OverOps has allied with GitLab to integrate a tool that analyzes code at runtime to identify issues with a continuous integration/continuous delivery (CI/CD) platform.
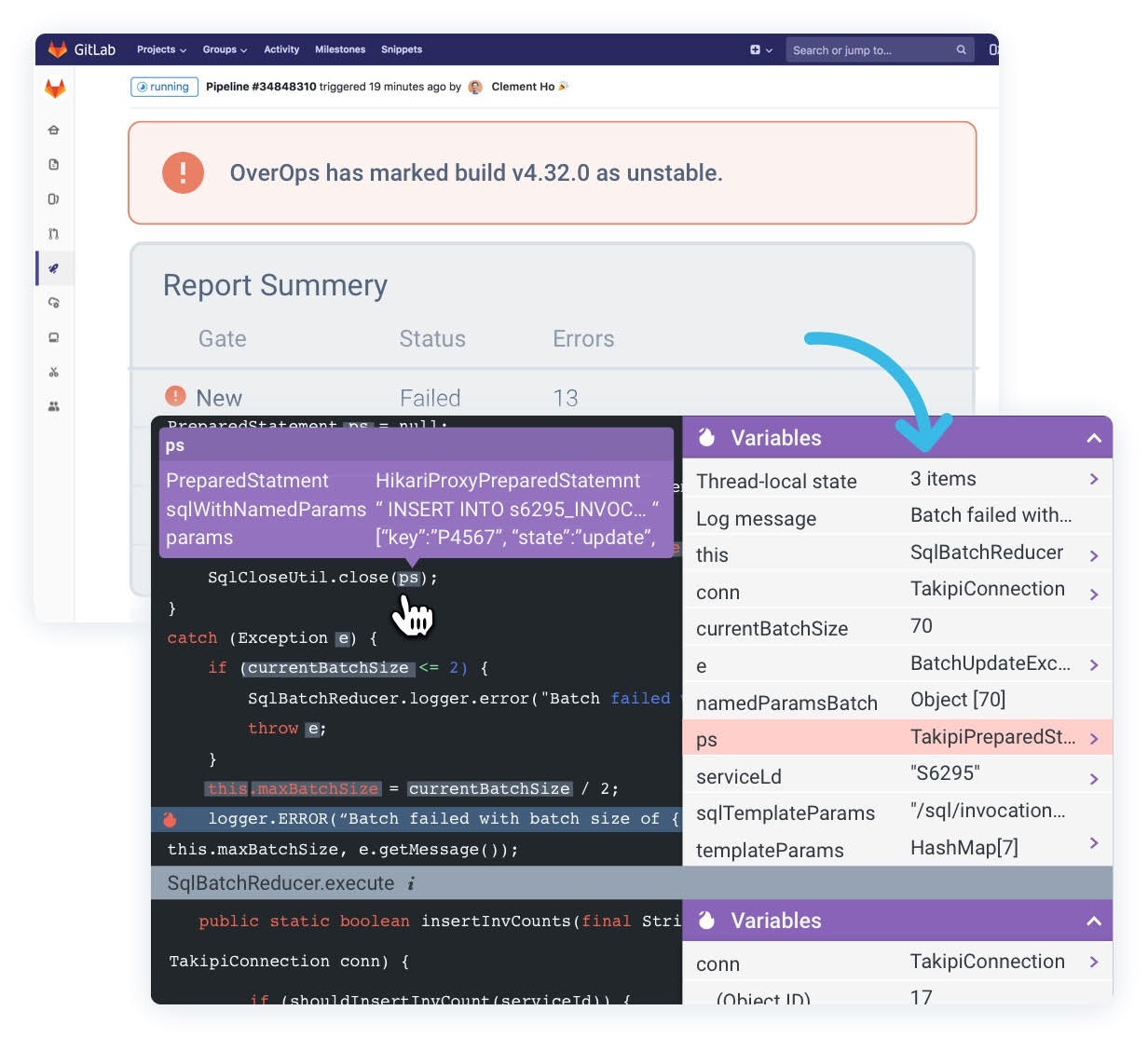
Eric Mizell, vice president of solution engineering for OverOps, said the plugin for the GitLab CI/CD will make it easier to surface issues with code earlier in the DevOps pipeline. OverOps’ quality gates help determine if code is safe to promote and automatically blocks unstable releases from moving forward to production.
OverOps combines static and dynamic analysis of code as it executes by relying on machine learning algorithms to collect data. That analysis can be accessed either via dashboards based on open source project Grafana software or shared with other tools via an open application programming interface (API). It analyzes code at runtime to identify all new, increasing, resurfaced and critical errors in a release. OverOps then generates a code quality report that ranks issues in terms of potential to impact end users and application functionality.
According to a recent survey of more than 600 software development and delivery professionals conducted by OverOps, more than 50% of respondents spend a day or more per week troubleshooting code-related issues.
The survey also finds that nearly 25% of organizations experience critical/customer-impacting production issues on a daily or weekly basis.
The earlier code issues are detected the less expensive they are to fix. OverOps is making the case for making its tool part of the quality assurance gate within any CI/CD pipeline.
The paradox many organizations find themselves in is that as DevOps processes enable them to build and deploy applications they wind up spending a lot more time debugging those applications.
Eventually, developers wind up spending more time fixing existing application code than developing new applications. Tools such as OverOps are employing machine learning algorithms to reduce the amount of time spent discovering code issues, which should free up more time to write new code.
OverOps captures machine data about every error and exception at the moment it occurs, including details such as the value of all variables across the execution stack, the frequency and failure rate of each error, the classification of new and reintroduced errors and the associated release numbers for each event.
DevOps teams historically rely on log data to manually search for anomalies indicative of issues with code. Not only is OverOps faster, but the algorithms will also surface uncaught and swallowed exceptions that would otherwise be unavailable in log files.
There are a lot of aspects of DevOps that now can be better handled by machines than humans. That doesn’t mean humans will be replaced anytime soon. However, the bulk of time-consuming and monotonous DevOps tasks that exist today are eventually going to be performed by a machine faster and with greater precision. The challenge and opportunity now are identifying the tasks where machine learning algorithms can have the most impact sooner than later.
