Honeycomb has made generally available an extension to its observability platform that provides the ability to analyze front ends of applications.
Company CEO Christine Yen said that capability eliminates the need to deploy, for example, a separate real user monitoring (RUM) tool to troubleshoot the front end of an application. That approach ultimately reduces the total cost of managing an application environment in part by leveraging open-source OpenTelemetry agents to collect a wider range of data, she added.
Honeycomb achieves that goal by making use of an OpenTelemetry wrapper to instrument the front end of an application in a way that makes it possible to collect performance data, trace and other custom attributes that DevOps teams can define.
The Honeycomb platform then analyzes that high-cardinality data alongside the back-end application to provide more holistic insights into the application environment, Yen noted. Previously, IT teams would have needed to separate RUM and application performance management (APM) platforms that they then would have to integrate themselves, noted Yen. That approach is fundamentally inefficient because both platforms are essentially collecting different types of telemetry data that should be analyzed on a single platform, she added. The Honeycomb approach is designed to eliminate the divide that exists between the management of front and back ends of applications, noted Yen.
Honeycomb is designed to make it simpler to declare which events DevOps teams want to analyze, and then pull all the raw data associated with those events into a Honeycomb cloud service where analytics is applied. That approach makes it simpler for DevOps teams to move beyond basic monitoring of a set of pre-defined metrics, in favor of an observability platform they can query to better ascertain the root cause of an issue.
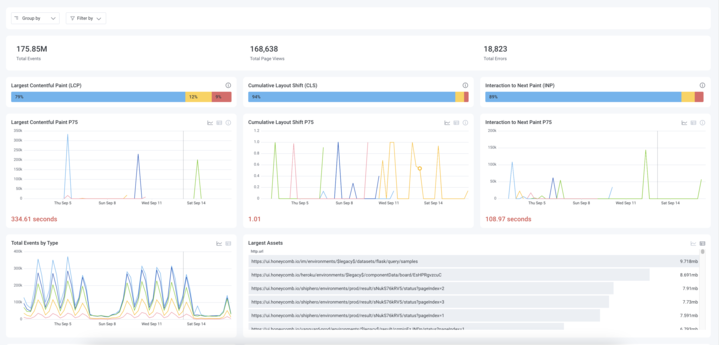



It’s still early days as far as the adoption of observability platforms is concerned. However, it’s apparent that as application environments become more complex, the plethora of monitoring tools that most IT teams rely on need to be superseded by platforms that make it possible to investigate and correlate anomalous events.
The rate at which IT teams embrace observability naturally varies, but the biggest immediate obstacle might not be the platforms themselves. Understanding what queries to craft to surface the root cause of an IT issue before there is a major disruption requires a level of expertise that is often challenging to find and retain. Fortunately, as machine learning algorithms and generative artificial intelligence (AI) capabilities are added to these platforms, the level of expertise required to effectively use them continues to decline.
As IT environments continue to become more complex, it’s more a question of the degree to which organizations will be embracing observability rather than if they will do so. As a core tenet of DevOps best practices, IT teams that programmatically manage IT environments tend to be at the forefront of the adoption of these platforms. The challenge and the opportunity now is to take observability to the next level before DevOps teams become even more overwhelmed than many of them already are.
