Gremlin this week announced it will integrate its hosted chaos engineering service with continuous delivery platforms starting with the open source Spinnaker project developed by Netflix.
Chaos engineering traces its roots to a resiliency testing philosophy that posits applications should be able to keep functioning regardless of any service or infrastructure failure. Most IT organizations, however, don’t have the expertise required to build the tools required to testing resiliency based on those “chaos monkey” principles that randomly turn services off to see if an application fails.
Matt Jacobs, principal software engineer for Gremlin, said the decision to integrate with Spinnaker is being driven by the need to infuse chaos monkey resiliency testing directly into the application development and deployment pipeline at a more granular level. That capability is now a bigger requirement than ever because as organizations embrace microservices to build the next generation of cloud-native applications, it’s simply not possible for DevOps teams to manually track every dependency, he said, adding resiliency testing based on chaos monkey principles is just another type of testing that should be automated as part of a larger continuous integration/continuous delivery (CI/CD) platform to ensure an application doesn’t fail completely.
Integrating with a Spinnaker project that has drawn support from Google, Microsoft and Oracle provides the easiest path to achieving that goal. Spinnaker is also now a core element of a Continuous Delivery Foundation led by Alibaba, Anchore, Armory, Autodesk, Capital One, CircleCI, CloudBees, DeployHub, GitLab, Google, Huawei, JFrog, Netflix, Puppet, Red Hat, SAP and Snyk.
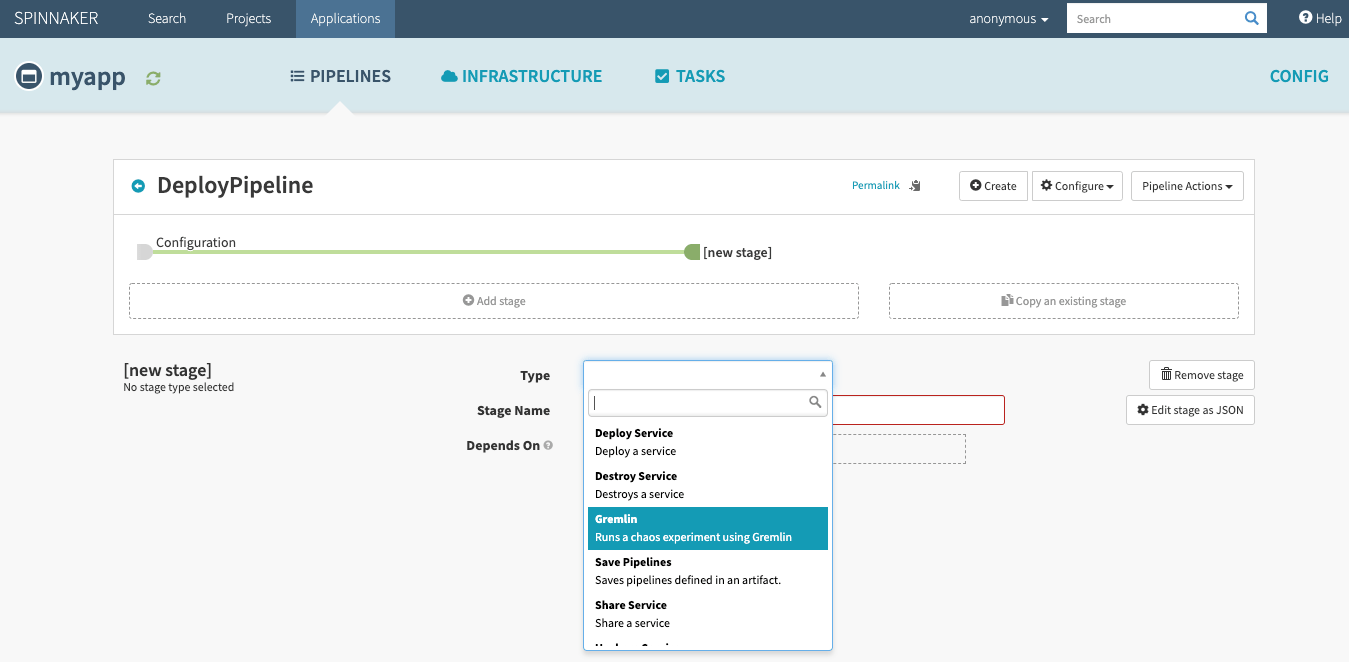
The Gremlin service is accessed via a user interface and comes in two forms: a free edition and an enterprise edition, which comes with support from Gremlin. While the concept of chaos monkey testing has been around for some time among the most advanced DevOps practitioners, enterprise IT organizations, which tend to be more conservative when it comes to introducing anything that might deliberately break their applications, will need a considerable amount of hand-holding. Gremlin is designed to learn the application environment in a way that introduces chaos in a controlled fashion before an application is deployed in a production environment.
On the positive side, resiliency testing based on chaos monkey principles tend to accelerate the rate at which IT staff learn how an application has been architected, said Jacobs. That can prove especially invaluable when training new members of a DevOps team, he noted.
Ultimately, the decision to embrace resiliency testing comes down to how proactive an organization wants to be when it comes to preventing downtime. When mission-critical applications are offline, there is a direct impact on the amount of revenue an organization generates. There are plenty of functional and performance testing tools, but the real difference between having an issue and a catastrophic event that requires DevOps teams to get out of bed in the middle of the night often comes down to how truly resilient any given mission-critical application really is.
