This is 3rd part of the multi-part series covering Automation, provisioning and Configuration Management. In this follow up article best practices for Puppet shall be covered.
Why Puppet?
While every system administrator comes up with more progressive systems to be managed, the automation of every mundane task is increasingly significant.
Instead of achieving in-house developed scripts, it is necessary to share a system that can be used by everyone, irrespective of one’s employer. But undoubtedly, this is not possible manually.
So, Puppet has been developed to benefit the sysadmin community in building up and sharing of all mature tools, which prevent the replication of a problem which is being resolved by many.
Following are the key methods followed by Puppet:
1). It supports a powerful framework, and is responsible for simplifying most of the technical tasks required to be done by the sysadmin.
2). The sysadmin’s work is written in form of code, easily sharable as the other pieces of code, in the puppet’s custom language.
The Puppet usage accelerates your work as a sysadmin, as it supervises and handles all the details. You can download the code from other sysadmins to help you get your work done even faster. Most of the Puppet implementations make use of one or more modules already developed by others. One can find hundreds of modules developed and shared by the community.
What is Puppet?
Puppet is an open-source IT automation tool developed by Puppet Labs. Its written in Ruby; composed of a declarative language for expressing system configuration; a client and a server for distributing it; and a library for realizing the configuration. Puppet helps in automation, deployment and scaling of applications in the cloud or on site.
The basic design objective of Puppet is to come up with a powerful and expressive language backed by an influential library that makes you write your own server automation applications in just a few lines of code. Its intense adaptability and open source license lets you add up the required functionality. And, you can also share your innovations with others.
System Components:
Puppet in general is used in a client/server formation, with all your clients talking to one or more central servers. Every single client contacts the server at regular intervals i.e. every half hour, by default. It even downloads the latest configuration and makes it sure that it is in sync with the configuration. The moment it’s complete, the client is able to send a report back to the server and can also refer to the changes required.
Following diagram displays the data flow in a usual puppet operation:

Puppet’s functionality is framed as a heap of individual layers. Each layer is duty-bound to a fixed aspect of the system with a tight control on how information transfers between these layers.
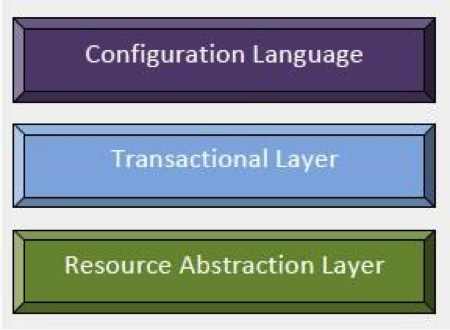
Fig2
How Does Puppet Work?
The Puppet agent acts as a daemon that runs on all the client servers where configurations are required, and the servers to be managed by Puppet in the future. Now all the clients to be controlled will have puppet agent installed in their systems. This puppet agent also known as a node in Puppet will have a server designated as the Puppet master.
Puppet Master: This machine restrains the entire configuration for different hosts, and runs as a daemon on this master server.
Puppet Agent: This is the daemon that will run on the entire server that is to be managed with the help of Puppet. At a specific time interval, the Puppet agent will go and inquire the configuration from the puppet master server.
Now the connection network between the puppet agent and master is built in a secure encrypted channel with the support of SSL. For example, if the Puppet agent has already applied for a necessary configuration and there are no new changes, it will do nothing. By default, the puppet agent will go and fetch the required config data from the puppet master in every 30 minutes.
From the above diagram it is clear that puppet master server has all the configuration options available for Host 1 or Node1, Host 2 or Node 2 and Host 3 or Node 3.

Following are the steps that are always followed whenever a puppet agent of any node makes up a connection between a node and a puppet master server to fetch the data.
Step 1: Every time a client node makes a connection to the master, the master server examines the configuration to be applied to the node.
Step 2: The Puppet master server takes and assembles all resources and configurations be applied on the node, and brings it together to make a catalog. Now, this puppet is given to the puppet agent of the node.
Step 3: According to the catalog, the Puppet agent will apply configuration on the node and then reply. It will also submit the report of the configuration applied to the puppet master server.
Who would find Puppet useful?
An organization that would like to decrease the cost of maintaining its computers could benefits from using Puppet. Since the return on investment is related to several factors such as the current administrative overhead, diversity among existing computers, and cost of downtime. It might be complex for an organization to determine if it should invest in any configuration management tools, much less Puppet.
In general, any organization should make use of server automation if any of the following are true:
- It comes up with a higher server administration costs
- Either because of contracts or opportunity cost, it pays a high price for downtime.
- It contains loads of servers that are fundamentally identical or nearly identical.
- Flexibility as well as agility is required in server configuration.
Conclusion:
Puppet refers to the two different things
- The language in which code is written
- The platform that manages infrastructure.
Puppet is both a simple and a complex system. It is composed of several moving sections wired all together quite loosely. It is a structure that can be used for all configuration problems. Our future success rests on the structure becoming more powerful and simple, for it should be approachable while gaining capability.
