Whenever you hear the words “the network’s slow today,” or, even worse, “the network’s down,” you know somebody miscalculated. It may have been the person who decided to buy the wrong hardware, or maybe the one who signed up the wrong telecom provider.
Often, that slowdown or outage was the result of somebody underestimating server demand or overestimating the amount of redundancy built into the network setup. It’s always tricky finding the right level of redundancy that will keep users from waiting for their data without overspending on cloud capacity.
A common mistake IT managers make when switching from in-house infrastructure to cloud infrastructure is failing to take advantage of the flexible, affordable, redundant capacity offered by Amazon Web Services, Microsoft Azure and other cloud providers. That’s the conclusion of Yan Cui in a April 20, 2015, post on his “The Burning Monk” blog.
Cui points out that latency is inevitable because things go wrong—and usually, those things are beyond your control. That’s why you have to design your applications with latency in mind. Too often developers work inside a bubble, where all hardware and network parameters are geared to the tasks at hand. In the real world, hardware, networks and software break. If your app isn’t designed to accommodate such failures, you’re leaving your users in the lurch.
Get Real: Inject Latency in Your Test Environment
To model app performance in real-world settings, it isn’t enough to test servers and databases under anticipated loads. You have to take the extra step of mimicking the glitches that are as inevitable as they are unpredictable. Cui proposes injecting random latency delays on every request. He even provides a simple PostSharp attribute that automates the process.
Cui applies the concept of error-planning even further by introducing errors in the mechanism used to throttle requests to prevent bad guys from spamming their servers using such tools as Charles and Fiddler, or any of the spammers’ own bots. By making the errors visible in the dev environment, designers can anticipate them and engineer ways to handle the throttling errors “gracefully.” Once again, a PostSharp attribute is applied to randomly inject throttling errors; Cui states that the same approach can be used to plan for and respond automatically to session expiration, state out-of-sync, and other service-specific errors.
These and other error-detection and -correction methods fall under the umbrella of Design for Failure, a principle championed by Simon Wardley as a key characteristic of next-generation tech companies.
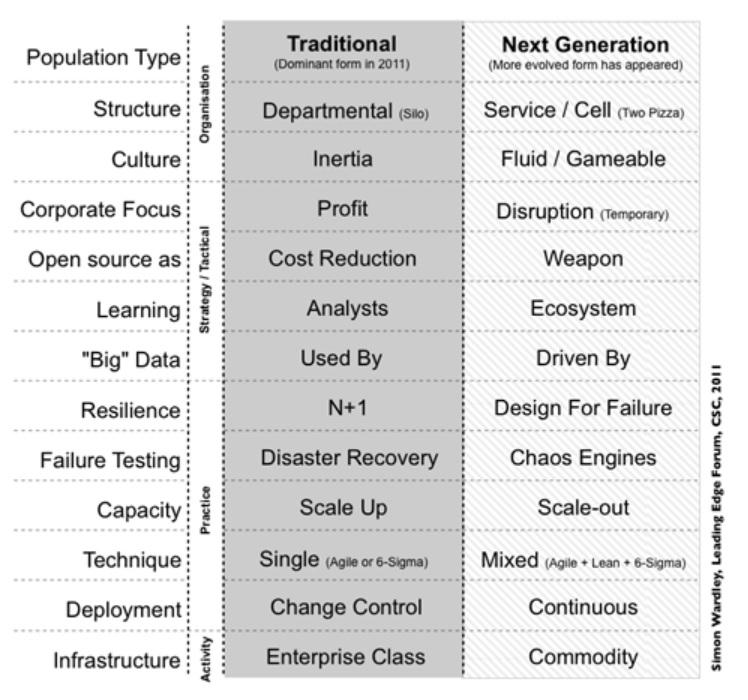
Simon Wardley’s Design for Failure contrasts the development approaches of traditional shops and those he identifies as “next generation.” Source: The Burning Monk
Cui explains how modeling latency and other errors within the development process has been applied by Netflix’s use of Chaos Monkey and Chaos Gorilla, as well as the mechanism Uber devised to allow its client applications to fail over seamlessly in response to a data-center outage.
Learn How to Combat Latency from the experts: Gamers
Nowhere does server performance matter more than in the world of online games, where one-microsecond hiccup can spell the difference between winner and loser, champion and chump. In an April 17 article on Venture Beat, Cedexis’s Pete Masden explains that a 500-millisecond network delay makes an online gamer twice as likely to walk away, while a 2-second delay in load time leads to abandonment rates as high as 87 percent.
Addressing latency begins by measuring it, according to Masden. That’s why we added native monitoring to Morpheus when we built the cloud management platform. Being able to see the status of all your organization’s apps and business services at a glance isn’t just a nice convenience—it’s a competitive advantage. To be able to glance the status of all your organization’s apps and business services, group databases, app servers, messaging queues and web servers by system dependency and impact to view an overall status as well as each app’s current state is crucial to knowing what’s happening in your organization.
One approach to cloud-server latency is to create separate instance, which is common for failover but less so for addressing regional network demand. Rather than the traditional active-passive model, however, Masden recommends an active-active approach when implementing multiple redundant instances to ensure all servers are up to date and optimized. Atop the multiple instances runs the global traffic analyzer to ensure no single instance becomes overly congested.
Is ‘Zero-Latency Computing’ Even Possible? Why not?
If you think network latency is a problem now, just wait until such technologies as 5G, the internet of things (IoT), virtual reality (VR) and robotics go mainstream. Equipment and bandwidth upgrades, and more sophisticated software-defined networking won’t be sufficient to address tomorrow’s application-performance needs. That’s the conclusion of Nitin Serro in a Sept. 29 post on the Channel Partners blog. Serro identifies three technologies as key to meeting future performance requirements: network functions virtualization infrastructures (NFVi), fog computing and zero-latency computing.

The applications made possible by 5G and related technologies come close to eliminating latency by shifting more intelligence directly to the network, not merely by providing faster speeds. Source: GSMA Intelligence, via The Unwired People
While NFVi and fog computing focus primarily on the network and data layers (compute, storage and network infrastructure), zero-latency computing targets the application layer, where information has to be exchanged in real time between diverse components, most of which link directly to users. According to Serro, nothing short of an entire re-invention of the network infrastructure—from backbone to edge—will prevent today’s bottlenecks from becoming tomorrow’s blockages.
Move the Network Intelligence Closer to the Data
The network-capacity challenge we now face is unprecedented, according to Silicon Republic’s John Kennedy, who writes in an Oct. 3 post that even the much-touted 5G network will come out of the gate hobbled by the need to accommodate its many predecessors. Rather than the “step change” in network speed that most analysts expect, 5G will deliver a tremendous boost to network intelligence. This may be the technology’s greatest asset: a smarter network means the data doesn’t have as far to travel.
From an application-design perspective, latency can be traced to three sources: the need to link to legacy infrastructure, the need to link to third parties via APIs and the innate unpredictability of the internet itself. Marqeta’s Dave Matter examines these situations from a payment-processing perspective in a Sept. 13 post on App Developer Magazine.
As with the network infrastructure itself, the solution to application latency is to move more of the intelligence into the app itself and then rely on open APIs to link data sources in real time in an environment that’s closer to users. Once again, the data and associated analytics tools have less distance to travel, and much less latency to deal with. Ultimately, the solution to latency—in hardware and in software—will be fewer, shorter trips.
