Elyra AI Toolkit is a new open source project that extends the JupyterLab user interface to simplify the development of data science and AI models.
- Notebook Pipelines visual editor
- Ability to run notebooks as batch jobs
- Hybrid runtime support (based on Jupyter Enterprise Gateway)
- Python script execution capabilities within the editor
- Notebook versioning based on Git integration
- Reusable configuration for runtimes
We’re excited to announce Elyra and help evolve the Jupyter ecosystem with new tools for AI model development.
“I’m excited to see IBM engaging with the Jupyter and scientific open source communities with their ongoing contributions in this area. As much as AI tools rely on vast amounts of data and computational resources, the human in the loop remains the critical element for both asking the right questions and making decisions responsibly. That’s where Jupyter plays a role, and I’m delighted to see new tools like Elyra that will help AI workflows within the Jupyter ecosystem.” — Fernando Pérez, Project Jupyter co-Founder and co-Director
Notebook pipelines
Building an AI pipeline for a model is hard. Breaking down and modularizing a pipeline is harder. A typical machine and deep learning pipeline begins as a series of preprocessing steps followed by experimentation, optimization, and, finally, deployment. Each of these steps represents its own unique challenge in implementation, execution, scheduling, and operation when bringing deep learning models from development to production.
Elyra provides a visual editor for building Notebook-based AI pipelines, simplifying the conversion of multiple notebooks into batch jobs or workflows. By leveraging cloud-based resources to run their experiments faster, the data scientists, machine learning engineers, and AI developers are then more productive, allowing them to spend their time using their technical skills.
The following image shows the Elyra Canvas component that enables the pipeline visual editor. The Canvas user interface was originally developed as part of IBM Watson Studio and is now being open sourced as part of Elyra. So, existing IBM Watson Studio and IBM SPSS Modeler users should feel comforable with Elyra.

Elyra also extends the Notebook UI to simplify the submission of a single Notebook as a batch job, as the following image shows.

Hybrid runtime support
Elyra takes advantage of the work that we’ve done with Jupyter Enterprise Gateway to enable Jupyter Notebooks to share resources across distributed clusters such as Apache Spark, Kubernetes, and OpenShift.
It simplifies the task of running the notebooks interactively on cloud machines, so you can use the power of cloud-based resources that enable the use of specialized hardware such as GPUs and TPUs.

Python script execution support
Leveraging the hybrid runtime support, Elyra exposes Python Scripts as first-class citizens, allowing users to locally edit their scripts and execute them against local or cloud-based resources seamlessly.

Versioning based on Git integration
The integrated support for Git repositories makes tracking changes easier, allowing users to roll back to working versions of the code, backups, and, most importantly, sharing among team members. This collaborative working environment fosters productivity.
Reusable configuration for runtimes
Elyra introduces a ‘shared configuration service’ that simplifies workspace configuration management, enabling things like information around accessing external runtimes to be configured once and shared across multiple components.
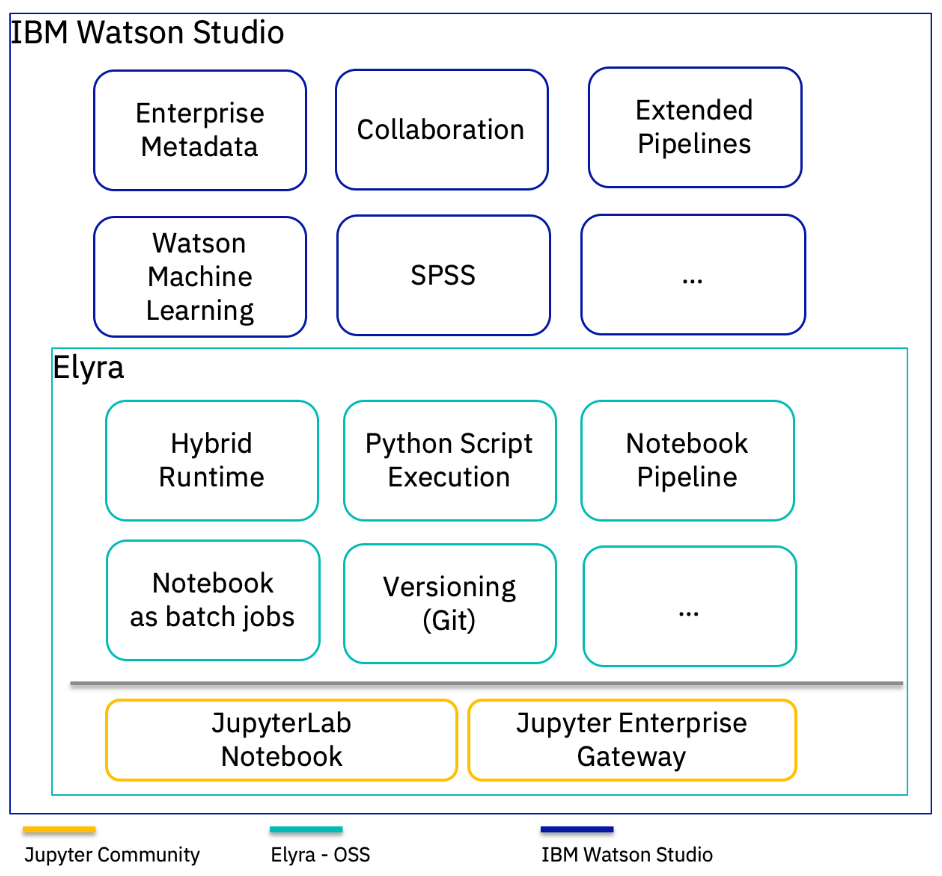
Elyra and IBM Watson Studio
IBM recently announced new releases of IBM Cloud Pak for Data and Watson Studio which added JupyterLab as a richer way to work with Notebooks, in addition to classic Jupyter Notebooks. The current version of Watson Studio already provides versioning based on Git integration and is continuing to work with the open source community to incorporate other Elyra extensions.
Summary
Building on a Jupyter Notebooks foundation, the de facto tool for data scientists, machine learning engineers and AI developers, Elyra provides a toolkit designed to help around model development tasks complexity.
Previously, the work on Jupyter Enterprise Gateway addressed the challenges around scaling enterprise workloads, and now Elyra addresses the challenges of making workload development easier. In addition, IBM is contributing to TensorFlow, PyTorch, Spark, KubeFlow, KubeFlow Pipelines, ONXX, and Egeria to address an even broader set of enterprise data and AI development challenges.
We would love for you to get involved with the project. Read our contributing guidelines, create new issues if you have questions, suggestions for new features or in case of any problems. We also welcome contributions via GitHub pull requests.
