These days, with digital threats everywhere, cybersecurity must evolve beyond just being a perimeter measure. Given the rapid delivery of software and the transient nature of infrastructure, security must be built into DevOps. This shift presents both a challenge and an opportunity for site reliability engineers (SREs) to apply zero-trust principles everywhere, starting with infrastructure and services and extending to how developers operate.
Zero-Trust: Beyond the Buzzword
While zero-trust is often associated with network security, many people do not realize it encompasses much more. It involves rethinking how trust is managed in distributed computing. The key idea is to always verify a person’s identity, device status and intent before granting access to any system element — regardless of its location on the network. The principle is ‘never trust, always verify’. Although this concept is used in security, it is still not fully practiced in SRE, as prioritizing availability and performance has usually been more important than focusing on security and telemetry.
With their expertise in systems and automation, SREs have the skills to take zero-trust beyond firewalls and identity solutions (refer to Figure 1). Testing these principles in reliability goals increases teams’ power to reduce the blast radius, secure production environments and deal with incidents more effectively.
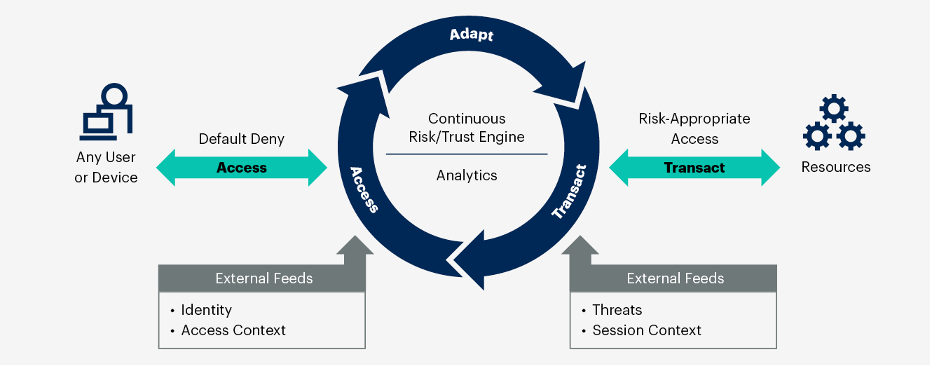
Figure 1: High-Level Zero-Trust System.
It includes regular risk assessment with the help of a central analytics engine. Access to data is prevented by default and is granted only after proper verification. After users have been granted access, they can carry out transactions according to the determined risks. It constantly updates its decisions using information from various sources, such as identity, access context, security alerts and the ongoing session’s information.



The Convergence of Reliability and Security
Reliability engineering today focuses on more than just preventing downtime. The challenge is managing complexity and risk with continuous deployment, increasing service meshes and expanding application programming interface (API) surfaces. Changes in how production environments are run typically outpace traditional information system security (InfoSec) boundaries.
SREs fill this space by working with security teams and ensuring that security as well as observability are integrated into development pipelines. In other words, it is ‘security as dependability’ — they ensure there are no unauthorized changes, remove old passwords and ensure that staff have enough access to sensitive systems.
Take, for example, the consequences of using a compromised API token. If zero-trust principles — including strict access rules, regular authentication and control over service identities — are not applied, someone could use that token to move from microservice to microservice. By adopting zero-trust, SRE teams must integrate authentication between services, trusted connections using transport layer security (TLS) and policy checks directly into their workflow.
Policy as Code: Scaling Trust in the Pipeline
One crucial factor supporting zero-trust in SRE is policy as code. Just like infrastructure as code simplifies system creation, policy as code offers a way to automatically set and keep security policies up to date. Enforcing policies dynamically during continuous integration and continuous deployment (CI/CD) steps allows teams to enhance security while continuing at the same speed. SREs should understand policies as helpful guardrails that help maintain secure and proper configuration, access and deployment. Having policies managed and checked like other code enables a team to grow and creates trust among everyone working remotely.
Telemetry, Observability and Security Context
The nervous system of SRE is telemetry. Thanks to logs, metrics and traces, observability platforms help teams spot out-of-the-ordinary events, anticipate problems and understand the cause of any issues. Security signals such as unsuccessful logins, suspicious ways of gaining access and domain name system (DNS) tunneling are often supervised by different security operations center (SOC) teams.
Making cybersecurity part of SRE culture involves having telemetry that supports security observability, bringing security-related events into the same observability systems as those for performance and reliability. A centralized view reduces the time to locate the issue and improves how incidents are handled as a team. In a zero-trust model, each deviation from normal is considered a possible security threat.
Operationalizing Zero-Trust: Practical Steps for SRE Teams
Building a zero-trust culture in SRE does not require organizations to change everything at once. They can start embedding these practices in everyday operations by doing the following:
Enforce Identity Everywhere: Use evanescent keys, workload identity and service mesh for mutual authentication.
Audit by Default: All system changes, attempts to access them and incidents of policy breaches should result in structured logs that both the SRE and security teams have access to.
Integrate Policy Engines: During CI/CD, implement policies to confirm that deployments meet security and setup rules.
Minimize Human Access: Use automation and ephemeral credentials to eliminate shell access or long-lived keys.
Simulate and Test: Treat security risks as another factor that could cause a failure. Using chaos engineering principles, you can simulate attacks and test how to respond to them.
We must remember that the central aspect of zero-trust in SRE is changing the team’s approach to cybersecurity, not only replacing tools. SREs should learn to consider security events as they would other threats to the system’s reliability. In case of an incident, a security-related view should be included in the postmortem, and blameless retrospectives should focus on breaches of trust boundaries. By tying zero-trust with the pursuit of site reliability, groups can create an environment where security is everyone’s responsibility instead of being kept apart. By following these steps, SREs will ensure the systems remain up, running and safe.
