Lately there seem to have been quite a few DevSomethingOps terms being coined. However, I do think we need one more: DevFinOps.
Dev-What-Ops?

One of the biggest problems in IT is working out the cost of IT. Left unchecked, IT will expand to fill whatever budget it is given. This may mean evermore involved business continuity and redundancy, reinventing evermore elaborate wheels, irrational versus buy decisions and so on.
In fact, the whole idea of cost estimates for IT projects has become something of a joke. Most IT projects are reputed to exceed their budgets.
There is an entire #NoEstimates movement that rejects the idea that it is even possible to deliver a sensible estimate for a software development project. As is often the case, the basic idea is reasonable:
it is possible to do small chunks of work incrementally, leading as rapidly as possible to a desired shippable product, and that when you do that there is no need to do much of anything in the way of estimating stories or the project.
However, the simplistic interpretation that is all over Twitter is that because there is no estimate of the overall project, there is no estimate at all. That is not the idea! It is simply to break down the overall estimate (which is probably wrong) and instead budget for much smaller chunks of work, which can presumably be estimated more precisely and accurately.
So What Can We Do?

Maybe what is required is integration of financial concerns directly into the fabric of IT development operation. We might call this DevFinOps, in line with other extensions of DevOps such as DevSecOps or DevNetOps.
This is not such a leap; after all, we already integrate costs in areas such as SLA calculation, estimating the TCO of a tool or the ROI of a proposed purchase. However, these are generally calculations that are made after the fact, and may even be retconned to fit external assumptions.
What I am proposing, though, is to build this information right into the IT metadata and processes to enable us to make better decisions.
This is not IT Asset Management, although it would build on those data and extend their reach. A particular device or piece of hardware has its purchase price and current amortised value documented in the ITAM database, but the actual value it has at any given time might vary depending on which business function it is currently supporting. This calculation should change over time to reflect the real current value it is delivering to the organization at any given time.
An idle server has no particular value beyond the intrinsic value of the hardware, back-end support (floor space, network, cooling, etc.), and perhaps any associated licensed software. However, the same server will take on a much higher value to the organization when it is provisioned as part of the infrastructure supporting a major business-critical application.
Performing actions on these systems would therefore have different potential impacts, and should be treated as costs deducted from a limited budget. Live-patching a business-critical server is an expensive operation, not to be treated lightly. The cost of doing so should be deducted from an operational budget.
This calculation has the benefit of making it easier to communicate the different impacts of various proposed courses of action outside the IT department. Deciding between cloud and on-premises deployment options, or between different flavors of cloud, can be a fraught process. Technical options and pricing models are rarely easily comparable, and then there are other costs such as compliance (yes, and GDPR) or vendor risk. Quantifying and normalizing these disparate factors would make it that much easier to compare options up front and calculate benefits after the fact.
Is This Even Possible?
Google already does something like this in its Site Reliability Engineering (SRE) program, with the notion of an error budget:
The business or the product must establish what the availability target is for the system. Once you’ve done that, one minus the availability target is what we call the error budget; if it’s 99.99% available, that means that it’s 0.01% unavailable. Now we are allowed to have .01% unavailability and this is a budget. We can spend it on anything we want, as long as we don’t overspend it.
There is a long and sordid history of attempts to make programming projects comparable and their estimates more reliable. Often this devolves to simply counting lines of code, according to the age-old management syllogism: “We need to measure something; this measurement is easy to gather; let’s measure this!” and of course the Mythical Man-Month.
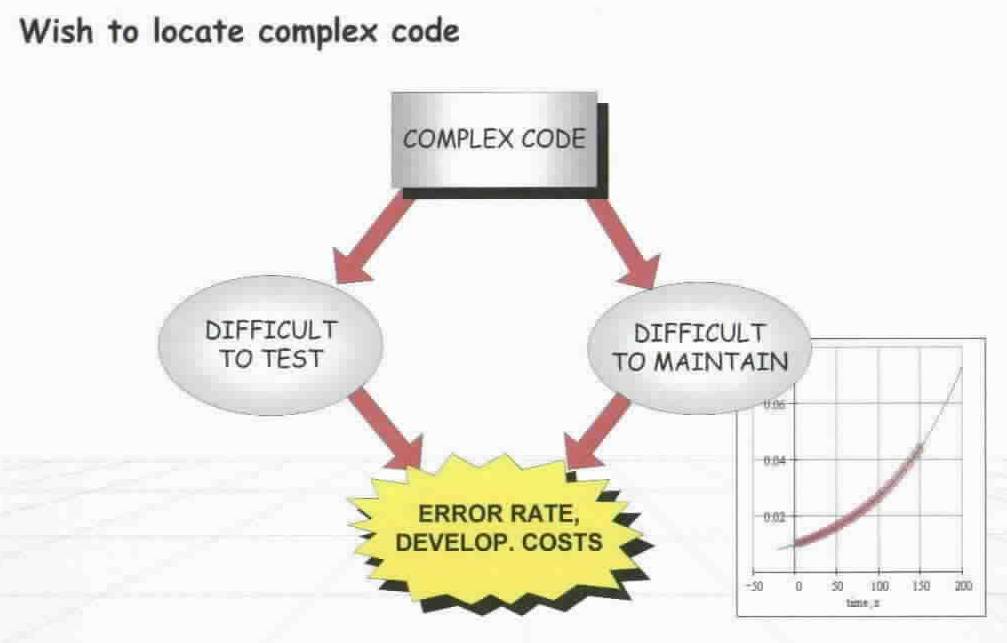
Fortunately, there is a way to calculate the complexity, and therefore the potential cost impact, of a piece of code: the Halstead volume. This is a measurement of the complexity of code, described in terms of the number of distinct operators, the number of distinct operands and the total number of operators and operands. While it is not guaranteed to be perfectly accurate in every case, it is at least accurate enough to be comparable, and therefore can be used to estimate the risk of a change, in terms of the relative Halstead volumes of the code to be changed and the patch to be applied.
But What About the Squishy Meatbags?

