Intelligent applications are (by their very nature) complex. While conventional software basically consists of one thing (code), intelligent software involves code, models and data. As previously discussed, three distinct fields—DevOps, MLOps and DataOps—have evolved to govern each of these interconnected disciplines.

Moving through the ML life cycle quickly and efficiently requires collaboration between teams in each of the above disciplines. Organizations should strive to make this collaboration as frictionless as possible to position their ML efforts for success. What follows are four places where we believe organizations should focus:
- Infrastructure
- Team structure
- Tools
- Project ownership and KPIs
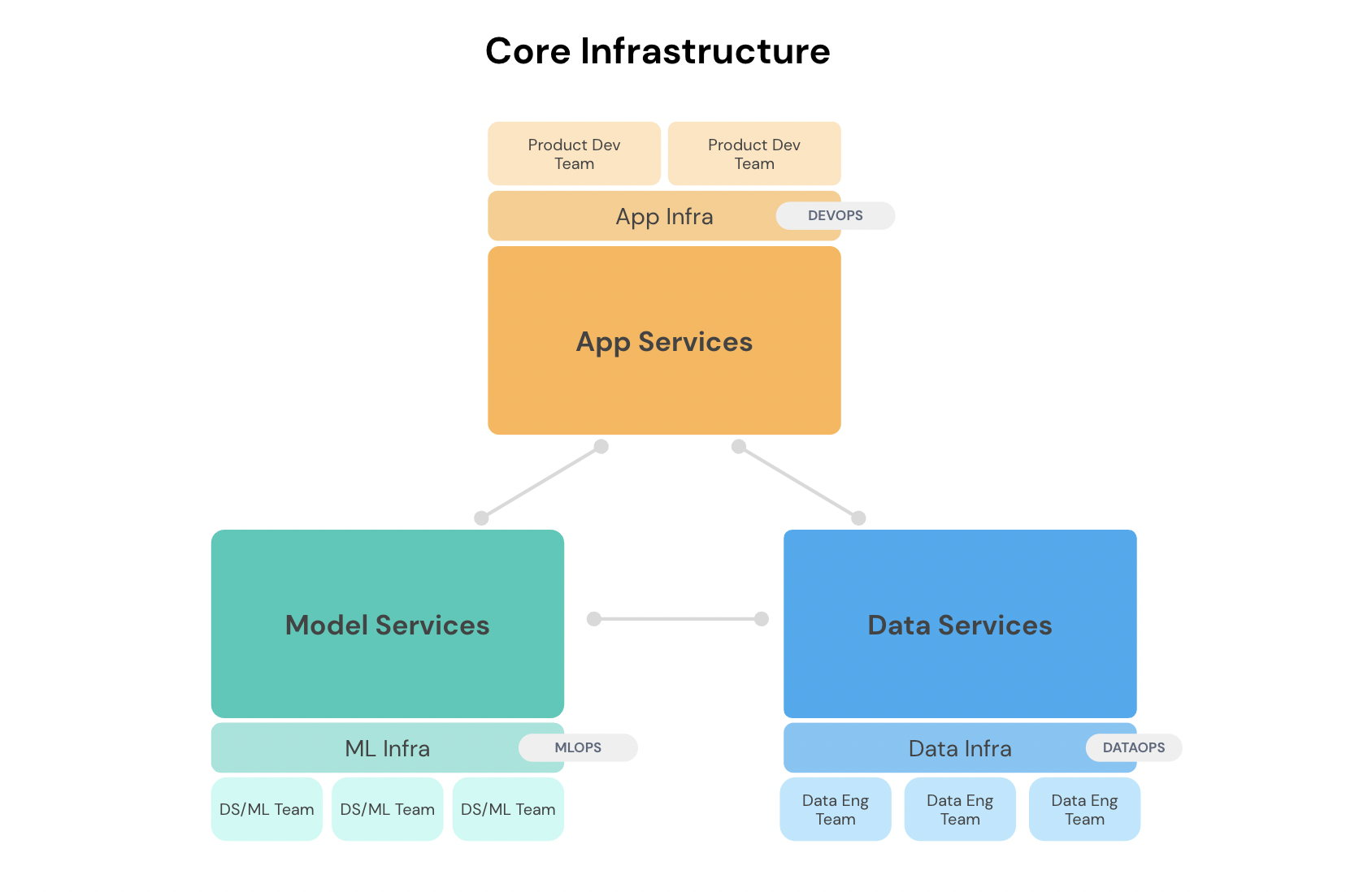
Build Dedicated Infrastructure for Each Pillar
Infrastructure software is not one-size-fits-all across the three pillars of code, model and data. For example, DevOps teams have historically played the infrastructure role in software development, supporting application or product services. Think of regular software engineering teams who are supported by DevOps, producing different kinds of application services. App infrastructure is so baked-in to software development that most of us take it for granted.
