Some months ago, AWS evangelist Corey Quinn wrote a short blog post titled “Right Sizing Your Instances Is Nonsense.” As usual, Corey was spot-on in his takedown of cost-reduction-magic-AI industry hype. But his piece only scratches the surface. I would take the argument a step farther and say that anyone who tells you they can automatically and generally “right-size” compute instances simply doesn’t understand how software works.
Does that strike you as overly aggressive? Stay with me. Even if you don’t wind up agreeing, there’s a lot to be learned about AIOps from a discussion of “automatic instance right-sizing.”
What is Right-Sizing?
Quoting directly from the website of one of the many services that claim to provide “right-sizing” for cloud instances:
“The Recommendations Engine leverages the time series data of relevant utilization metrics for your resources, then creates a statistical model around average and peak utilization periods. The tool leverages historical utilization data to identify performance characteristics across instance types, families and zones to provide valid recommendations for your workload.”
The idea behind this “right-sizing” is quite simple, really: track a bunch of cloud service metrics (and maybe a bunch of OS metrics, too, if they are available), use some statistical model—commonly called “AI” on VC decks—and magically deliver recommendations for a more cost-effective cloud instance type.
There’s just one problem: creating a useful statistical model from generic metrics is practically impossible unless your software is purpose-built to support it, and that is never a software design goal. In fact, software is almost always built in a way that is completely contrary to this goal, and for very good reasons. To understand why, let’s go over the assumptions behind “right-sizing”:
- The software will be able to use all given resources
- Performance will improve (or degrade) predictably and uniformly with added resources
- Metrics accurately describe application load
- Scaling dimensions are independent
- There will be no side effects on connected systems
It turns out, none of these assumptions behind right-sizing are generally true.
A Crash Course in Software Scaling
In theory, software is bottlenecked on resources, be they CPU, disk, RAM, network, what have you. In practice, however, it is extremely difficult to build software that can fully utilize resources.
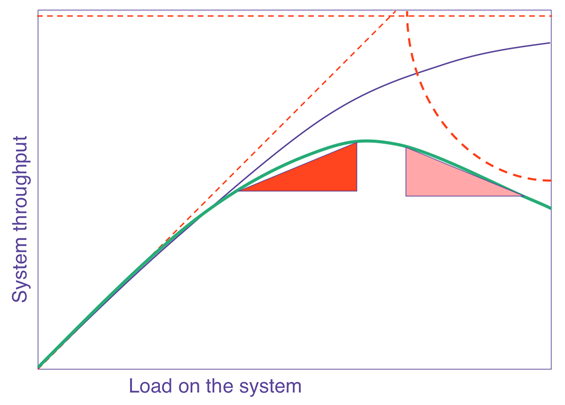
The general curve that describes how software scales with resources or load is known as the Universal Scalability Law (USL). In a nutshell, it says that on any chart showing scale versus performance, you will see a region of linear scaling where adding resources (say, CPU cores) proportionally increases performance; however, you will then see where performance continues to increase on a nonlinear basis, with smaller and smaller gains with every additional resource until, at some point, the benefit is so marginal as to be completely negligible. This is known as Amdahl’s law, which states that the performance of every program is limited by the serial part.
Beyond Amdahl lies the issue of retrograde scaling, the existence of which people often forget about until the consequences hit them smack in the face. In this issue, adding resources actually slows down the system. That’s right. From this point onward, larger servers will make your software slower.
The reason this happens is that, to scale linearly, the workload and resources must be completely isolated and decoupled from each other, which isn’t realistically possible. There are always shared components, e.g. the kernel scheduler, the memory controller, the main PCI bus, perhaps the algorithm requires locking. In any case, the net result is queueing on the shared resource, which might also become a bottleneck when overloaded. Think of a supermarket checkout: you can admit more and more shoppers into the store, but they will still end up waiting at the checkout, eventually, no matter how many registers you open and staff. Performance is limited by the number of checkout counters, not by the number of shoppers or clerks. Worse yet, if the queue gets out of control (maybe people got tired of waiting and shopping carts are literally abandoned in front of remaining shoppers, blocking the path to checkout — think of this as the contention of retries and timeouts), the throughput of checkout will decrease as counters are starved for shoppers.
The USL shows us what happens to throughput as we scale, but what about latency?
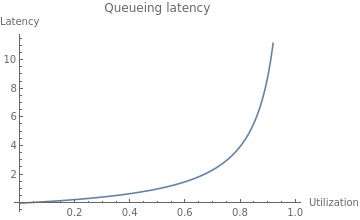
As resource utilization approaches 100%, the wait time for the resource will approach infinity in a nonlinear fashion. This is why systems are designed to run at low utilization, so that quality of service does not degrade too much. You might see a server running at 50% utilization and think, “We can use a server with half the resources and save money!” but if you actually try to do that, you will degrade latency and quality of service to an unacceptable level, most likely causing an outage.
The Dark Arts of Configuration
Even if your software is able to take advantage of available resources in theory, it needs to be properly configured to use them. Buffer sizes, thread pool sizes, memory heap size, number of connections—most software has numerous options to tune it for resources and specific workload. You can’t just change the box size and expect it to work! Not to mention, it’s quite possible your current configuration is far from optimal. I’ve substantially reduced cluster sizes on several occasions by making a one-line configuration change.
