Sourcegraph and Dimensional Research have released a survey of developers at large organizations, which shows a massive growth in codebase size, number of repositories in use and complexity concerns.
“The Emergence of Big Code – A 2020 Survey of Software Professionals” is definitely intriguing reading, and a few of the results are eye-opening—such as the difference between what development managers think developers are using to search code and what developers say they are actually using. But most of it simply validates what we all knew: Codebases are growing at an alarming rate, through a variety of growth vectors—support for new platforms, use of open source and internal development. Adding environment to code à la GitOps, systems reliability engineering and/or environment automation is adding a layer of completely new source and a layer of complexity not normally in the developer’s realm of immediate concern.
I’ve been working with Accelerated Strategies Group over the last few months, and we’re looking at tools in this market. The ability to quickly get up to speed on large codebases and the ability to find a specific area in a codebase that is massive and/or spans repositories is a very real need that is not currently well-served. This piques my interest in what Sourcegraph brings to the table, but at the moment we’re focused on the survey, so perhaps in a future blog we’ll talk about Sourcegraph.
While there is a lot packed into the survey, I think my favorite part is crammed in with other “What would you find useful?” results (the slide is below). Fifty-eight percent of respondents—all of whom are developers—chose, “Finding code by querying semantic relationships, not just matching a string.” As developers, these respondents no doubt are aware of the complexities of this type of feature, particularly in environments with a variety of programming languages and scripts (be they bash, SQL, whatever) all working together. This is huge, and first iterations would be shallow, but is a worthy goal. I’m intrigued to see how well SourceGraph et al solve it.
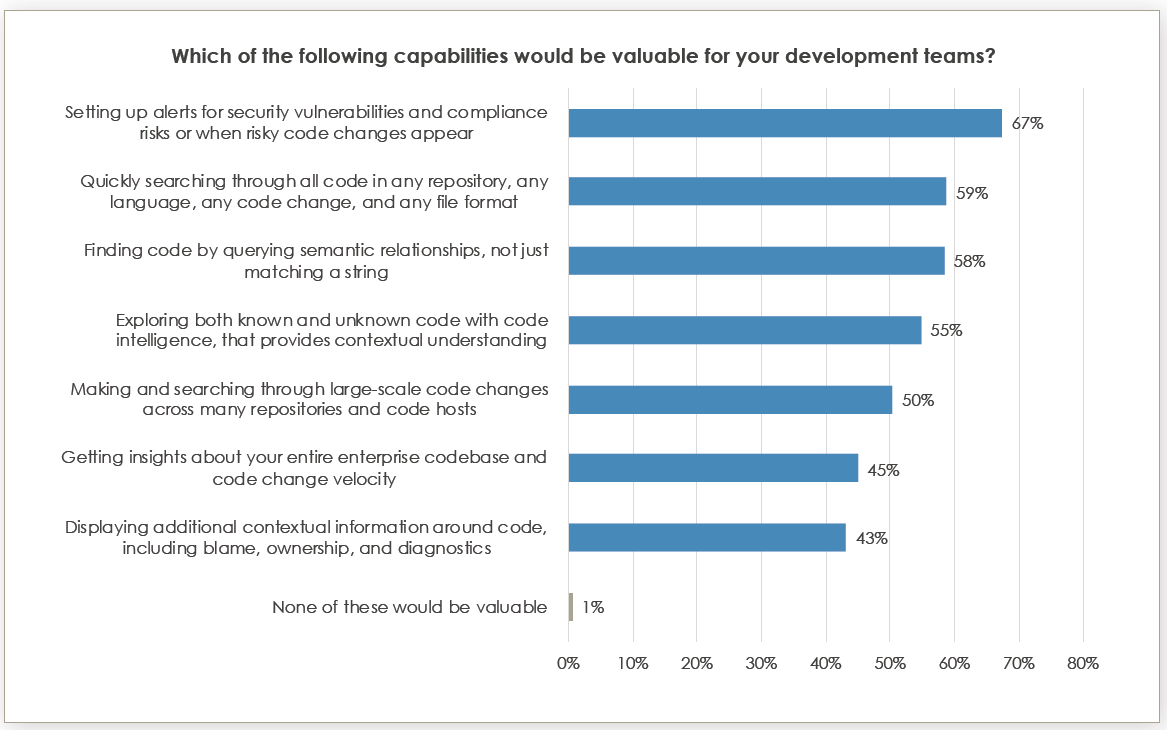
It is also intriguing to see more than half of respondents want the ability to explore ” … both known and unknown code with code intelligence that provides contextual understanding.” That, too, is a tall order. Code analysis has gotten better over time, but contextual analysis of large codebases is notoriously difficult. I’ll be intrigued in the near future to play with this concept and tools that offer it to see how reliable they are and how much human guidance is accepted and/or required to make it a reality.
Code change velocity reporting and contextual information about code are both available and pretty solid from the majority of full-stack DevOps vendors. Perhaps that is why that particular response only netted 45% and 43% of responses, respectively—the other 50+% are already using them.
We’re in an interesting time when consolidation appears to be on the upswing and the needs of developers and DevOps teams working in large codebases are becoming more clear and more complex at the same time. Over the next few years the needs reported in this survey will likely be replaced by more specific needs as these are fulfilled and find general use. The question of databases and database integration in large codebase migrations, for example, has these needs, but has other needs closer to the problem domain. As these general issues are resolved, expect your vendors to turn to those more specific, but every bit as complex, problems.
And just keep rocking it. Find out what the tools and companies already in use at your org have added, and if those capabilities fit with your needs or can enhance your Dev/DevOps exercises. Keep the lights on, keep customers happy and watch for tools to help you make it even better.
