Not long ago, developers at LeanTaas implemented an on-demand feature environment. It came about as the result of a collaborative effort to support a faster go-to-market strategy. Moving to an on-demand feature environment resulted in greater agility, effectiveness, quality and a better bottom line for the organization. With careful implementation, any development team can benefit from this exercise.
With an on-demand feature environment, you can easily test specific features without disrupting development activities that already are in process. Setting up the environment can offer several benefits and enhance the overall outcomes of your product release. Here, we’ll walk through the steps we took to get this implemented.

First, we decided to come up with some standards and changes in our development practices:
Naming Conventions
Every Git branch name should start with the associated Jira ticket and include details about what that branch is for. We updated the Jira ticket with environment URLs, automated QA test results and comments from product manager reviews.
Syntax:
<JIRA_TICKET>-<SHORT_TITLE>-<PRODUCT_NAME>.<DOMAIN_NAME>.com |
For example, LT-123-demo-product1.xxxx.com
In this case, LT-123 is the Jira ticket, demo is the short title, product1 is the product name and xxxx is the domain name. So, our feature branch URL would be accessible at https://lt-123-demo.product1.xxxx.com, and the internal name would be dev-product1-lt-123-demo, which developers can use to ssh and debug issues (if any) and refer to when they check logs (if necessary).
Also, following a set naming pattern helps us write a regular expression in a front-facing server environment (we use NginX) that helps proxy/route the requests to the respective feature-specific runtime environments deployed in an AWS EC2 instance.
If you are using NginX, you can use following regex to achieve this:
server_name ~^(?<featurebranch>.+)\-product1\.xxxx\.com$; set $featurebranch dev-product1-$featurebranch proxy_pass https://$featurebranch; |
Data and Microservice Dependencies
For the environment to work in its own isolated state, it needs a data set stored in its own database. So our teams came up with an automation script for generating an anonymized sample dataset that’s required for this feature instance. We packaged this data, along with other required artifacts, into a golden Amazon Machine Image (AMI) for the specific product. For easy reference, we stored this custom AMI ID in the AWS systems manager (SSM) parameter store so that our Terraform scripts can use this reference while spawning an EC2 instance.
Once the feature-specific instance came up, we realized it couldn’t play well with our other microservices such as authentication, authorization or notification. They couldn’t differentiate between a real product instance versus a short-lived, feature-specific instance. So, we had to add an additional header in our internal requests, and enhanced these other microservices to be aware of this additional header so that they could exactly respond back to a feature specific instance. When it comes to usage of message services, every feature branch has its own SQS queue, which followed the same naming conventions of the internal hostname. Platform services relied on this same standard to ensure these feature branches worked seamlessly.
Automation/Manual Quality Checks and PM Reviews
Now that the feature-specific instance is up and running in its own isolated environment and with its own dataset, it enables a fully functional playground for the QA team and PM team to extensively test new features in an isolated fashion. Having this playground is a game changer for our productivity. It helped parallelize the iteration cycles. Each feature started getting its own feedback and progressing towards the finish line; essentially swimming in their own lane.
Cost Considerations
So far, so good. Feature-specific application instances are up and running and development iterations are progressing. But what is the lifetime of these instances? We don’t want to let them run forever; we also want to consider the fact that not every new feature will end up getting released. So, how do we handle such cases? We want to hook up these instance termination actions seamlessly into the developer’s work stream. Here’s how we solved for this:
- Delete the feature branches-related infrastructure as soon as the feature branch itself is deleted.
- Stop the EC2 instances every night and start them every morning by using a combination of AWS Cloud Watch Events and Lambda.
- Automatically delete the feature branches that are active for more than seven days. We later ended up providing an additional feature; skip flag, for some feature branches because sometimes we’d end up making changes that were complicated or revamping things which needed more time.
Notifications
We use Slack, so we decided to send Slack notifications every time a feature environment was created and attach test results, as a thread, to the same Slack message.
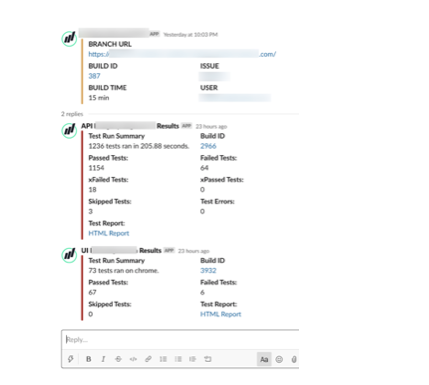
We also decided to use AWS tags and maintain branch_owner (developer name), branch_status (synced with Jira to indicate In-Dev, In-QA, PM Review, Code Review etc.) and tag EC2 instances. We also sent a daily report with the number of active branches, which helped in our daily standup and also provided a quick, at-a-glance overview of features that were ready for release.
For implementation of CI/CD pipelines, we created a new Jenkins pipeline that had the ability to perform some prereq checks, code quality checks, build applications into Docker containers, spin up infrastructure using Terraform and deploy the Docker container into newly created infrastructure using Ansible, run automation tests against the feature environment and send notifications in Slack as well as update Jira tickets with the build URL and test results.

Sample screenshot of our pipeline

Once our feature environment was certified, then a pull request is submitted to merge in Master, before merging code review is performed by other developers and engineering leads, and then, finally, merged into Master. Once the feature branch is merged into Master, it gets deleted via a webhook.

Now, code is built against the master branch and deployed into the master environment to ensure integrity. We perform one more round of QA using automated and manual checks, regression testing, internal penetration testing and performance testing. Once these are passed, the Docker image is finally promoted to production.
Following these steps to a seamless implementation of an on-demand environment will help any organization take the same steps towards a more efficient process. If you can apply these steps to your workflows, your metrics could improve exponentially.
