IT operations teams, site reliability engineers (SREs) and service providers are on a mission to scale across geographies, expand their digital services and create new experiences for customers. Amid this drive, their backend IT systems are getting more complex. This hinders visibility into applications and makes monitoring and troubleshooting cumbersome. With heightened competition in the market, businesses cannot afford to take hits on revenue or customer experience scores due to issues stemming from their IT stack, such as unknown outages, increased incident management times and data replication.
Infusing artificial intelligence capabilities into IT operations (AIOps) can raise efficiency through automation, improve security and make a significant impact in warding off downtime. AIOps uses machine learning (ML) to enhance IT operations such as performance monitoring, event correlation and analysis. With AIOps, IT teams, SREs and service providers can predict and prevent outages before they occur and resolve them automatically. Moreover, AIOps uses ML to analyze current and past data to make precise predictions, reducing costs and speeding up return on investment (ROI).
AIOps Implementation
Launching AIOps requires a unique approach depending on your organization, its capabilities and needs. This article provides a three-step implementation strategy to help your organization detect incidents before they impact users, automate responses and prevent recurring issues.

Fig: AIOps implementation approach
With the advanced ability to collect and analyze IT operational data, AIOps is an asset for a range of actions and solutions. When implemented effectively, AIOps can enable IT teams, SRES and service providers to significantly reduce application outage costs by over 60% within a span of 24 months.
Getting Started With AIOps: Predicting Outages in Applications and Infrastructure
