I recently reading a great Q&A with the Etsy CTO John Allspaw over on The New Stack, which contained some nuggets of good advice that increasingly are important as we continue the journey toward DevOps adoption. Of particular note were statements on the introduction of “new” things to solve problems. In a nutshell, Allspaw reinforced the importance of standardization as a means to reduce architectural debt.
If you aren’t familiar with the concept of architectural debt, it’s similar to technical debt, in which choices made today incur longer term investments of time and money when future changes are introduced. If you settle on a caching solution such as Redis, for example, there are technical and architectural implications. You can’t simply switch out Redis for memcached later without significant changes to both code and the infrastructure.
Even your choice of load balancer today implies architectural debt because of the growing inclusion of scalability as part of the application infrastructure itself. The result is integration with automation and orchestration systems that are not easily changed later on if you decide you want a different solution. The style of service registry you choose is an architectural decision that impacts clients, servers and systems across the microservices architecture. Switching from client-side to server-side will later be costly.
That’s architectural debt.
Allspaw noted the need to not reinvent the wheel when possible, and instead encourage the collaborative aspects of DevOps as a means to avoid reinventing the wheel and potentially increasing the architectural debt load on the organization.
This is not a new concept. There’s a reason enterprises in particular proudly proclaim themselves “Java shops” or “Microsoft shops” and primarily require development in one or perhaps two languages, but no more. Maintainability is a component of technical debt, just as middleware decisions are a component of architectural debt.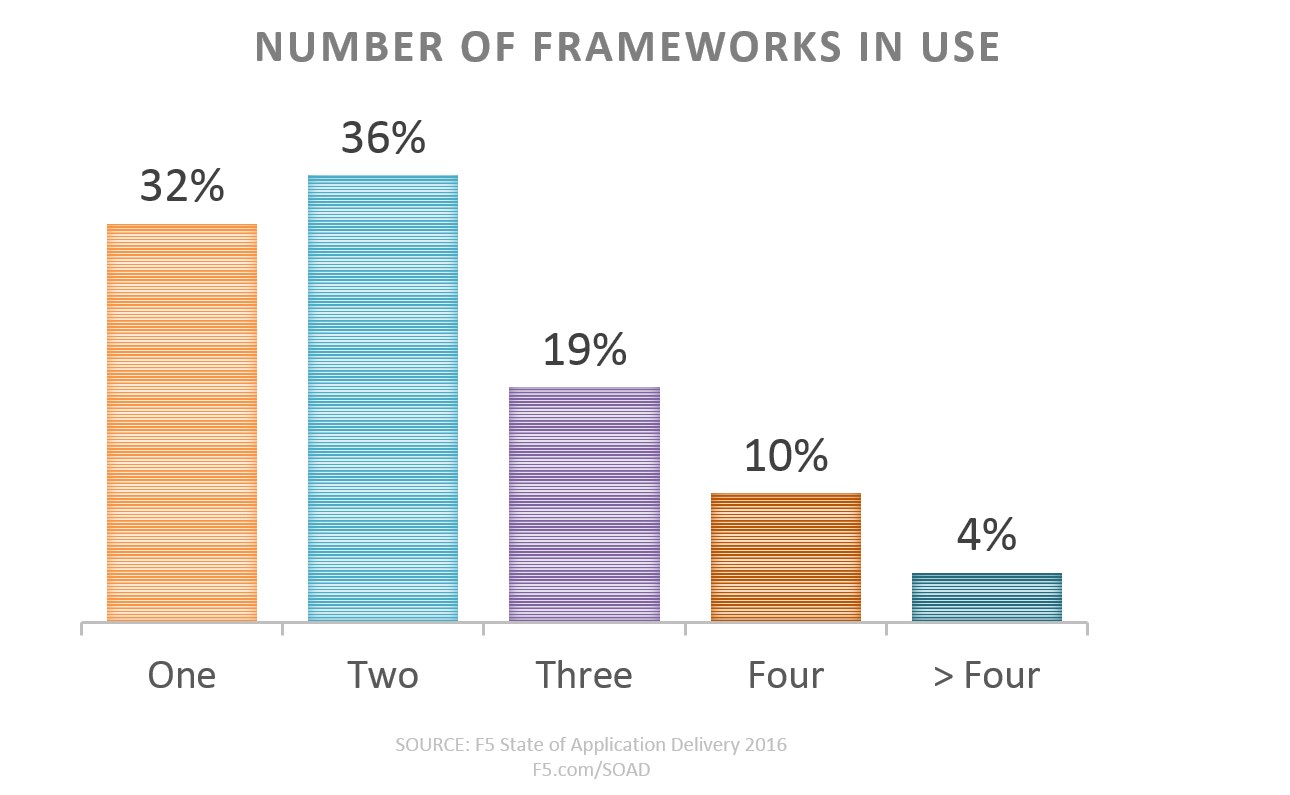
So as we continue to see wider DevOps adoption, it’s important that we carefully consider the impact of our choices in terms of the automation, orchestration and integration required to implement continuous delivery and deployment. Once you’ve invested time and energy (and probably budget, too) in Puppet or Chef, VMware or Cisco, OpenStack or SaltStack, you’re going to find an unavoidable amount of technical and architectural debt in development as well as production across infrastructure and networking teams.
Each of these systems, solutions and frameworks comes with its own components. It isn’t just a language, it’s a comprehensive system with management and repositories and agents and reporting components. All of these impose certain architectural requirements on organizations, from needing certain software running to prescriptive details on networking that must be enforced, lest the system break down.
We’re already starting to see that fragmentation in enterprises that are engaged in automation and orchestration efforts. When asked the number of automation frameworks (Cisco, VMware, Python, OpenStack, Chef, Puppet, etc…) in use, one-third today reported using three or more.
That’s not necessarily “bad,” as it could be indicative of standardization across silos (networking wants to use Cisco, infrastructure is already on VMware, and Python is being used to cobble it together by ops), but it also could be an early sign of the kind of fragmentation that causes exponential growth in technical and architectural debt.
Certainly there is room for experimentation in these early days, but it behooves us to maintain a watchful eye on the use of frameworks and systems and languages we employ for automation and orchestration to ensure we don’t end up buried in technical and architectural debt.
Standardization, even loosely enforced, can help minimize the impact of that debt before it spirals out of control.
