What IT operations professionals can learn from the actual paths people take through tools and processes, and the differences from the expected usage model.
It has been a snowy winter across much of Europe, and although the snow is now beginning to melt in most places, there are still substantial sneckdowns to be seen across our cities.
If you’re not familiar with the term “sneckdown,” it describes those areas of streets that are not actually used, as revealed by the unmarked snow that settles on them.
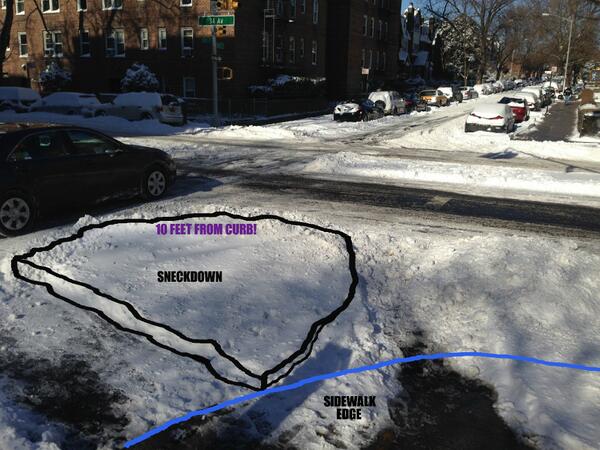
Transportation planners have even been known to use sneckdowns successfully as planning aids.
The world of IT should learn from this example. We may not have anything as whimsical as snow to help us, but on the other hand, we do have enormous amounts of data. Let’s investigate some examples, starting with IT operations.
Restate My Assumptions
IT operations has a bunch of assumptions baked in, but just like with street layouts, some of them may be obsolete, leftovers from a previous generation of technology. My own hometown dates its founding back to Roman times-218 B.C., to be precise-but the sorts of design choices that Roman colonists might make to facilitate chariot and ox cart traffic have had to be updated significantly-first to accommodate motor vehicles, and then again to ensure that the motor vehicles did not crowd out other forms of transportation such as bicycles.
Similarly, much of IT operations is based around the notion of a ticket, which describes and encompasses an atomic problem. This ticket has a single owner at any one time, and is processed sequentially through a series of steps. This is the operations equivalent to the waterfall model of development.
These assumptions used to be reasonable in previous eras of IT technology, when a simple failure of a single piece of equipment was enough to trigger an incident. That incident ticket could easily be paired with the specific piece of equipment that was impacted, and from there a simple lookup would return the responsible group, who could then be assigned the ownership of the ticket.
These days, that model is largely obsolete. Hardware, especially virtual hardware, is cheap enough to be made multiply redundant. Automated functions such as load balancing ensure that single failures are rarely enough to cause an actual incident. Instead, multiple failures have to occur in the right sequence—or the wrong one, depending on your point of view. Meanwhile, operators are drowning in a sea of red alerts, unable to find and focus on the few actionable ones because processes require them to respond to everything. Finally, when a real ticket does make it through the noise, it gets bounced around from team to team, as harried operators try to work out whether it’s their problem or somebody else’s.
Operators are human, after all, and over time they develop their own paths through and around this rigid process, just as people walk and drive their own paths through the snow.
Examples of IT Operations Sneckdowns
Users Working Together
One big IT operations sneckdown is collaboration. Instead of using the ticketing system and its rigid assumptions, operators work around it, using alternative methods to work together and share information with each other. The goal is to deliver full-stack operations for the entire complex business service that is being supported by the team.
The problem with sneckdowns is that if there is no city planner watching and measuring, eventually the snow will melt and leave no visible trace of the paths that people take around their city. In the same way, the risk to the wider organization is that as people work and collaborate in alternative, unofficial tools—whether IRC or Slack—information gets stuck there and does not make it back into the official knowledge base, where it is available to be consulted and reused over time.
Sneckdown Recommendation: Recognize that the nature of modern IT and network architectures means that there may be no single owner of a problem. The rapid rate of change, too, makes it almost certain that any owner will not be documented in a static database somewhere. Instead, modify processes to recognize this multiowner approach, and enable users to work easily with each other without having to play ticket ping-pong.
The Right Tool for the Job
This overlaps with another sneckdown: unofficial tool adoption. In the same way that operators might start using an unofficial collaboration tool to route around limitations in the official service desk process, they might look at Kanban to share task status, or start building libraries of automated diagnostic and remediation actions. The problem is that the rigid official policy often does not accommodate these extensions, and indeed has no mechanism to do so.
Sneckdown Recommendation: Modern operations tools need to offer flexible interfaces to enable integrations and extensions to be done in a safe way. This way, if a particular integration does not work out or needs to be upgraded, that can be done without disruption to the wider process and to any other integrations that are working well.
Look into the Shadows
The final sneckdown—at least for this snow storm—is shadow IT. In the same way that much of our universe is theorized to be made out of dark matter, not visible to our current tools, a growing proportion of IT spending is happening outside the “official” IT budget. This also means that whatever is bought with that budget is outside the official IT operations and support process. That’s all very well on paper, but if the tool Sales or Marketing were relying on to do their jobs goes down, somehow, IT operations is still going to get the call to fix it.
Sneckdown Recommendation: There isn’t an easy short-term fix for this one—no way to shovel it out of existence. Instead, IT operations professionals need to work on this issue from two angles. The first is to address the causes of shadow IT, those rigidities and frictions that make people look for outside solutions rather than engage with their in-house IT departments. When everything is properly aligned, the IT department has a lot to offer in terms of understanding of How Things Are Done inside the organization. The other angle is—yes—to make it easier to accommodate solutions that might have been procured originally as shadow IT. Figure out how to engage with support processes for SaaS solutions that people adopted on their own; if it’s working for them, it’s up to you to keep it working! The benefit is that this alignment will reduce the need for constant injections of energy by sysadmins and operators to keep things running: the Second Law of IT Ops.
Conclusion
Compared to city planners and transportation activists, we IT professionals actually have it pretty easy. We’re not reliant on particular weather conditions for our data, but rather, we have enormous amounts of data at our fingertips all the time. It’s up to us to look at the data with open minds and read the conclusions that are already there. The hard part, of course, is putting those conclusions into action, especially when that requires changes to widely accepted processes, but that is also an opportunity to revisit those processes and make sure they are still as fit for purpose as when they were first adopted.

If you’re interested in what that process looks like, there is an interesting event series: Game Day ITSM & Incident Management Workshop. The next Game Day is in Chicago on March 21, but there is a whole series running, so there is probably an event near you soon. It’s a fun time, and also a great opportunity to rethink some assumptions and look at where some sneckdowns might be that could be incorporated into your planning.
