HoundDog.ai today made generally available a namesake static code scanner that enables security and privacy teams to enforce guardrails on sensitive data embedded in large language model (LLM) prompts or exposed artificial intelligence (AI) data sinks, such as logs and temporary files, before any code is pushed to production.
Company CEO Amjad Afanah said the HoundDog.ai scanner enables DevSecOps teams to embrace a privacy-by-design approach to building applications. The overall goal is to enable organizations to shift more responsibility for privacy left toward application development teams as code is being written, he added.
Since its initial availability last year, HoundDog.ai has already been used to scan more than 20,000 code repositories, from the first line of code using IDE extensions for VS Code, JetBrains and Eclipse to pre-merge checks in continuous integration (CI) pipelines. The approach has saved early adopters of HoundDog.ai thousands of engineering hours per month by eliminating reactive and time-consuming data loss prevention (DLP) remediation workflows.
DevSecOps teams can also use HoundDog.ai to block unapproved data types, including automatically blocking unsafe changes in pull requests to maintain compliance with data processing agreements.
Finally, HoundDog.ai will also generate audit-ready reports that map where sensitive data is collected, processed and shared, including through AI models, for Records of Processing Activities (RoPA) and Privacy Impact Assessments (PIAs) that are pre-populated with detected data flows and privacy risks that can be tailored for specific regulatory frameworks, such as the General Data Protection (GDPR) or Healthcare Information Portability and Accountability Act (HIPAA).
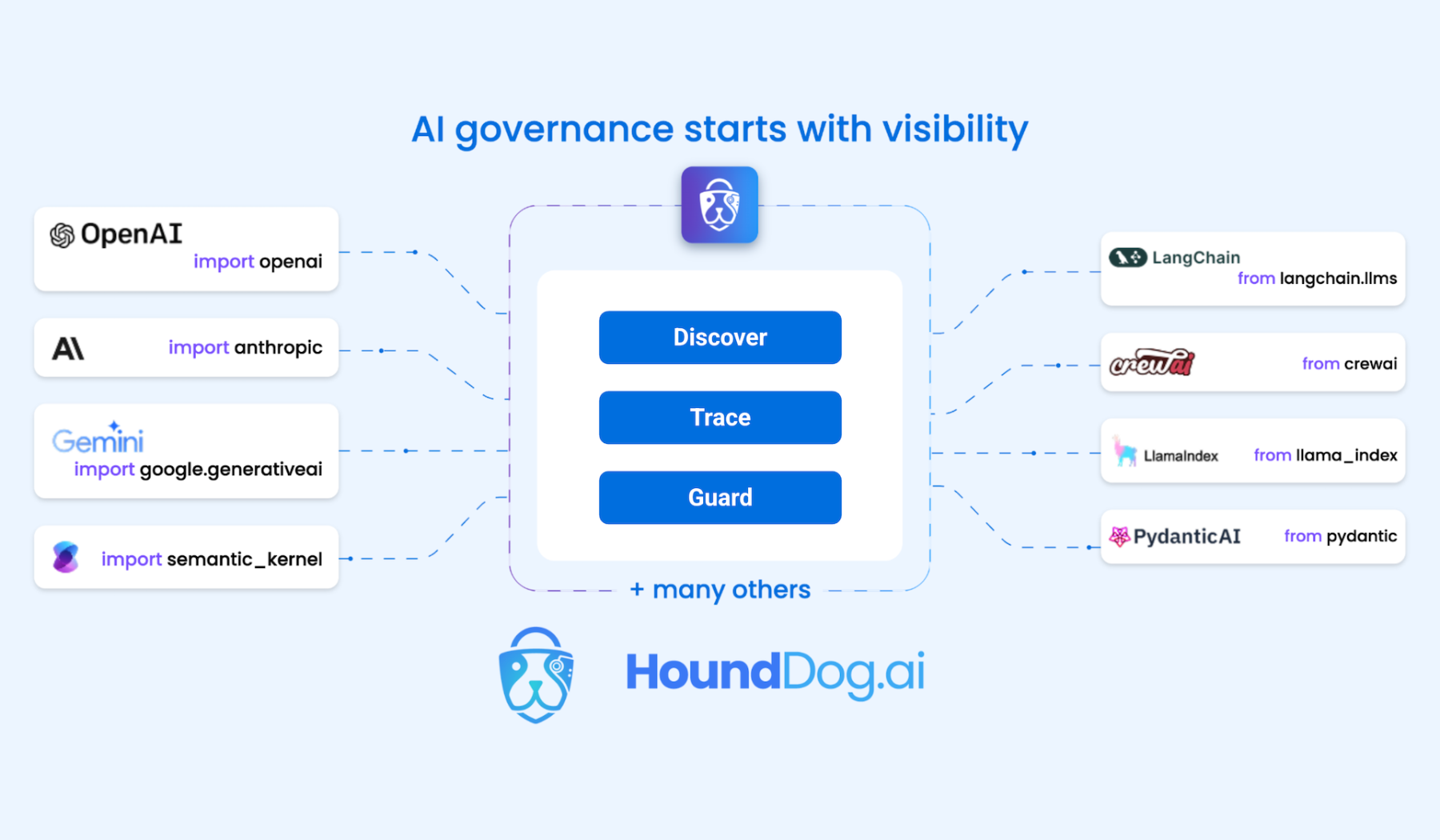
HoundDog.ai is designed to automatically detect all AI usage, including shadow AI tools, across both direct integrations to, for example, OpenAI and Anthropic as well as indirect ones to frameworks like LangChain, SDKs, and libraries, said Afanah. DevSecOps teams can now trace more than 150 sensitive data types, including personal identifiable information (PII), public health information (PHI), card holder data (CHD) and authentication tokens, back to risky sinks such as LLM prompts, prompt logs and temporary files.
That ability to trace sensitive data flows across layers of transformation and file boundaries is going to be especially critical as application developers rely more on AI tools to build code, which may result in sensitive data being inadvertently included in an application, said Afanah.
For example, with the explosion of AI integrations in application development, organizations are discovering sensitive data passed through LLM prompts, software development kits (SDKs) and open source frameworks without visibility or enforcement. Traditional AI security tools typically operate at runtime, often missing embedded AI integrations, shadow usage and sensitive data that is specific to a particular type of organization or industry. Without code-level visibility, understanding how that data entered an AI model or prompt is all but impossible, said Afanah.
It’s not clear how the rise of AI might require organizations to revisit the management of compliance with various privacy regulations, but as regulations eventually become more stringent it is now arguably only a matter of time before privacy, much like security before it, is shifted further left.