For example, a common web server configuration is the number of concurrent requests the server can handle (often expressed as number of threads), which relates to the number of CPU cores available, the amount of memory available to the specific workload and the average time it takes to handle a request. The problem you are solving isn’t “What instance size will have the best ROI?” but rather “What combination of instance size and configuration will have the best ROI?” That is a totally different question that requires specific knowledge of the application to answer.
Let Them Eat Cache
In the old days, when you tried to allocate memory beyond what was currently available, the operating system would simply refuse your request. Ah, the good old days were simple! Alas, in our quest to simplify programming and resource management, and to allow software to efficiently adapt to a changing environment, we made common use of resource tradeoffs. For example, a complicated computation can be calculated again and again using the CPU, or the results can be saved and reused, saving CPU time and trading it for the use of RAM or disk. This pattern is quite common; when you overallocate memory, the operating system may trade off CPU to free memory by compressing memory objects, or it may trade off disk space by paging out RAM to swap. Java, Node.js and Go each have a similar tradeoff where they spend CPU time on garbage collecting to free RAM. Modern software makes numerous tradeoffs between CPU, RAM, disk and network in multiple dimensions. The end result is that different resources are coupled in many unexpected and obscure ways.
Lies, Damned Lies! (And Metrics)
Speaking of that server running at 50% CPU utilization, it is quite possible that server is also maxed out on CPU at the same time. How can this be? It’s because the metrics you see are not raw data but aggregates—in many cases, averages—and aggregates hide certain behaviors that can be very important; for example, peaks and bursts, such as the ones you get from compaction, garbage collection and other periodic processes that routinely run in modern software. There are billions of events happening every second on a modern server, and only a few data points of metrics emitted every minute. All metrics are loss-y; it’s simple math, really. But machine learning (ML) models are only as good as the data they work on, so if the metrics weren’t specifically created to show the relevant behaviors—and they weren’t—the model would be completely blind to their existence.
What is “Performance,” Exactly?
Whenever we deal with resource allocation, we are interested in its impact on performance, which raises the obvious yet rather uncomfortable question: what’s your definition of “performance?” Is it throughput? Latency? Mean or the 99th percentile? Of which transaction? Or, perhaps you are mostly interested in the rate of purchases executed on the website? These are all different things, and often, optimizing one might degrade the others.
This kind of discussion is the first step in any performance engineering session—but completely absent from the scope of “right-sizing” services, and the last thing you want is the generic cost function of the ML model costing you money.
This wouldn’t be so bad if all performance goals could be achieved at once, but, sadly, some of them are in opposition: e.g., higher throughput causes higher latency due to queueing effects. When making changes to software systems, we have to know what performance metrics are important to us.
The Curse of Local Optimization
It is very tempting to look at a cluster of machines as an independent system. But if that system is doing something meaningful, it is part of some bigger system, and changing the configuration will likely have an effect on the larger system it is a part of. When we make changes to subsystems, it is with the intent of improving the system as a whole, to make the customer happy and make more money. But when a change to a subsystem is motivated by a desire to reduce the cost of the subsystem, the result is often an increase in the overall cost of the system! This is because the local cost of subsystems is relatively small compared to the cost of the entire system, not to mention the possible reduction in the income of the system. For example, you could save lots of money by using older, slower servers, but your customers won’t be very happy with a slow application and your profits will suffer—which will probably cost you much more than whatever you saved.
To take this ad absurdum, you could save 100% of the subsystem cost by turning it off completely. Of course, the assumption is that changing server sizes will not have any side effects, which, as discussed, is highly unlikely. There will be side effects on connected systems as well, some of which will not appear immediately. Load is variant, and operational overprovisioning and buffers were often put in place for a reason. It’s quite likely the reason for low utilization is safety margins.
The Problem With “Right-Sizing”
The basic problem with “right-sizing” is the rather obvious, yet implicit, assumption that there is such a thing as “the right” size. Software engineering is all about tradeoffs, precisely because it’s very rare (if it happens at all) that one thing can be improved without making another thing worse. Tradeoffs mean business decisions to make, and you really don’t want a generic ML heuristic to make those for you. ML is very good at dealing with problems where a lot of data is available, the data is high quality, the data is predictive of behaviors (which isn’t the case for complex systems!) and most important, the problem is well defined. Most problems in AIOps are very far from this. Don’t take it from me, take it from the people who excel at both high-scale ops and ML.
Even if it was feasible to make such ML models work, software is unable to automatically adapt to different machine sizes and fully utilize server resources. If it were, companies like ScyllaDB and Azul Systems wouldn’t need to exist. Creating software that is scalable and resource-efficient on modern hardware is a very difficult problem, and without those building blocks, ML models are constructing very shaky structures.
It’s worth emphasizing that I’m not arguing against adapting the size and configuration of servers, only that doing so automatically and blindly for some local “cost-saving” goal isn’t the solution you might think. The goal of such changes should be to raise the overall quality and performance of the larger system guided by a theory of how that system works. ML is not a replacement for human thought and learning. There might certainly be an “optimal” instance type, or even a few, but “optimal” implies a target metric that certainly isn’t cost reduction. No system exists for the sole purpose of being inexpensive. All systems exist to serve business requirements first, and to be low-cost second.
