According to the 2016 State of DevOps Report by Puppet and DORA, the mean time to recover when a service incident occurs ranges from less than one hour for high IT performers to less than one day for medium and low IT performers. Put that in a real-world scenario: your OpenStack application and the data associated with it that spans multiple virtual machines failed (for one reason or another). Now you need to rebuild something you’ve already spent time developing. Are you—and your boss—OK with that rework taking hours to days? Or do you think you’d be wishing you fell in the range of high IT performers, and you could quickly recreate what you lost in less than one hour?
Now, take it a step further. What could you be doing with that time you now need to dedicate to rebuilding something? What will that rework take you away from? The next phase of your development? Lunch? Happy hour? Sleep? What price would you put on the personal cost to you?
The 2016 State of DevOps Report authors wanted to calculate the cost of excess rework per year for organizations. They created a formula to calculate the number:
Cost of excess rework = Technical staff size x average salary x benefits multiplier x percentage of technical staff time spent on excess rework
Here’s what they found:
- High performers have 11 percent excess rework
- Medium performers have 22 percent excess rework
- Low performers have 17 percent excess rework
At first glance, those numbers seem odd. Why would the low performers have less excess rework than the medium performers? The report clarified that by explaining “low performers spend less time on rework … because they report spending a greater proportion of time on new work. We believe this greater amount of new work could be occurring at the expense of rework, thus racking up technical debt.”
It’s clear all organizations have some amount of rework as a result of a failure of some kind. The question is, What is the cost of that rework? Let’s take a look at the results of the study.
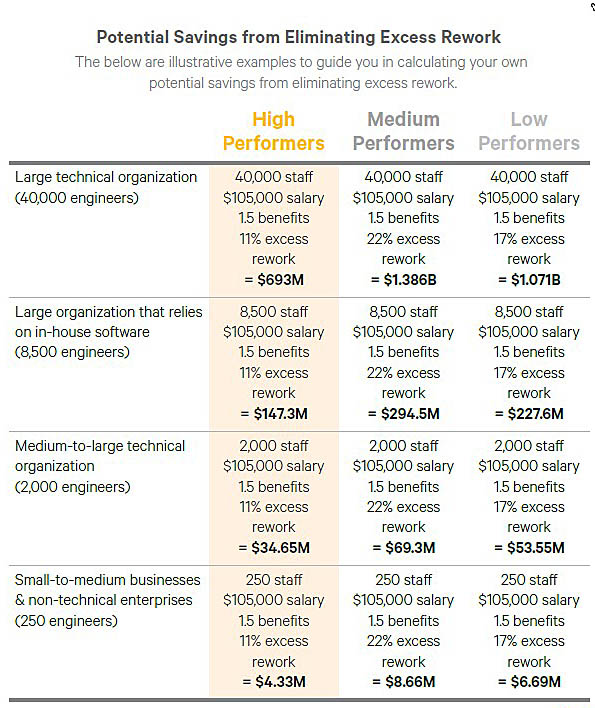
For the most part, the simple answer is that rework will likely cost your organization millions (unless it’s costing you billions). It’s just a matter of how many millions.
We often get asked why it’s necessary for OpenStack environments to have a data protection strategy and a backup solution. The conventional (but wrong) thinking is that virtualization can take the place of data recovery. Frankly, the answer to why is contained within those numbers above. If you don’t have a backup and recovery solution for your OpenStack development efforts, are you willing to spend money and resources on reworking the lost data? And if you are, how many millions are you willing to spend on it? Let me remind you that you are trying to recover to a point in -time … persistent data included. If you say, “If you built your cloud appropriately, this shouldn’t be an issue ….” Madame or Sir, if your virtualized cloud has that kind of resiliency, then I would like to work for you.