Just as regular software services require DevOps, data and model services require corresponding infrastructure. Data infrastructure is typically concerned with managing tools (such as Airflow installations, Spark clusters and feature stores), building data pipelines and ensuring that data services remain smooth and operational for data consumers.
On the other hand, model services are chiefly concerned with creating, running and organizing models in such a way that others can use them efficiently. Since the AI/ML life cycle is incredibly complex, a host of factors need to be considered (e.g., hardware, parallelization libraries, model packaging formats, etc.) to help data scientists and engineers do their jobs efficiently. Robust ML infrastructure along with a dedicated ML infrastructure team goes a long way in helping organizations scale their AI.
Optimize Team Structure
Best practices for ML and AI are continuously evolving, and organizations have tried a host of team structures over the years. We have noticed two popular structures for intelligent application development teams emerged in recent years:
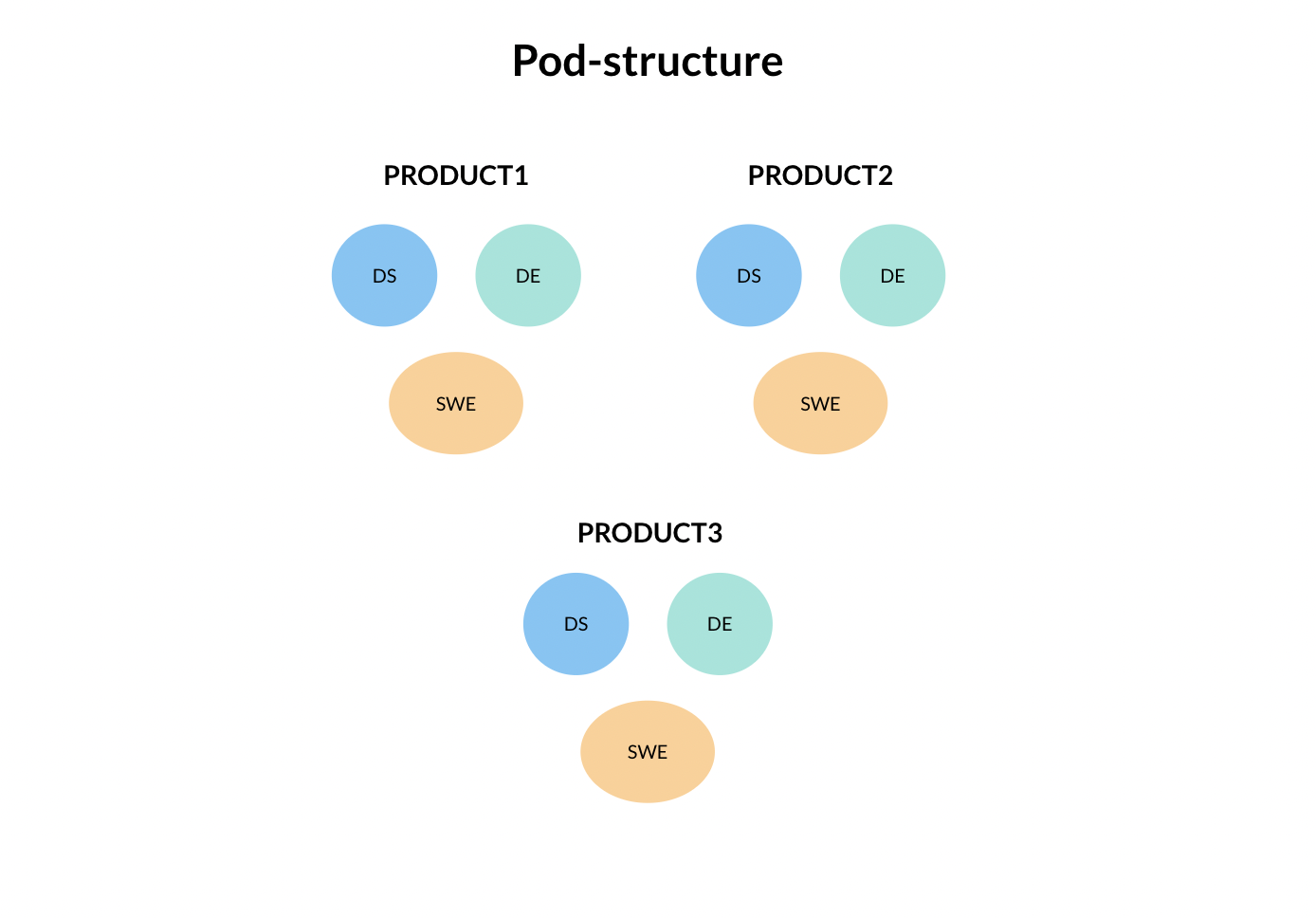
- Pods
Pod structures involve smaller teams—usually a data scientist, a data engineer and an application software engineer—working together closely to deliver an intelligent feature or product. Due to their tight-knit nature, these teams are positioned to iterate extremely quickly, which often leads to better products and features. However, the closely-knit nature of pods also comes with a downside, as knowledge sharing between pods with different objectives can be difficult.
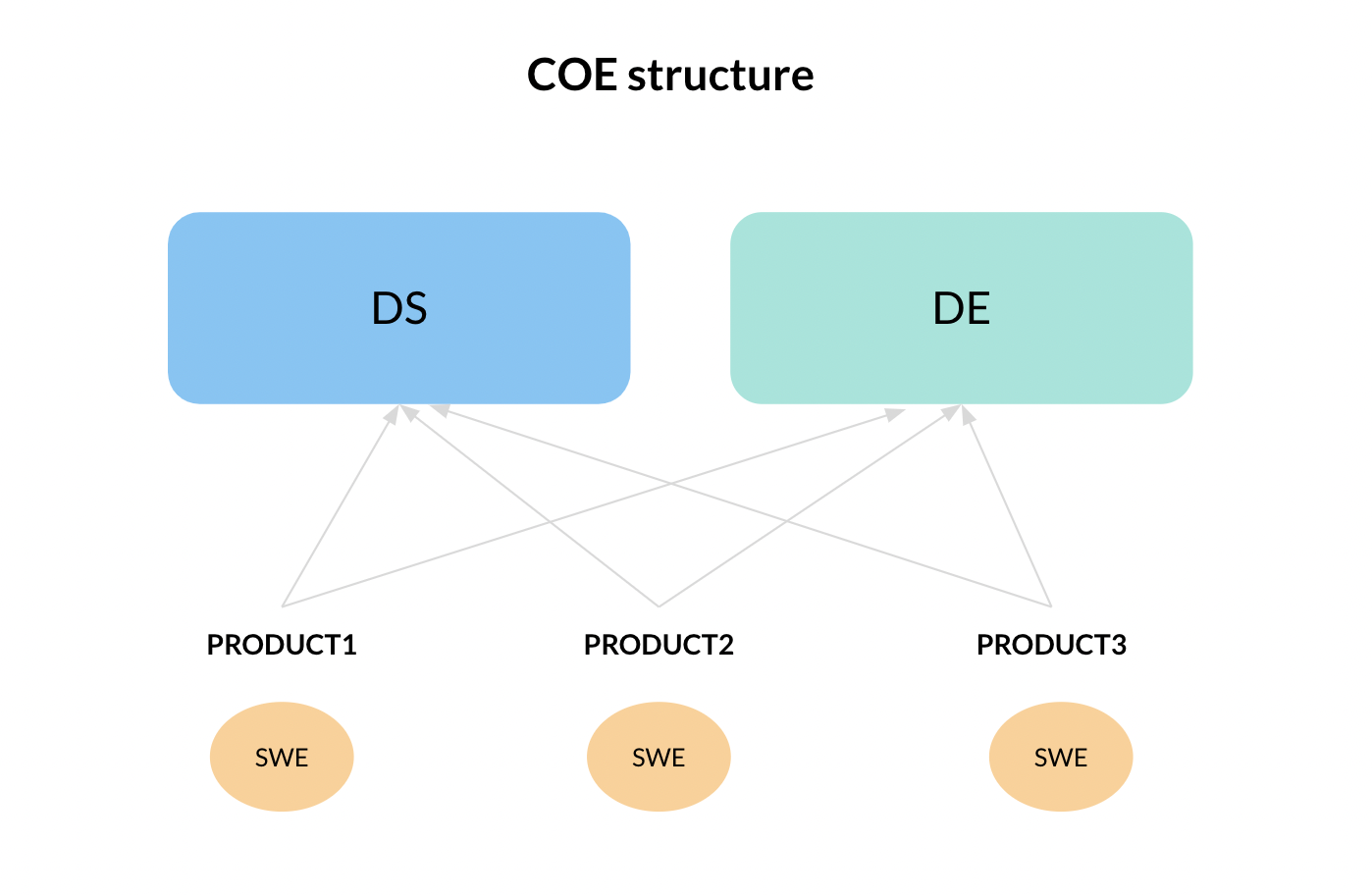
- Center of Excellence
In a center of excellence (or COE) structure, all data scientists or data engineers are “pooled” and then assigned to different products or features depending on project requirements and circumstances. In contrast to pods, COE structures tend to share knowledge very easily. However, this arrangement can lead to slower iteration cycles because team members are not dedicated to particular products or features.
