InfluxData today made available an update to its open source time series database that can now analyze metric, event and trace data in a single datastore with unlimited cardinality in terms of how they are aggregated.
The company is now making available a single-tenant instance of InfluxDB as a managed service alongside its already-existing multi-tenant cloud service that is based on a serverless architecture.
Finally, InfluxData also announced that later this year it will make available InfluxDB 3.0 Clustered and InfluxDB 3.0 Edge to provide a curated version of the database that organizations can deploy themselves where they best see fit.
InfluxData CEO Evan Kaplan said InfluxDB has been developed to support a wide range of emerging applications that require access to time series data, including the observability platforms core to DevOps workflows that require visibility into metrics, events and trace data.
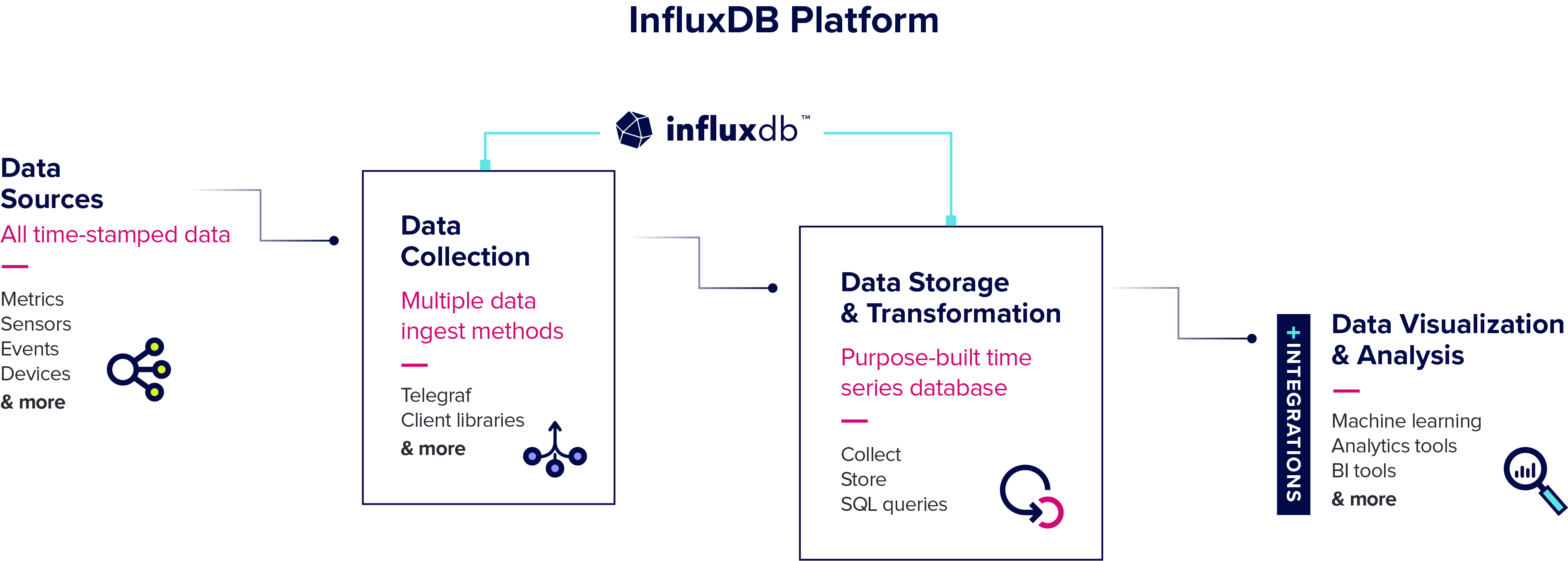
Over the past three years, InfluxDB has been revamped to run on a columnar engine, dubbed IOx, that leverages the open source Apache Arrow memory format and written in the Rust programming language. Kaplan said that approach makes it possible to continuously ingest, transform and analyze hundreds of millions of time series data points per second without limitations.
At the same time, InfluxDB takes advantage of high compression object storage to reduce the total cost of storing all that data. It also provides interoperability with Open Data Architecture (ODA) to integrate with data lakes based on open source platforms such as DataFusion, Flight SQL and Parquet that are being advanced by the Apache Software Foundation.
The arrival of version 3.0 of InfluxDB comes as many DevOps teams are starting to struggle with the amount of observability data being generated. DevOps teams want to be able to move beyond monitoring a set of pre-defined metrics and query data in a way that enables them to surface anomalies indicative of a potential issue before there is a major disruption to an application service.
One of the major challenges today is the tradeoff between how much data is collected and analyzed versus the cost of processing and storing it. InfluxDB provides a mechanism for analyzing high cardinality data involving metrics, events and traces cost-effectively.
Observability is, of course, only one of several use cases for a time series database capable of processing data in near-real-time. As organizations embrace digital business transformation initiatives, they need to be able to process data in near-real-time at the point where it is being created and consumed. Those applications won’t necessarily replace existing applications based on batch-oriented processing but, over time, they create two distinct classes of applications that process data in fundamentally different ways. The challenge, as always, will be defining the DevOps workflows required to manage applications running on multiple distinct types of architectures.
