I recently took some time out from reading the Internet to read a very specific piece of research I found on the Internet from IDC – its “DevOps and the Cost of Downtime” to be exact. Sponsored by AppDynamics, this fascinating read included a variety of statistics that are helpful in understanding the impact of (or a lack of) DevOps on organizations given certain financial and competitive impacts.
I won’t bore you by repeating what you can so easily read yourself, but I have pulled out a few key stats that are worthy of further investigation – that of the failure of stability on the business and the predicted increase in deployment frequency.
- The average hourly cost of an infrastructure failure is $100,000.
- The average hourly cost of a critical application failure is $500,000 – $1M.
- The average number of deployments per month is expected to double in 2 years.
Interestingly, that prediction on deployment frequency is a good thing and carries with it the possibility of making sure the costs associated with the other two rarely (if ever) happen.
We’ve already gotten to a point where “speed” with respect to DevOps is effectively equivalent to “time to market”. But there’s another measure of “speed” that’s just as critical, particularly when we apply it to maintaining stability in the infrastructure. That measure is MTTR (Mean Time to Resolution). This measure is very important when you consider that 60% of production failures are caused by human error or lack of automation according to research from ZeroTurnaround. A goal of DevOps, then, should be to reduce that number as much as possible and introduce more stability into the environment. Frequency of deployment can actually be of assistance in realizing that goal.
So how does frequency of deployments help do that?
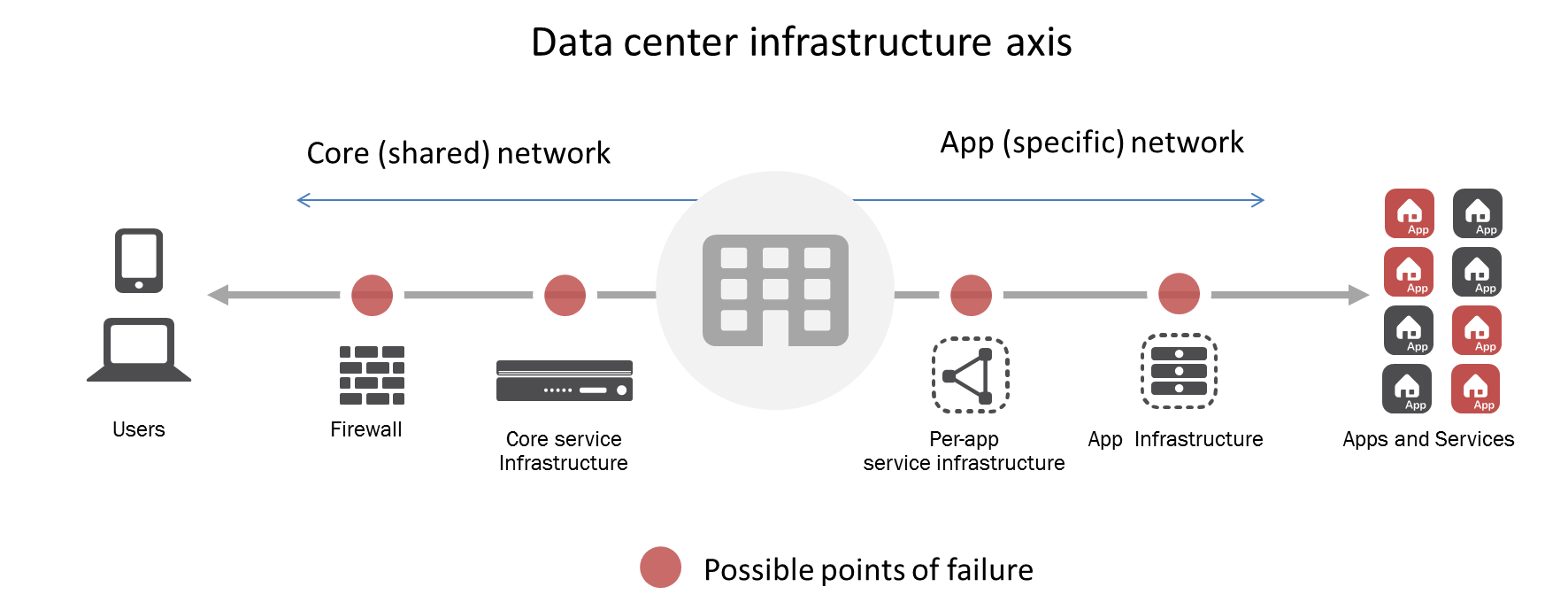 First let us consider the number of possible points of failure that might cause downtime – both in the application and core network infrastructure. Then let us consider that each of those possible points of failure also have multiple potential causes of failure. A single service in the logical critical data path within the core service infrastructure, for example, can easily cause “downtime” that, in the case of IDC, would be characterized as “infrastructure failure” and run a tab of $100K per hour.
