As agile development practices mature and DevOps principles infiltrate our corporate cultures, organizations are realizing the distinct opportunity to accelerate software delivery. However, when you speed up any process, immature practice areas such as testing and roadblocks become much more pronounced. It’s the difference between driving over a speed bump at 5 mph vs. 50 mph … at 50 mph, that speed bump is going to be quite jarring.
Accelerating any business process will expose systemic constraints that shackle the entire organization to its slowest moving component. In the case of the accelerated software development life cycle (SDLC), testing has become the most significant barrier to taking full advantage of more iterative approaches to software development. For organizations to leverage these transformative development strategies, they must shift from test automation to continuous testing.
Drawing a distinction between test automation and continuous testing may seem like an exercise in semantics, but the gap between automating functional tests and executing a continuous testing process is substantial. This gap will be bridged over time as the process of delivering software matures. Both internal and external influences will drive the evolution of continuous testing. Internally, agile, DevOps and lean process initiatives will be the main drivers that generate the demand for change. Externally, the expense and overhead of auditing government and industry-based compliance programs will be the primary impetus for change.
A Roadmap for Testing
Any true change initiative requires the alignment of people, process and technology—with technology being an enabler and not the silver bullet. Yet there are some basic technology themes we must explore as we migrate to a true quality assurance process. In general, we must shift from a sole focus on test automation to automating the process of measuring risk. To begin this journey, we must consider the following:
Driven by business objectives, organizations must shift to more automated methods of quality assurance and away from the tactical task of testing software from the bottom up.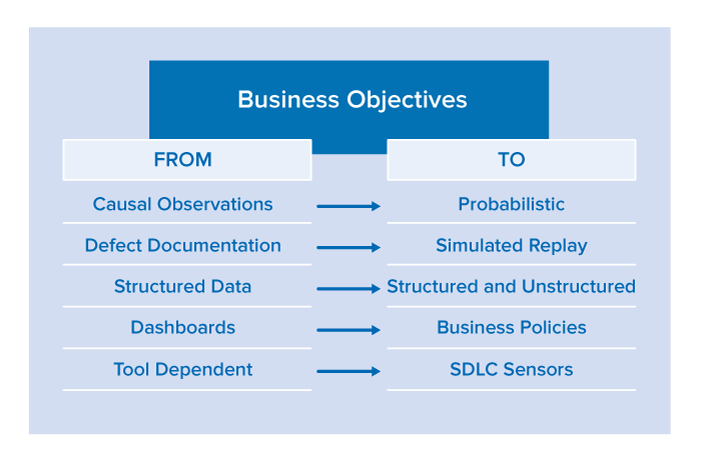
From Causal Observations to Probabilistic Risk Assessment
With quality assurance (QA) traditionally executing manual or automated tests, the feedback from the testing effort is focused on the event of a test passing or failing—this is not enough. Tests are causal, meaning that tests are constructed to validate a very specific scope of functionality and are evaluated as isolated data points. Although these standalone data points are critical, we must also use them as inputs to an expanded equation for statistically identifying application hot spots.
The SDLC produces a significant amount of data that is rather simple to correlate. Monitoring process patterns can produce very actionable results. For example, a code review should be triggered if an application component experiences all of the following issues in a given continuous integration build:
- Regression failures greater than the average
- Static analysis defect density greater than the average
- Cyclomatic complexity greater than a prescribed threshold
From Defect Documentation to Simulated Replay
The ping-pong between testers and developers over the reproducibility of a reported defect has become legendary. It’s harder to return a defect to development than it is to send back an entrée from a world-renowned chef. Given the aggressive goal to accelerate software release cycles, most organizations will save a significant amount of time by just eliminating this back and forth.
By leveraging Service Virtualization for simulating a test environment and/or virtual machine record and playback technologies for observing how a program executed, testers should be able to ship development a very specific test and environment instance in a simple containerized package. This package should isolate a defect by encapsulating it with a test, as well as give developers the framework required to verify the fix.
From Structured Data to Structured and Unstructured
The current tools and infrastructure systems used to manage the SDLC have made significant improvements in the generation and integration of structured data (e.g., how CI engines import and present test results). This data is valuable and must be leveraged much more effectively (as we stated above in the “From Causal Observations to Probabilistic” section.
The wealth of unstructured quality data scattered across both internal and publicly-accessible applications often holds the secrets that make the difference between happy end users and unhappy prospects using a competitor’s product. For example, developers of a mobile application would want constant feedback on trends from end user comments on:
- iTunes app store
- Android app store
- Stackoverflow
- The company’s release announcements
- Competitors’ release announcements
This data is considered unstructured since the critical findings are not presented in a canonical format: parsing and secondary analysis are required to extract the valuable information. Although these inputs might be monitored by product marketers or managers, providing these data points directly to development and testing teams—in terms that practitioners can take action on—is imperative.
From Dashboards to Business Policies
In a Continuous Everything world, quality gates will enable a release candidate to be promoted through the delivery pipeline. Anything that requires human validation clogs the pipeline. Dashboards require human interpretation—delaying the process.
Dashboards are very convenient for aggregating data, providing historical perspectives on repetitive data, and visualizing information. However, they are too cumbersome for real-time decision making because they do not offer actionable intelligence.
Business policies help organizations evolve from dashboards to automated decision making. By defining and automatically monitoring policies that determine whether the release candidate is satisfying business expectations, quality gates will stop high-risk candidates from reaching the end user. This is key for mitigating the risks inherent in rapid and fully-automated delivery processes such as Continuous Delivery.
From Tool Dependent to SDLC Sensors
Let’s face it—it’s cheap to run tools. And with the availability of process intelligence engines, the more data observations we can collect across the SDLC, the more opportunities will emerge to discover defect prevention patterns.
Given the benefit of a large and diverse tool set, we need to shift focus from depending on a single “suite” of tools from a specific vendor (with a specific set of strengths and weaknesses) to having a broad array of SDLC sensors scattered across the software development life cycle. And to optimize both the accuracy and value of these sensors, it’s critical to stop allowing tools to be applied in the ad hoc manner that is still extremely common today. Rather, we need to ensure they are applied consistently and that their observations are funneled into a process intelligence engine, where they can be correlated with other observations across tools, across test runs and over time. This will not only increase the likelihood of identifying application hot spots, but will also decrease the risk of false negatives.
About the Author/Wayne Ariola
 Wayne Ariola, Chief Strategy Officer, leads the development and execution of Parasoft’s long-term strategy. He leverages customer input and fosters partnerships with industry leaders to ensure that Parasoft solutions continuously evolve to support the ever-changing complexities of real-world business processes and systems. Ariola has contributed to the design of core Parasoft technologies and has been awarded several patents for his inventions. A recognized leader on topics such as service virtualization, SOA and API quality, quality policy governance, and application security, Ariola is a frequent contributor to publications including software test & performance, SOA World, and ebizQ—as well as a sought-after speaker at key industry events. Ariola brings more than 20 years strategic consulting experience within the technology and software development industries.
Wayne Ariola, Chief Strategy Officer, leads the development and execution of Parasoft’s long-term strategy. He leverages customer input and fosters partnerships with industry leaders to ensure that Parasoft solutions continuously evolve to support the ever-changing complexities of real-world business processes and systems. Ariola has contributed to the design of core Parasoft technologies and has been awarded several patents for his inventions. A recognized leader on topics such as service virtualization, SOA and API quality, quality policy governance, and application security, Ariola is a frequent contributor to publications including software test & performance, SOA World, and ebizQ—as well as a sought-after speaker at key industry events. Ariola brings more than 20 years strategic consulting experience within the technology and software development industries.
