA and more over making sure StackStorm has the resources it needs to fix and fix and fix and fix again before any of us start noticing Netflix acting strange. (You want to see how Netflix auto-remediates their Cassandra environment? Hands on tutorial with code samples here. )
- Infrastructure as code. Without infrastructure as code the cost of changing the integrations and automations that live inside of event driven automation can be astronomical. In the world of legacy run book, needing to tweak an automation to respond to RIAK burps instead of Cassandra burps is a bunch of perfectly performed mouse clicks (intentional irony) OR a nice set of proprietary code. In our world – all the glue, the rules, and the workflows are themselves just code.
- And – sorry to extend the point but this is crucial – the code is YAML or maybe just whatever scripts you have lying around or maybe the configuration management system you have already deployed. A system like StackStorm can start with the bunch of scripts you already have – those that, along with a lot of human activity comprise your D and A – and ingest them. (yum, yum, Java, Python, Bash and Ruby) And then those scripts, those configuration management systems, all of it plus your monitoring and more are there for you to tie into a system that automates the entire OODA loop. And then the good stuff happens because you have incredibly fast MTTR (and even proactive MTTR, preventing the outage before it occurs).
- Workflow. With workflow you can see what is happening. Especially if exposed via FLOW (another pitch, I know). But not just FLOW and not just StackStorm. The return of workflows is real and widespread. Read a good overview of many of the projects published this Spring on DevOps.com here.
- Feedback loop Maybe goes without saying – but once you automate your entire OODA and have it as code – you can iterate better on it. And that’s especially true if you take every single transaction from O through A and log it. How could you do it? Don’t worry, works out of the box with StackStorm. Or just set up a unique execution ID on every event and pass that through to each interpretation of the event via your rules engine and then keep that ID as you get the multiple workers in your highly resilient workflow system to start executing and then use that ID as well when doing post-hoc reporting; and don’t forget the APIs, GUIs and CLI as well. Or just grab StackStorm – it is open source after all.
In conclusion – OODA is a great frame of reference. However we in DevOps seem to be overly obsessed with the O and the O whereas those that first articulated OODA – those folks using OODA in combat – focus at least as much on D and A.
To me this not only implies do the D and A faster and better (via automation) – it also implies that we may not need yet another monitoring project. The world can stop reinventing monitoring for now, we have 157 projects at least.
Instead – let’s turn to figuring out how to lower the cost of false positives and the cost of automating ever changing environments – so we can iterate faster and faster – staying farther ahead of the entropy monster and the real monsters trying to steal and corrupt what we build.
If you like this sort of discussion and want to learn how Facebook, WebEx, LinkedIn, and coming up in a few weeks – Netflix is doing it – you may want to join the Event Driven Automation Meet-up which I help organize with my friend Brian Sherwin, LinkedIn SRE and author of the remediation system Nurse. Netflix has been kind enough to agree to host the next one at their new offices nearby to their old offices in the South Bay here in the Bay Area. Even if you don’t think you can make it, we try to share content via this meet-up and whenever possible we also stream the sessions.
Also, at the risk of being “too vendory”, StackStorm is the leading open source project and company dedicated to event driven automation and specifically auto-remediation – we stormers and the broader StackStorm community are here to work with you, to support you, to get you good code and to pick your brain and to ask for your PRs, feedback, integrations and automations (aka packs). So grab some code, join our Slack based community, and let’s get going.