Connecting the human costs would also enable other metrics to be gathered. It has been historically difficult to differentiate between what is urgent and what is important, and how to prioritize each. If we connect salary data (including overtime) to changes, it becomes much easier to make the call on when enough time has been wasted on a problem and the cost-effective solution is to start from scratch.
It sounds like a lot of work to gather all of this information, but these data already exist; they’re just not connected up in one place. When the business wants to launch a new service, there are (usually) pretty rigorous calculations behind that decision. The expectation is to acquire or retain a certain number of customers who have a certain average lifetime value and break-even points and other criteria are all mapped out ahead of time. For whatever reason, though, these islands of information are rarely if ever connected up.
This, incidentally, is just one reason why it can be worthwhile to work with reputable and experienced vendors. I have written before about what this process looks like. The good vendor sales teams will help to unearth this sort of information—but even in the most positive sales processes, the kimono is rarely fully open. There is far more information inside the organization that could be enormously useful if only it were available in the right place and at the right time.
Longer term, this would mean that business cases and ROI calculations would finally be concrete and factual, rather than extended performance pieces in the medium of spreadsheets. On that note, there is a wonderful little book, titled “How to Lie with Statistics,” which is even available as a free PDF. It’s one of those books that is fun to read because you start spotting the things it was talking about simply everywhere.
If you wanted to be maximally Zeitgeist-compliant, you could probably verify all of this with blockchain, although I worry that the transaction costs (including thermal costs!) would be prohibitive. The good news, though, is that you could use this DevFinOps methodology to work that out too …
All That Effort, for What?
Bottom line, the goal is to be able to calculate (at least within reasonable limits) how much IT is costing today, and what the impact of any proposed changes would be—and crucially, to do so in real time.
The goal is agile cost estimates. There is a reason I chose the DevFinOps coinage. The way we do cost estimates today is very “waterfall“: large teams have extended arguments over spreadsheets, and the process is so painful and expensive (in person-hours and disruption) that it is only undertaken for the largest changes.
Agile’s faster release cycles do not align at all well to this process, which is where #NoEstimates is coming from. However, if we start gathering and processing all the cost data in real time, and make it available via a simple API call, it becomes possible to calculate both ends of the cost of a proposed change: the complexity of the code itself, and therefore the probability that it contains bugs, and the infrastructure impact that the deployment will have. This cost can then be compared to the team’s current SRE error budget to determine whether the change can be made automatically or whether it requires signoff as an exception.
The result looks a lot like ITIL’s notion of a “standard change”, but without the inherent conflict between ITIL’s centralization and SRE’s decentralization. The key is a common accepted measurement of what a standard change actually is, which would otherwise require the ITIL Change Manager to make the determination ahead of time.
What Does This Look Like in Ops?
Let’s not forget Ops, either. Proper cost estimates like the ones described above would enable Ops to prioritize alerts correctly and estimate impacts accurately. Two outages with equal technical severity may have very different business impacts. Today, that reconciliation relies on tribal knowledge and systems that are often inaccurate or out of date. Given a central shared repository of data that describes the value of deployed systems, it becomes possible to calculate those impacts much more accurately.
While we work to get to full DevFinOps, you might want to consider AIOps, which helps gather a contextual view of what is actually going on in IT. Gartner just released a Market Survey for this emerging space. Normally these documents cost $1,295, but you can get a free copy here, courtesy of Moogsoft.
