You may have heard the term “continuous testing,” but are struggling to understand what it is and how to achieve it. Project teams need to improve their ability to test and perform test automation when needed, not just when possible. Service virtualization allows teams to test earlier and more often in the life cycle, or “shift left,“ by mimicking unavailable systems. Combining test automation with service virtualization enables teams to provide immediate feedback on quality—so issues can be resolved faster and cheaper. Encouraging and embracing this immediate feedback on the quality of the solution enables businesses to deliver high-quality innovative solutions to the market quickly.
In addition to shifting left by using service virtualization, finding the right balance of effort across all testing practices is crucial in achieving continuous testing. The diagram below shows the key test practices that enable continuous testing, and teams spend effort on each of these practices regardless of whether they want to. The questions below may help your teams understand where they are spending time, and perhaps where their time might be better spent.
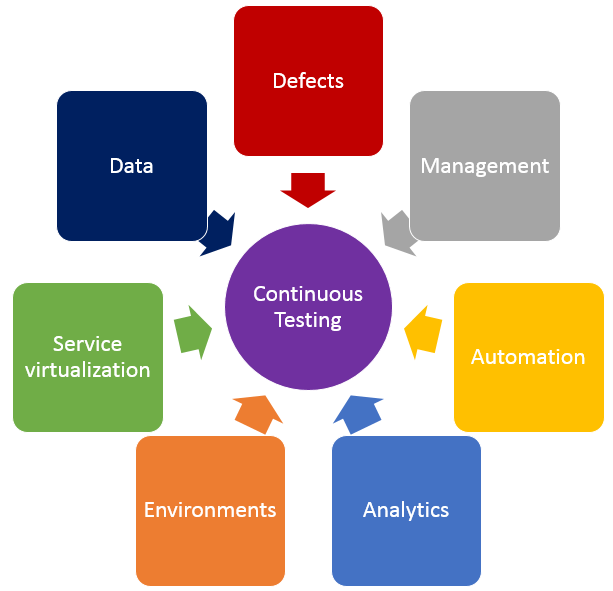
- Defects – Are teams spending too much time logging, triaging or analyzing defects? What about time spent on defects that aren’t “real” defects—where there is a misunderstanding between the test and the code? Or what if they could prevent entire schools of defects from ever being created in the first place?
- Test Management – Are teams spending time manually crafting status reports and rolling up test execution results? Or do they have a tool that provides that information in real time and allows stakeholders to drill down as needed? How do teams know if they are on schedule with their test effort, behind schedule or even ahead of schedule?
- Test Automation – How efficient are teams at re-executing existing tests? Do they run most or even all of them manually? If they’ve automated tests, are they focused only on functional tests at the user interface layer, or are they running functional API-layer tests, performance tests and even security tests? Do they have a robust and maintainable test automation framework?
- Analytics – How do teams know which tests they should run, when and even why they are running those tests at those times? How good is their test effectiveness–meaning, are they running the fewest number of tests that find the largest number of problems? Impact analysis is critical in selecting the right sets of tests to execute whenever they get a new build.
- Test Environments – Are teams constantly waiting on test environments to be provisioned and configured properly? Do they run tests and discover after the fact that the test environment wasn’t “right,” so they have to fix the environment and then re-run all the tests again? Do they hear from developers, “It works on my machine!” but it doesn’t work in the test environment?
- Service Virtualization – Are teams waiting for dependent systems to become available before they can “really” test? Are they using a “big bang” approach to conduct end-to-end system testing, where they throw all the components together and hope they work and interact properly? Can teams test exception and error scenarios before going to production? Are they testing the easiest parts first just because they are available, and delaying the high-risk areas for the end of the testing effort?
- Test Data – Do teams have the needed sets of production-like test data to ensure they are covering the right test scenarios? Are there exception and error scenarios that we can’t execute because they don’t have the right sets of test data?
If any of these problems or ideas resonate with you, here is guidance on how to get started on the journey to achieve continuous testing.
First, identify your bottlenecks:
- How good is your test efficiency – are you able to run the needed tests and provide feedback quickly?
- How good is your test effectiveness – are you running the fewest number of tests that find the largest number of problems?
- Bottlenecks may also be upstream or downstream from actual test execution effort – are you waiting on dependent systems, or test environment provisioning?
Then, look at all aspects of your test effort and focus on the largest bottlenecks first.
- How long are your delays in test environment provisioning, and are the environments accurate when they are provisioned? If delays are too long and environments aren’t correct, automate your test environment provisioning and configuration to eliminate manual errors and gain accuracy and reliability.
- Are you waiting on dependent systems to start testing? If so, use service virtualization to simulate those unavailable systems so you can start testing sooner.
- Are you unable to run all the needed tests before the next build is available? If this is the case, automate your high-risk regression tests to improve test efficiency.
- Do you find performance problems late in the life cycle, or even in production? Outages can result in long-term damage to a business, so conduct load, performance and stress testing earlier in the life cycle.
- Do you find significant problems when all systems are integrated? Identify and agree upon system interface and data definitions, and create automated integration level tests for the high-risk integration points.
Teams that improve their test efficiency and effectiveness significantly reduce their expenses and the time it takes to get high-quality, innovative solutions to users. You can’t test everything, and you can’t automate all your tests, so it is critical to find the right balance. Also key is service virtualization, which allows testing to begin as soon as a build is made by mimicking missing dependencies. By combining test automation and service virtualization, teams can test earlier, or “shift left,” so they gather feedback faster than ever.
Learn more about using service virtualization to shift left and avoid downtime in test environments in our upcoming webcast: How Maersk Uses Service Virtualization to Shift Left and Avoid Test Downtime.
About the Author / Marianne Hollier
 Marianne Hollier is an IBM and Open Group Master Certified IT Specialist in application development. She has strong, practical expertise in measurably improving the software development life cycle and driving the necessary cultural changes to make it work. She is instrumental in architecting, tailoring and deploying the IBM DevOps best practices as well as appropriate software development tools on many types of projects, from large to small, long to fast-track, agile to traditional. Marianne is especially passionate about all things testing—process, tools, culture and automation. Her experience is broad-based, spanning both custom projects as well as standard software packages that apply to many industries, including refining, pharmaceutical, telecommunications, health care, financial, automotive, government and retail. Connect with Marianne on LinkedIn or Twitter.
Marianne Hollier is an IBM and Open Group Master Certified IT Specialist in application development. She has strong, practical expertise in measurably improving the software development life cycle and driving the necessary cultural changes to make it work. She is instrumental in architecting, tailoring and deploying the IBM DevOps best practices as well as appropriate software development tools on many types of projects, from large to small, long to fast-track, agile to traditional. Marianne is especially passionate about all things testing—process, tools, culture and automation. Her experience is broad-based, spanning both custom projects as well as standard software packages that apply to many industries, including refining, pharmaceutical, telecommunications, health care, financial, automotive, government and retail. Connect with Marianne on LinkedIn or Twitter.
