As organizations add machine learning (ML) to their workflows, it’s tempting to try to squeeze model creation and deployment into the existing software development lifecycle (SDLC). However, ML is fundamentally different than traditional applications, and it’s important to account for that in a new, unique process called the machine learning development lifecycle.
We have identified five challenges every organization should keep in mind as they begin to support ML development.
Making Heterogeneity Work
Machine learning is successful when the right tool is selected for a given job. Depending on the use case, a data scientist might choose Python, R, Scala or another language to build one model, and another language for a second model. Within a given programming language, there are numerous frameworks and toolkits available, adding complexity to versioning and consistency.
For example, TensorFlow, PyTorch and Scikit-learn all work with Python, but each is tuned for specific types of operations, and each outputs a slightly different type of model.
ML-enabled applications typically call on a pipeline of interconnected models, often written by different teams using different languages and frameworks.

For example, a public relations firm looking to identify news and reports critical of one of its customers might use the following pipeline:
- Extract all text from hundreds of scanned documents with an Optical Character Recognition (OCR) model.
- Identify the languages of that text with a language-identification model.
- Translate the text to English.
- Prepare the text for sentiment analysis with a vectorization model that turns English text to numbers.
- Use a sentiment analysis model to score the text.
Planning for ML Iterating
In machine learning, your code is only part of a larger ecosystem—the interaction of models with live, often unstructured or unpredictable, data. Interactions with new data can introduce model drift and affect accuracy, requiring constant model evaluating, tuning and retraining.
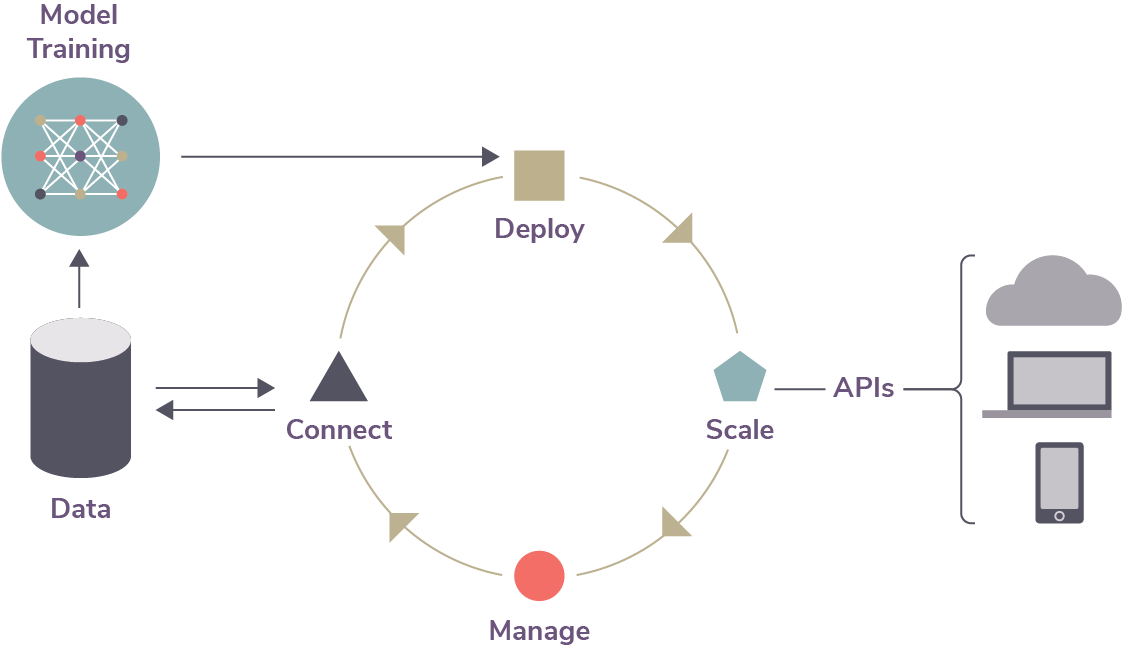
As a result, ML iterations are faster and more frequent than traditional app development workflows. This places greater demands on versioning and other operational processes and requires a greater degree of agility from DevOps processes, tools and staff.
Organizations interested in adopting ML-enabled applications need to be prepared to handle the burden of iteration without breaking the budget or introducing needless infrastructure tasks.
Developing the Right Infrastructure
The model training process typically involves multiple instances of the following:
- A long and intensive compute cycle.
- A fixed, inelastic load.
- A single user.
- Concurrent experiments on a single model.
After deployment, models from multiple teams enter a shared production phase characterized by:
- Short, unpredictable compute bursts.
- Elastic scaling.
- Many users consuming many models.
Operations teams must be able to support both the training and deployment environments on an ongoing basis, because it’s a continuous lifecycle. Selecting the right infrastructure for that job is complicated by a rapidly evolving tech stack, from the increasing variety of processors available for ML workloads to advances in cloud-specific scaling and management, to a never-ending stream of new data science tooling.
It’s important to future-proof your ML program to ensure a tool or framework you use today does not lead to lock-in or worse—obsolescence—down the road.
How Will You Scale?
To address the unpredictability of ML workloads and the premium on low latency, organizations must build compute capacity to support substantial bursts.
There are three typical architectural approaches, each with benefits and drawbacks:
Traditional Capacity Planning: In a traditional architecture, operations reserve compute resources capable of scaling to maximum anticipated demand.

