At the KubeCon + CloudNativeCon North America conference this week, Mezmo launched an Observability Pipeline platform that promises to make it simpler to manage, enrich and correlate machine data.
Previously known as LogDNA, Mezmo is expanding the scope of its reach to add the ability to augment and analyze data on top of its core log management platform. Over time, that capability will be extended to add support for metrics and traces using the open source OpenTelemetry agent software.
Mezmo CEO Tucker Callaway said the goal is to provide a framework for centralizing the flow of observability data that is now being generated by a wide range of sources across a DevOps workflow. It’s clear that DevOps teams require a means to enrich and correlate high volumes of data in motion that goes beyond simply pre-processing so it can be stored more cost-effectively, he added.
The Mezmo Observability Pipeline achieves that goal by ensuring the right data is flowing into the right systems in the right format for analysis, noted Callaway.
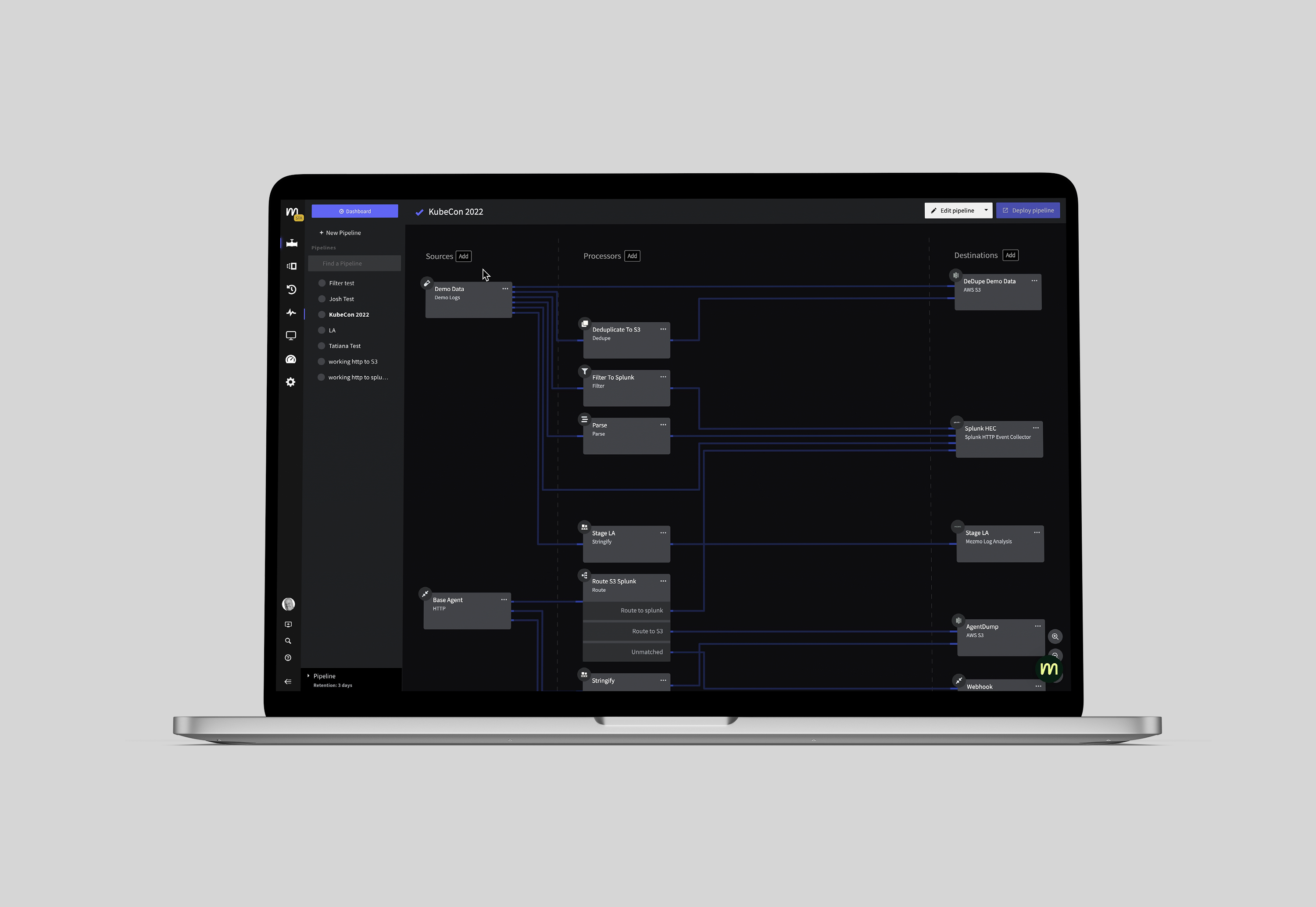
As the volume of data being collected by DevOps teams continues to dramatically increase the need to embrace a set of DataOps best practices is becoming more apparent. DataOps has emerged recently to describe a set of data engineering practices that applies many DevOps principles to the way data should be managed. Mezmo’s Observability Pipeline aims to make it simpler to apply DataOps best practices specifically to the data collected by DevOps teams.
Of course, each DevOps team will need to decide for themselves how much data they want or need to store long term. However, increasingly DevOps teams are holding onto data much longer as IT environments become more complex, noted Callaway. That creates a need to more efficiently analyze as much data as possible and store it more cost-effectively, he said. Those twin goals, however, often create a physics problem in the sense that they can be diametrically opposed.
In the longer term, it’s not quite clear how much DevOps teams are embracing observability. Most DevOps teams make use of monitoring tools that enable them to track a set of pre-defined metrics. Observability platforms promise to make it easier for DevOps teams to query a wide range of data types to discover potential issues before they disrupt an IT environment. The challenge is that many DevOps teams may not know what queries to form to discover those issues. It’s likely that, over time, machine learning algorithms will be increasingly applied to observability data to make it simpler to surface potential issues.
In the meantime, however, the need for DevOps teams to find ways to manage all the data being generated by multiple types of applications is becoming a higher priority. In fact, in the absence of any meaningful way to manage all that data, the benefits of an investment in an observability platform is likely to be limited, at best.