The AIOps platform can be leveraged by IT teams, SREs and service providers for data gathering, analysis and generation of useful insights. It is designed to enhance operational efficiency, offer predictive alerts, reduce mean-time-to-identify (MTTI) and mean-time-to-repair (MTTR) as well as prevent service outages.
Recommendations
- Prioritize onboarding mission-critical applications, such as network monitoring, fault management and service assurance onto the AIOps platform.
- Determine the best method to ingest data from the different monitoring tools. For example, build APIs, use pre-built connectors, use MuleSoft to automatically collect data from different systems, etc.
- Choose the right ML model based on the types of raw data, e.g., use an anomaly detection model to identify issues from a dataset or use a time-series model to understand patterns based on historic data.
- Use closed-loop automation to resolve low-risk issues; for example, automate disk clean-up issues or Java Virtual Machine (JVM) bounce for JVM-related issues.
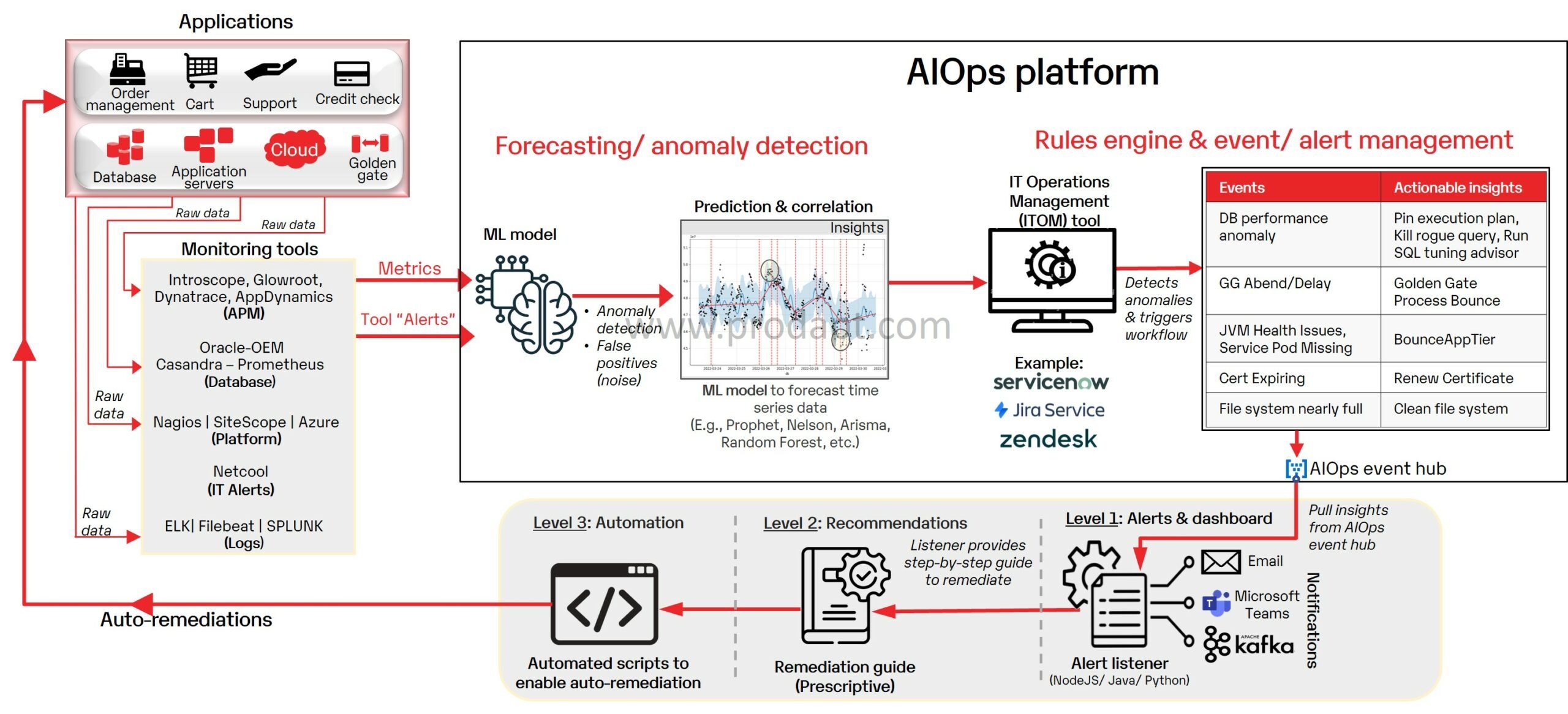
Fig: AIOps platform
Assess Your Organization’s Adoption of AIOps to Gain Value
Organizations contemplating AIOps as a strategy should first evaluate their current maturity and then chart out a path to make the best use of AIOps, which is automated resolution. There are three levels of maturity in AIOps adoption.
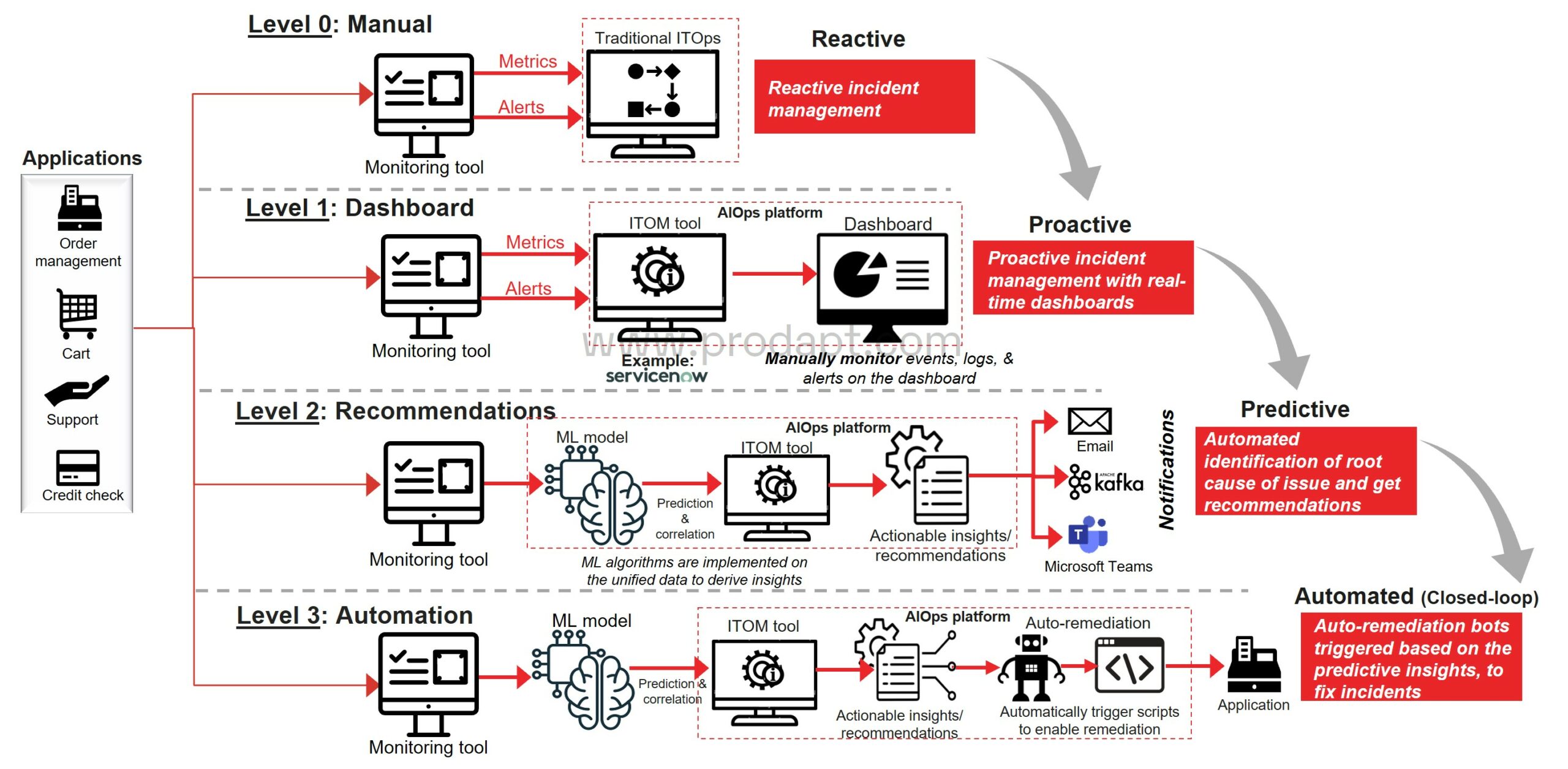
Recommendations
Level 1: Dashboard
- Remove operational siloes by integrating the application data sources into unified architecture and ITOM tool.
- Collect logs from applications and set up alerts that are commissioned to command centers to escalate as per the defined SOPs.
Level 2: Alarm & Recommend
- Implement supervised or unsupervised ML algorithms on the unified data to derive insights.
- De-duplicate and correlate alerts and events through noise reduction to alleviate alert fatigue
Level 3: Automation
- Correlate incidents and events with business impacts by leveraging ML algorithms.
- Trigger autonomous remediation bots spontaneously based on the predictive insights to fix incidents that are likely to happen in operations.
Identify Applications for the AIOps Platform
Conduct an AIOps workshop with key stakeholders to narrow down the list of apps and prioritize them for evaluation. Apply specific criteria to prioritize applications that meet the required onboarding standards.
Recommendations
- Prioritize onboarding critical apps and outage-causing apps on the AIOps platform.
- Tag the data e.g., metrics, logs, inventory, topology, to ease the browsing, searching and visualization of data across the distributed analytics repository.
- Setup an AIOps service and support team, as there is a constant need to maintain and update the platform features
- Collect all relevant logs, metrics and traces along with data collected from ITOM platforms. A poorly constructed AIOps platform will show incorrect insights and inaccurately reflect the activities in the IT environment.
Onboard Applications and Leverage AI to Predict and Resolve Issues
To initiate application onboarding, monitoring tools must be set up to collect data for ML models. Predictions from the models can be integrated into visual dashboards for analysis.

Fig: Application onboarding
Recommendations
- Route both the on-premises and cloud-centric data to the AIOps platform. This will facilitate the prediction of issues in both the environments.
- Use ML models such as Prophet, Nelson, Arisma, Random Forest, etc., to forecast the time series data, correlate the events and predict thresholds.
- Choose secure connectors to transfer data in/out of the AIOps platform. For instance, any log flowing into the platform must be sent over transport layer security (e.g., syslog) or HTTPS (API endpoints).
By implementing AIOps, service providers can successfully reduce the MTTI and MTTR, attaining a 63% reduction in outage costs for applications within 24 months, a 90% reduction in false-positive alerts and a 400+ hours reduction in downtime per annum.
Ramesh Ram (Assistant Vice President), Sreedhar S K (Associate Director), Sakthivel D (Director), and Rohit Karthikeyan (Manager) also contributed to this article.