First let us consider the number of possible points of failure that might cause downtime – both in the application and core network infrastructure. Then let us consider that each of those possible points of failure also have multiple potential causes of failure. A single service in the logical critical data path within the core service infrastructure, for example, can easily cause “downtime” that, in the case of IDC, would be characterized as “infrastructure failure” and run a tab of $100K per hour.
If that application is a critical business application, the tab runs much higher per hour.
Obviously the speed with which we restore stability (service) in such an event is a factor in the overall impact to the business.
This is where DevOps comes in and where operationalization can play a significant role in mitigating the impact of downtime by aiding in faster time to resolution.
Consider that one of the most difficult tasks in the network is not provisioning or configuration, but troubleshooting. To be fair, troubleshooting in app dev, too, is one of the more time-consuming and frustrating tasks, consuming 75% of a developer’s time (according to research from InitialState). That’s close to the 65% of network engineers who are dedicated to “break and fix” tasks, who spend their time troubleshooting network issues up and down and all along the network stack. Needless to say, if you just deployed ten or fifteen different configuration changes splayed across the core and per-app service infrastructure and suddenly something is “wrong”, it’s going to take some time to figure out exactly which configuration change caused the problem in the first place.
The relationship between number of changes and frequency of deployment is no secret; if you’re deploying changes more frequently then it’s likely there are fewer of them. With an average sprint cycle of 3-4 months, the amount of change is logically not going to exceed that of a cycle that takes 12-18 months. The same holds true for the infrastructure; more frequent deployments should mean fewer changes).
Logic (and math) tells us that the fewer lines of code and configuration that have changed, the less time it should take to identify the culprit should something go wrong, thereby hastening the time to resolution. Assuming that an agile, frequent deploy rate results in fewer changes to the environment it stands to reason that this approach should also reduce both the number of failures and the time to resolve any that do crop up. Frequency is a significant factor in reducing failures by increasing its overall stability.
This is backed up anecdotally by Puppet Labs findings in its “State of DevOps” in which organizations adopting a DevOps approach reported 50% fewer failures and a 12x improvement in time to resolution. That’s stability at work and it’s driven in part by the frequency of deployments and its positive impact on MTTR.
So let’s apply this approach (and logic) to the rest of the services along the critical data path in the data center infrastructure, i.e. apply it to application services like caching, web application security, load balancing, identity management and application access control. Automation to reduce misconfiguration caused by human error and smaller, more frequent changes that enable a faster time to identity the inevitable issues that will be introduced. No methodology or approach is going to completely eliminate errors, after all. There’s a limit to how perfect we can get and it’s pretty much a Zeno’s Paradox kind of problem. While we keep solving current issues, more config and code is being deployed that is statistically likely to contain yet another error, and so and so forth.
But the goal is not necessarily to eliminate all errors (though that’d be nice, it’s simply not practical and it’s the primary reason why our goals for uptime are called “5 9s” and not a “1 with two zeros”) it’s to reduce the number of errors and their impact on downtime. And that is something we can achieve without running afoul of Zeno and his paradox.
Smaller, more frequent deployments can result in a more stable environment in which downtime is reduced to a level consistent with acceptable risk.
DevOps, whether applied directly to infrastructure or not, will play a role in improving its stability which in turn has a direct and very real impact on the business by eliminating (some) downtime thanks to more frequent deployments.