In our opinion, both pod and COE arrangements can be effective depending on the realities of an organization. Choosing an optimal team structure depends on how the rest of the organization is structured and how reporting relationships are set up.
Select Appropriate Tools
To select the best possible tools for your organization, choose those that foster collaboration and uphold safety across code, model and data teams.
The right tools help teams work quickly and efficiently. Teams should be able to discover pertinent information for themselves without having to pull others off of whatever they are working on. For example, a data science team should be able to discover what data access or learn what features exist. Similarly, application teams should be able to discover what models exist, what versions are the latest or how and when to use models. The more that you can make your code, model and data self-serve, the faster teams will be able to build products that are ready to be put into production.
Furthermore, proper tools make debugging faster and easier. If you’ve been around ML-enabled features or products for any length of time, you’ve probably been bitten by undeclared dependencies and apps breaking due to upstream changes. In an intelligent app, finding the root of a problem can be extremely difficult because the root cause can exist in any of the three pillars or any combination of the three. Robust tools provide logs and information to help discover what went wrong more easily.
Finally, governance should play a key role in tool selection, as safety should be a chief concern for ML teams. For example, consider a model that predicts the demographics of a user based on their app usage. While these predictions might be considered acceptable in certain applications, if a model is being used to make financial recommendations or approve credit applications, use of certain demographics may violate various consumer protection laws. Since a software engineer using this model might not be aware of the nuances related to its use, baking in safety checks on model and data use becomes vitally important.