Pros:
- Reserved capacity is always available
- Easy to administer
Cons:
- Extreme waste and cost
- Unanticipated demand can exceed the capacity
Elastic Scaling: Standard elastic scaling designs for a local maximum, scaling machines up and down based on step functions.

Pros:
- Cost improvements over traditional architecture
Cons:
- Inefficient hardware utilization
- Difficult to manage heterogeneous workloads on the same hardware
- Slightly more management overhead than traditional architecture
Serverless: Serverless architecture approaches spin up models as requests come in.

Pros:
- Significantly improved hardware utilization
- Dramatically lower costs
- Easier to run and scale different types of workloads on the same machines
Cons:
- Substantial administrative overhead for custom-built, on-prem solutions
- Some third-party services without extensive APIs and reporting provide limited explainability
- Performance tuning to meet latency
Architects can implement any of the three approaches in the cloud or in a physical datacenter, though elastic scaling or serverless approaches requires far more effort to manage in-house.
Trusting the Results with Auditability and Governance
Explainability—understanding why models make given predictions or classifications—is an essential part of ML infrastructure and the lifecycle. Equally important and often overlooked, however, are the related topics of model auditability and governance—understanding and managing access to models, data and related assets.
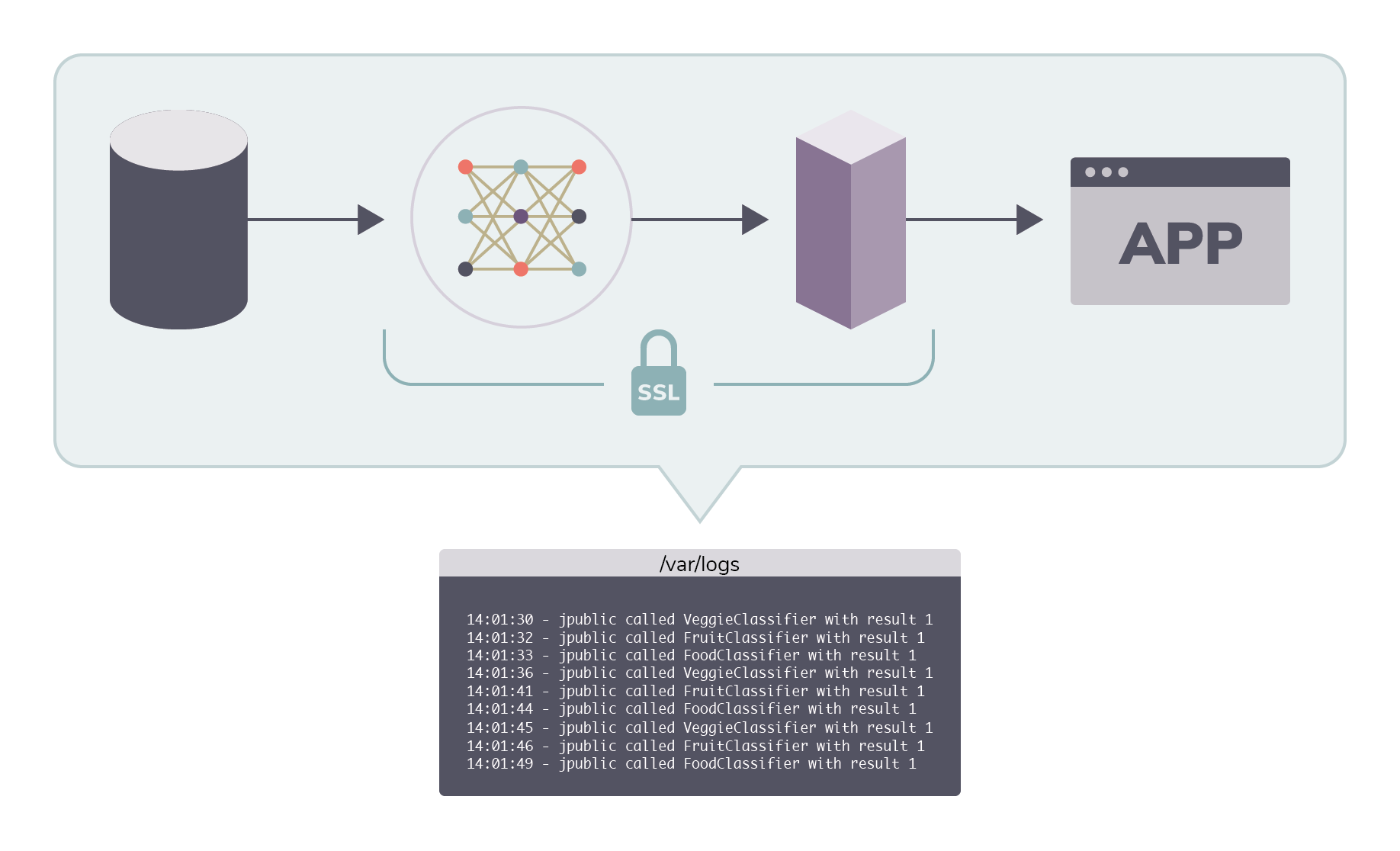
To make sense of complex pipelines, a multitude of users and rapid model and data iteration, deployment systems should attempt to identify:
- Who called which version of which model.
- At what time a model was called.
- Which data the model used.
- What result was produced.
Thinking about and planning for these five challenges before beginning a machine learning initiative is a good place to start to ensure a valuable return from your investment.
To learn more about containerized infrastructure and cloud native technologies, consider coming to KubeCon + CloudNativeCon NA, November 18-21 in San Diego.
