Software development is undergoing industrialization, with more and more software rapidly assembled out of components and an emphasis on building automation around software validation and release processes.
Modern cloud-native software is no longer a monolithic application living in a single repo with the majority of its dependencies self-contained. It is integrated from third-party components provided by vendors, cloud providers and open source software (OSS) components, with as much as 90% of code coming from such dependencies. This allows developers to build applications much faster but makes maintenance much harder as it is no longer entirely under their control. If the third-party vendor makes a change to their API, developers are on the hook to update their applications before they break.
Each microservice interacts with hundreds of other microservices and each is built and released independently, making it hard to understand how to coordinate API changes across them. For example, if you want to make an API change to a microservice, what impact will this have on the consumers in the organization? Who will need to coordinate the change? When it was all within the same repository and released all at once, it was much easier to make such changes.
The Changing Nature of Technical Debt
What we continue to call technical debt is really the activities that are related to tending to and upgrading our software when third-party components are evolving or have common vulnerabilities and exposures (CVEs) and need to be upgraded.
These are tedious, repetitive tasks that usually fall to the most experienced engineers as they require technical expertise to do correctly. Such activities can paralyze engineering organizations and are a tremendous burden on engineers; that often leads to burnout. Up to 30% of engineering time is spent on technical debt. The perception that somehow developers were responsible for accruing this technical debt and are doing something wrong that prevents them from keeping up is hugely demoralizing and demotivating.
However, if we reframe technical debt as software supply chain management and stop blaming engineering for it, we can make maintenance more predictable and consistent. By taking steps like inventorying third-party components and determining how pervasive they are in the application (frameworks take more effort to maintain than a third-party API that you just call from one part of the application), an organization can arrive at a maintenance estimate.
These activities are highly repetitive across organizations, as everyone is integrating some subset of the same third-party components to create business value. This high level of repeatability points us to automation.
Specialized Developer Tools for Software Maintenance Don’t Exist
When developers write code, their hands often lag behind their thoughts. They think much faster than they are able to type the code. You often hear developers finishing a tedious task and complaining, “My fingers hurt.” When their IDE can autocomplete syntax, it helps reduce this lag to minutes.
When a major framework version is released, developers contemplate the codebase. Maybe they need to change this type to that, reorder some method arguments or change dependencies. The types of changes they need to make are enumerable and must be made almost immediately; again, the ability to implement them lags far behind their recognition of the problem. Often, this type of lag can represent months or years of work when dealing with a large codebase. Accumulate enough of this lag and the codebase can grind to a halt.
That lag kills the joy in development for most senior developers and leads to burnout. Upgrades/migrations amplify that lag by orders of magnitude.
However, there are few (if any) tools that focus on helping developers automate these remediations/upgrades/migrations. The IDE’s focus is rightly on helping developers write new code and maintain their own code, but code maintenance needs to be coordinated across multiple places across the codebase, within the same repository or across the repository boundaries. Often, developers have a pattern they want to change in their repository, but the IDE only suggests this as an improvement in their current location (one file). Other times, changes need to be coordinated across repository boundaries if developers want to change APIs and their consumers. That’s why this technology needs to exist outside of the IDE.
OpenRewrite
OpenRewrite is an open source project that offers semantic analysis and refactoring of code as standalone operations so that everyone can use and contribute over time; composing more and more refactoring operations that make whole framework migrations possible. It is integrated with build tooling and can be plugged into different workflows, from CI integrations to mass refactoring of multiple microservices/repositories. Similar to an IDE or other developer tools, OpenRewrite manipulates an abstract syntax tree (AST) representation of code, but this AST has special characteristics that allow it to transform this AST and generate code back to the standard text representation.
The OpenRewrite AST is produced by guiding the compiler through the first two phases of compilation to generate compiler type-attributed AST. This is then mapped to the OpenRewrite AST, preserving formatting and breaking cycles in the AST. The three unique characteristics of OpenRewrite AST are:
- Type aware, allowing 100% correct semantic code analysis and transformation.
- Style-preserving, so transformations produced are idiomatic within the projects they are applied to. So, the same transformation applied to multiple projects will potentially look different.
- Serializable, allowing to output the AST from the build and operate on it outside of the build en masse.
OpenRewrite ASTs is full of metadata about code. Visualizing the code itself as a highly connected tree of various vertices and edges, we can start to get an idea of the density of this representation. Syntactic elements alone are blue, type attribution is yellow and formatting information is red. If we were to just represent syntactic elements, the tree might look something like this.
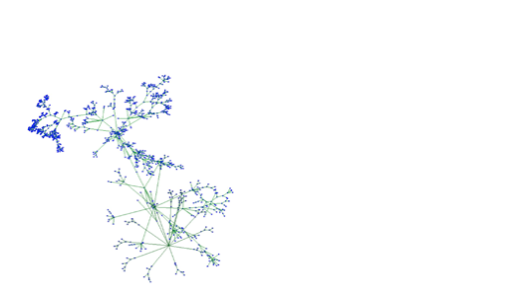
Adding type attribution and formatting, the tree looks quite a bit denser.

A spanning tree of the data involved in this AST can be laid out in three-dimensional hyperbolic space and then projected onto the unit sphere similar to the way that two-dimensional space can be projected onto a disk—the famous Poincaré disk model. This three-dimensional approach was pioneered by Tamara Munzner at Stanford.
Every edge that isn’t part of the spanning tree is rendered as a lighter gray, and, as you can see, it is dense! In fact, to make this layout more tractable, we’ve omitted in this view an additional 600,000 vertices representing type information that make the syntax itself seem tiny.
OpenRewrite calls a single code search or transformation operation a recipe. It provides a number of building block recipes such as find method, change method, find transitive dependency, upgrade or exclude dependency. These recipes, in turn, can be composed into more complex recipes by grouping them together into a composite recipe. When the building blocks are not enough, a recipe can be written as a program in the same language as the code we want to transform, allowing us to encapsulate complex logic with the full expressiveness of the language already familiar to developers. We don’t need to learn a new DSL or programming language.
These building blocks abstract away many of the details to ensure that edits that we make to source code obey the original style of the project. This is possible for even complex changes like this automated migration from Spring Boot 1.x @ConditionalOnBean to Spring Boot 2.x AnyNestedCondition looks idiomatically consistent in the context of the project that it is inserted into:
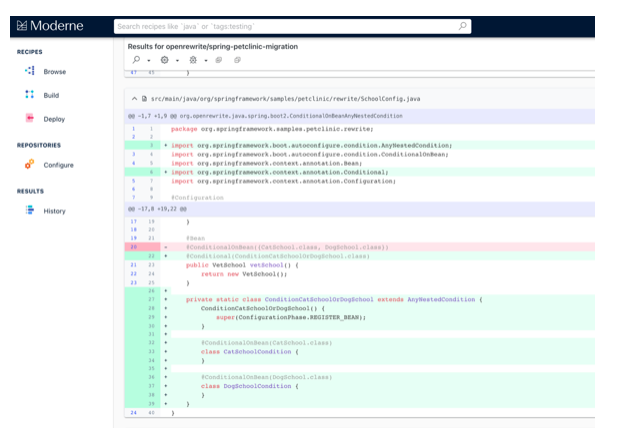
It is important to note that OpenRewrite is not a replacement for an IDE. With software now composed of so many independent components, we need to start to remediate and manage it using new approaches that go beyond single lines of code to looking across entire code repositories.
Olga Kundzich, co-founder of Moderne, co-authored this article.
