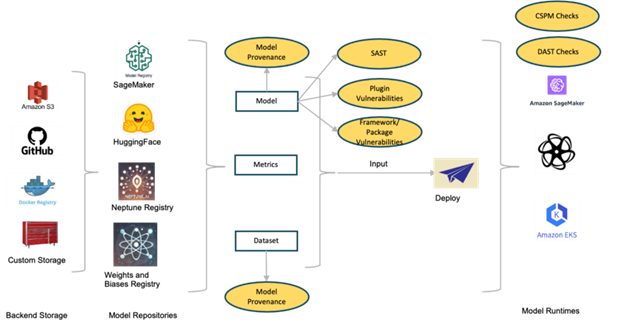
Enterprise applications that rely on large language models (LLMs) are rapidly evolving, introducing new security risks. Traditional application security, or AppSec, still plays an important role in securing AI/ML applications and ensuring responsible outputs. At the same time, there are new AI/ML application risks that will require new approaches.
AppSec measures focus on securing source code, third-party dependencies and runtime environments. For example, third-party software libraries and services such as npm, GitHub or maven repos can introduce attack risks. Developers also employ toolchains for building and packaging software that includes proprietary and third-party components. These toolchains need to be secured, as does the original business-specific logic that the enterprise develops. Applications deployed in production environments use dependent services for messaging, network gateways, storage, etc. These environments as a system, must also be protected.
To meet these security needs, AppSec teams invest in point security solutions such as SAST, DAST, SCA, Endpoint Security, RASP and Perimeter Security. These tools are supplemented by management platforms such as cloud security posture management (CSPM), application security posture management (ASPM) and cloud native application protection platform (CNAPP).
New Security Challenges for AI/ML Applications
While various AI/ML application risks are like traditional application security risks and can be protected using the same tools and platforms, runtime security for the new models requires new methods of securing the applications.
For example, LLM models trained with proprietary data expose new data security and privacy risks. Datastores have typically been protected with role-based access control (RBAC), using the access controls to segregate confidential and proprietary information from public data. However, AI models store the data in a form that does not allow applying traditional data controls like RBAC, creating the risk of private data being included in LLM output. Instead, the business should create an additional security layer to detect and protect proprietary or personally identifiable information (PII) in the LLM responses.
Another new risk is the possibility of model theft and denial of service (DOS) attacks on the freeform query interface used to request responses from the LLM. Preventing this requires additional security measures to validate the content and volume of queries, as well as the data that is contained in the responses.



The utilization of open-source LLM models presents risks due to the lack of provenance in their training data. These models can produce inaccurate results and can be deliberately poisoned. When combined with AI agents for automation, these inaccurate results and poisoned models can lead to significant business risks.
The Open Web Application Security Project (OWASP) offers guidance here with their OWASP Top 10 for LLM Applications. Some of the risks included on this list can be mitigated with traditional AppSec tools and platforms, while others require new LLM-specific techniques.
OWASP LLM security vulnerabilities that can be managed with existing AppSec approaches:
- Improper Output Handling: Using automated execution based on LLM output or plugins to automate based on LLM output can result in privilege escalation, remote code execution and XSS, CSRF and SSRF in browsers. Modeling threats using a zero-trust approach and using application security verification standards can mitigate this vulnerability.
- Data and Model Poisoning: Data poisoning can occur inadvertently or maliciously by providing incorrect data to pre-train, fine-tune or embed data used in the model. Validating data provenance used for training, vetting data vendors, controls for accessing only validated data sources, storing user-supplied information in vectors and not using it for training are some of the techniques that help mitigate model poisoning.
- Supply Chain Vulnerabilities: Traditional supply chains focus on code provenance, while the LLM supply chain extends the focus to models and datasets used for training. Fine-tuned models with LoRA or PEFT add to the supply chain risks. Risks include poisoned crowdsourced data or vulnerable pre-trained models, causing the model to perform with incorrect or skewed results, which becomes an advantage for threat actors. Vetting a comprehensive bill of materials, including datasets, base models, fine-tuning add-ons and licensing checks, along with red teaming testing, will mitigate the vulnerabilities. Industry should move toward automated validation and verification mechanisms to better manage supply chain risks.
- Unbounded Consumption: When an LLM allows users to conduct excessive and uncontrolled inferences, it leads to risks of model denial of service (DoS), economic loss and model theft. Rate limiting, input validation, throttling and resource allocation management are among techniques that can be used to counter vulnerability.
- Excessive Agency: The unmanaged ability to interface with other systems and take actions in response to prompts, leading to unintended consequences based on hallucinations, compromised plugins or poorly performing models. Minimizing extensions and their functionality, implementing authorization mechanisms and sanitizing inputs and outputs can mitigate excessive agency.
- System Prompt Leakage: Prompts to LLMs are not intended to be secrets as they could be stored and monitored for refining the system. Prompts could include sensitive information for a more accurate response from LLM that is not intended to be discovered. This causes the risk of exposing secrets, internal policies or disclosure of user permissions and roles. Implementing guardrails outside LLM for input validation, removal of secrets in prompts and implementing agents/plugins with least privilege to perform their tasks can mitigate risks in system prompt leakage.
LLM security vulnerabilities requiring new approaches:
- Prompt Injection: Prompt injection involves manipulating model responses through specific inputs to alter behavior. These can be direct, i.e., user input, or indirect, i.e., an external source such as a website as input. Multimodal AI may also be susceptible to cross-modal attacks. This can lead to exfiltration of private data, deletion of proprietary data or intentionally incorrect query results. Using model behavior constraint rules, input and output filtering, segregating and identifying external content and performing adversarial attack simulations can help mitigate the vulnerability.
- Sensitive Information Disclosure: Applications using LLMs risk exposing sensitive data through their output. This data can include personally identifiable information, sensitive business data or health records based on training data and input prompts. Data sanitation techniques in training data, input validation, segregating data sources, homomorphic encryption and enforcing strict access controls can mitigate disclosure of sensitive data.
- Misinformation: LLMs can seem authoritative even though they include hallucinations, and bugs in generated code can be hard to detect, causing problems downstream when LLM output is used without proper validation. There is no authoritative way to ensure the robustness of information from LLM. A combination of human oversight, education of users on limitations of LLMs and automatic validation in high-risk applications can mitigate the effects of misinformation.
- Vector and Embedding Weakness: Retrieval Augmented Generation (RAG) is a technique that enhances the contextual relevance of responses by providing additional information stored as vectors and embeddings as part of a prompt to LLM. This can lead to unauthorized access, data poisoning, data leaks or behavior alteration without proper controls on storage and usage of vector embeddings. Implementing robust data validation of inputs, permission and access controls of embeddings and validating embeddings for cross-dataset pollution can mitigate this vulnerability.
Other resources provide additional useful guidance and resources on securing AI/ML applications. The MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) is based on real-world attack observations and can be mapped back to many of the techniques for exploiting the vulnerabilities that are detailed in the OWASP Top 10. These are complemented by new projects such as Garak, an open-source effort to provide a comprehensive security posture for AI applications.
Conclusion
Extending an AppSec program to AI/ML applications involves adapting and enhancing traditional practices while addressing new challenges related to AI systems. By building on proven methods and integrating AI-specific security measures, enterprises can confidently secure their AI/ML workflows.
Model deployment process after training: