In Part One of our two-part series on scaling for cloud environments, we looked at some of important factors for scaling and best practices for code storage. Let’s continue the discussion.
Auto Scaling for Next-Generation Applications
There are a few very good-looking cloud hosting service providers that provide the features mentioned in Part One: AWS, Google Cloud Platform (GCP) and Microsoft Azure. If you are going to auto scale, it’s best to use one of these cloud hosting services. There are other cloud hosting service providers in my knowledge that follow similar approaches, but they are not widely used or are platform-as-a-service (PaaS) ecosystems so we will not cover them.
Also, it’s important to remember that in auto scaling, all app nodes are changing and created dynamically, with a new host, new IP, etc., so your synchronization mechanism needs to determine how to update the code with the new nodes that may change or be deleted later.
Options to Auto Scale and Not Die Trying
Lsyncd
Lsyncd allows you synchronize nodes across the cluster that are spinning up/down new instances, Work using this script, which monitors the auto scaling group for new nodes and updates the Lsyncd master with new auto scaled slaves. Discovering which IPs or instances are within the auto scaling group is the preamble auto scaling faces, but this script will help resolve the discovery.
GlusterFS
Another approach is to use GlusterFS, which ensures high availability and syncs between your web nodes. You need a minimum of two instances in case one fails. The other instance can jump in and still be tolerant for failures. Once the failed instance is back online, it’s added again to the cluster. GlusterFS works similarly to master/master or master/slave. I won’t cover how to configure GlusterFS, but I’m sure this approach was a very good option before AWS EFS was released. If you are not using AWS, this is an awesome option.
On the other hand, if you are using AWS environments with EFS, consider registering your web node to the master node using “AWS User data,” so every time a new EC2 instance is created by the ASG, it will register this new volume to the master and keep data synced with the rest of the nodes.
Pre-Baked AWS AMIs (Old Approach)
Given the fact that your code won’t change or barely changes, baking an AWS AMI and updating the auto scaling launch configuration will do the trick—this is an older but still-used approach. When you have a defined code release schedule and a defined development workflow, you could bake an AMI for every new code release and, once ready, recycle the nodes to use the new AMI with the latest code update. There are plenty of tutorials on this method.
Admin Server (mainly used for WordPress, Drupal, Magento and CMS-based apps)
Another wild approach is to use an admin or master server out of your auto scaling group. This is used commonly to sync code from the master to the scaling group, but I believe this a waste of server resources that can be used inside the auto scaling group. I would recommend this approach for WordPress or Magento sites; in addition to this, consider proxying the wp-admin or administrator URL to the admin server, or update the CMS directly to the admin server. As with NFS, AWS EFS will facilitate everything with WordPress, Magento, joomla and CMS-based apps. Click here for an example of what I’m talking about.
Implement AWS EFS
Finally, the easiest approach is AWS Elastic File System – EFS. Amazon Web Services released EFS a few months ago as a very promising technology—a distributed file system similar to NFS but improved—think of it as a sophisticated NAS solution. During AWS Re:invent, the company said EFS is based on NFSv4.1 but with better network performance, and is a pNFS workaround. I have waited for such a component in the arsenal of AWS for months, though early access was only available for the Virginia region. Today, though, it is supported across all AWS regions – Yay!
EFS can be mounted as a local mount point within fstab, similar to NFS, and you can share your code across your AWS auto scaling group: Set your EFS volume in/etc/fstab to load automatically in each reboot. Therefore, If you are in AWS, use EFS; it will facilitate everything—really. To accomplish this approach, make sure to update your user data in each EC2 instance with the EFS mount point, so every time a new instance is created it automatically will have the EFS volume.
Note 1: All EFS mount points should be in the same region; if an EC2 instance tries to mount from another EFS region, it won’t be allowed.
More Details can be found here.
Google Cloud Platform
Well, what do we have for Google Cloud Platform? I suggest GlusterFS, Lsyncd, rsync or Google Cloud Storage—although it shares a lot of features with Amazon S3, it is faster. Google states that its cloud storage is faster than Amazon S3 due to its infinite edge points across the world and, yes, it is correct. The easiest way to share the code across your auto scaling group is to use Google Cloud storage and GSutils. Additionally, you could use GSutils and call the bucket in each Google Instance—just make sure the visitor/user does not change the code or static content in the instances. Also, Gsutils helps sync the bucket data to your instance data to stay in sync. If your code changes dynamically with your traffic, you need to use gluster or Lsyncd, given that it is very complicated to deploy since Google auto scaling is always recycling instances/IPs and needs some workarounds.
Don’t Forget Scaling Databases!
Another topic that we didn’t touch was scaling a database, for AWS RDS, DynamoDB, Postgresql, Mysql and Nosql databases. All these modern databases are easy to scale; some of them are PaaS such as DynamoDB or RDS. For Postgresql, MySQL exists only for manual scaling, which is adding new database nodes to the master/slave cluster. In AWS RDS, with some clicks you can get a slave “replica” and you are scaling already. But I won’t go further about it as it’s out of scope for this piece.
Scaling Microservices and Serverless Apps
Definitely, these topics need another talk. There will be another time to explore this new architecture approach of splitting your application into pieces. Microservices is changing the IT paradigm, but to survive for this new paradigm, you need to understand first scaling for cloud before evolving to microservices with Docker, Consul, Compose, RancherOS, AWS ECS, Kubernetes and Serverless apps architectures.
Conclusion
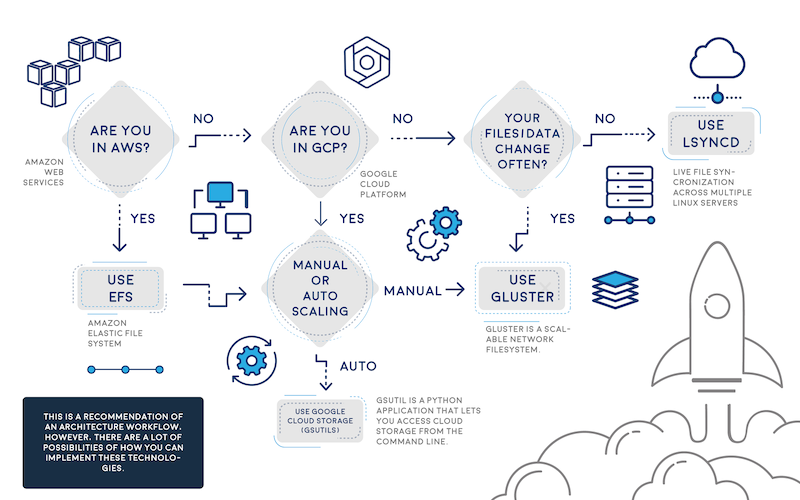
As you can see, scaling an application can be challenging when you are dealing with a custom app or CMS-based application. With this article, you have the options and their pros and cons in tackling this constant preamble of how to scale with custom apps. Everybody uses their own scaling process and seriously, they never fit with other applications’ needs. Now that AWS EFS is out there, I’d recommend it every time you can, but in case you are not using AWS, implement Lsyncd or GlusterFS, but don’t forget the other methods that also can help accomplish your scaling goals.
About the Author / Alfonso Valdes
 Alfonso Valdes is the CEO and Founder of ClickIT Smart Technologies, a IT agency focused in the architecture and implementation of Modern Cloud Applications highly resilient in Linux and Open Source technologies. He combines more than 8 years of IT experience in the field of scalable architectures, distributed systems and developing cloud-native applications, and has worked for different U.S companies such as: Sprint Nextel, Texas Instruments and Nike USA. Nowadays he is encouraging enterprises to join the cloud. Connect with him on LinkedIn.
Alfonso Valdes is the CEO and Founder of ClickIT Smart Technologies, a IT agency focused in the architecture and implementation of Modern Cloud Applications highly resilient in Linux and Open Source technologies. He combines more than 8 years of IT experience in the field of scalable architectures, distributed systems and developing cloud-native applications, and has worked for different U.S companies such as: Sprint Nextel, Texas Instruments and Nike USA. Nowadays he is encouraging enterprises to join the cloud. Connect with him on LinkedIn.
