Iterative added a registry for machine learning models to its portfolio of Git-based tools for infusing artificial intelligence into applications.
Iterative CEO Dmitry Petrov said the Iterative Studio Model Registry is intended to make it easier for application development teams to track which models are being used as the number of applications infused with AI capabilities continues to grow.
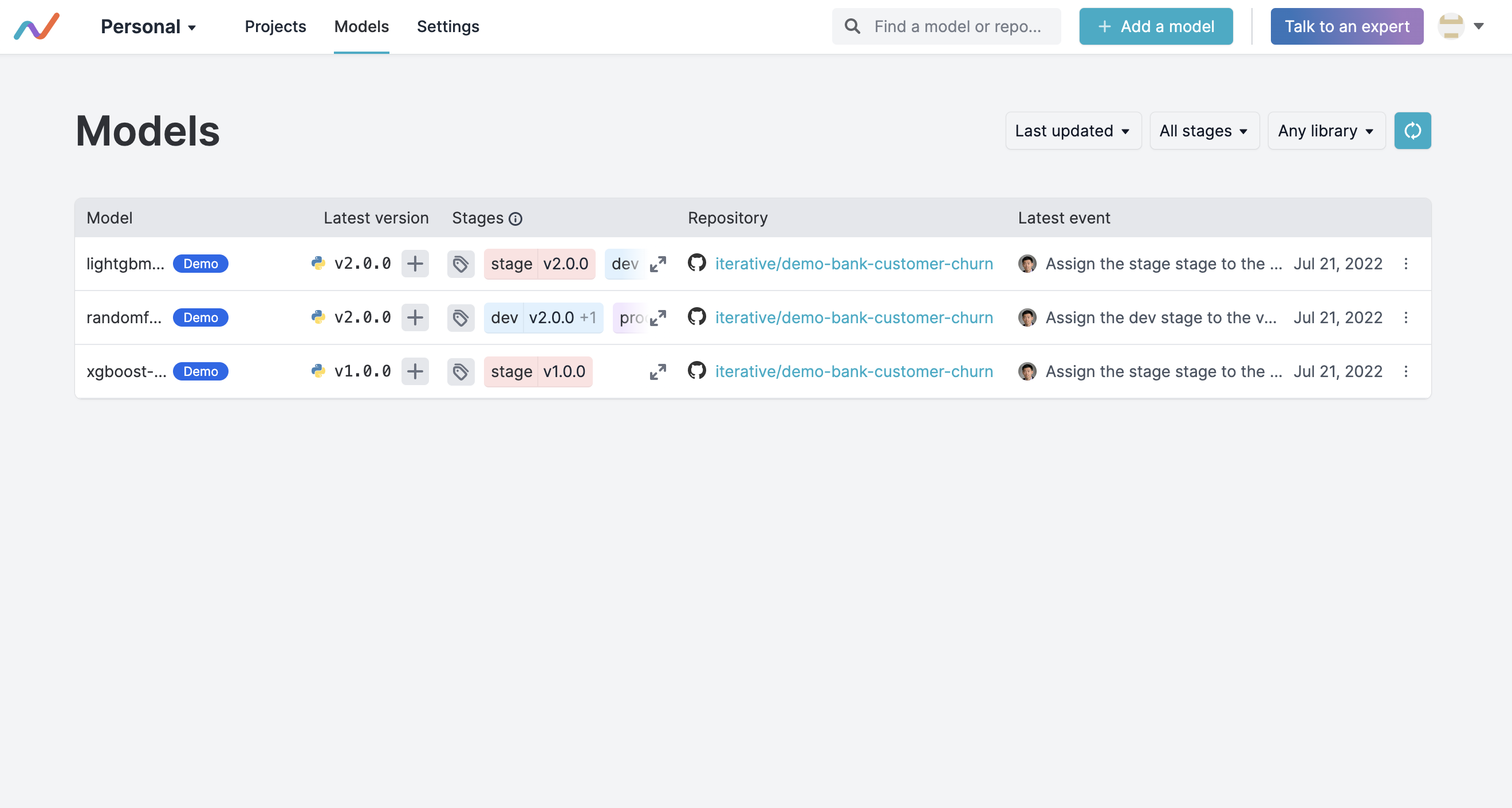
The Iterative Studio Model Registry, accessible via a graphical interface, command line interface or application programming interface (API), makes it simpler to explore models, including history, versions and stages, via a central dashboard. Teams can also identify the experiment that produced the model and track how, when and by whom a model version was created.
The Data Versioning Control (DVC) platform created by Iterative exposed a Git-like interface to enable organizations to track multiple versions of data sets, models and pipelines across a machine learning operations (MLOps) workflow. That approach enables those models to be stored in a Git repository alongside other software artifacts versus requiring organizations to deploy a separate platform just to store ML models.
Providers of platforms used by data science teams have been making a case for separate repositories for tracking the artifacts used to construct an AI model. Iterative contends it is more efficient to employ Git repositories where other types of software artifacts are already being stored because, after all, an ML model is just another type of software artifact.
That approach also makes it simpler for DevOps and data science teams to collaborate because the DevOps team will have more visibility into what AI models will eventually need to be incorporated into an application, noted Petrov.
The challenge organizations face is the cultural divide between data science and application development teams. Data science teams today typically have defined their own workflow processes using a wide range of graphical tools. However, as it becomes obvious that almost every application is going to be infused with machine learning and deep learning algorithms to some degree, the need to bridge the current divide between DevOps and data science teams will become more acute.
In fact, DevOps teams should assume that many more AI models are not only on the way but that those models will need to be continuously updated. Each AI model is constructed based on a set of assumptions; however, as more data becomes available, AI models are subject to drift that results in less accuracy over time. Organizations may even determine that an entire AI model needs to be replaced because the business conditions on which assumptions were made are no longer valid. One way or another, the updating and tuning of AI models are likely to soon become just another continuous process being managed via a DevOps workflow.
No IT organization can, of course, manage what it can’t track. Registries have become an essential component of a DevOps workflow as the volume of types of artifacts that make up application environments has increased. It remains to be seen to what degree ML models become just another software artifact but one way or another someone in the IT organization needs to know what model is being employed in which application for what purpose.