Establish Ownership and Determine Appropriate KPIs
Whether we are working at a company or in an academic lab, our goal always remains the same: build the best product.
But “best product” can mean a lot of different things depending on the use case. For example, sometimes teams may be willing to trade a bit of accuracy if a model fails in predictable ways (e.g., in health care applications.) By contrast, an e-commerce recommendation system can optimize for overall model accuracy even if a model isn’t quite as stable. As a result, choosing the appropriate KPIs for model optimization requires careful attention.
Similarly, choosing appropriate metrics that make sense for the product and business usually requires a high-level view of a number of factors — user expectations, revenues, user complaints, etc. In our experience, product owners are usually in the best position to make these decisions. KPIs for each of the pillars supporting the intelligent app should be based on key metrics determined by product owners. While these can range, we’ve seen the following KPIs work well:
- Code — Number of releases, number of bug fixes, number of features that have shipped, mean time to resolution
- Model — number of model iterations shipped, model quality in production, model performance SLAs
- Data — frequency of data refreshes (e.g., every day or every month?), number of data quality issues, speed of access to data
The key point here is to drive all of these based on the product KPIs and to focus on the agile principle, which is how quickly are you moving and how many deploys are happening.
Know what metrics your team is looking to optimize so that you can invest your resources in the right spot.
