There’s a ton of hype and excitement surrounding containers, a la Docker, today, much in the same way virtualization took the data center by storm. In both cases, the excitement for operations focuses on the ease with which infrastructure might be deployed and managed via such technology.
Whether container or hypervisor, however, there remains a distinct difference between server and network virtualization that must be considered before getting too excited about the possibilities.
There are two distinct use cases for which virtualization and containerization of anything are considered beneficial: scale and deployment.
Scale
In terms of scale, both virtualization and containerization are excellent technologies. Both can fully encapsulate a service – whether application or network – and enable rapid deployment of multiple instances of the same service with very little (if any) post-provisioning requirements. This is the premise upon which cloud computing and NFV is based: clones of services and applications rapidly deployed to enable elastic scalability that matches demand.
For scalability purposes, virtualization or containerization of services is a match made (mostly) in data center heaven.
Deployment
Enabling rapid deployment of new services using virtualization or containers, however, is not necessarily going to net the same benefits. It is important note that the standardization and APIs associated with virtualization and containers that enable scalability so seamlessly is focused solely on the management of the container or virtual machine. The ability to provision a virtual machine or container is not at issue; APIs enable the rapid provisioning of a container or virtual machine with extreme alacrity.
What those APIs do not do is enable the rapid configuration of those services once provisioned.
Configuration != Provisioning
This is a critical differentiation that must be made lest we assume we can leverage virtualization and containers to enable a self-service style data center, a la IT as a Service. While virtualization and containers make provisioning a service instance a relatively painless experience, configuring those services must still be accomplished. When deploying a new service, existing configurations will not be wholly valid. There will always be some amount of customization that must occur, if only to make sure the service is interacting with the right application.
This means that once provisioning of the service is complete, there is still work to be done. One does not simply launch a load balancing service, for example, without instructing it how to distribute load (what algorithm to use) and to what set of servers (configure a pool).
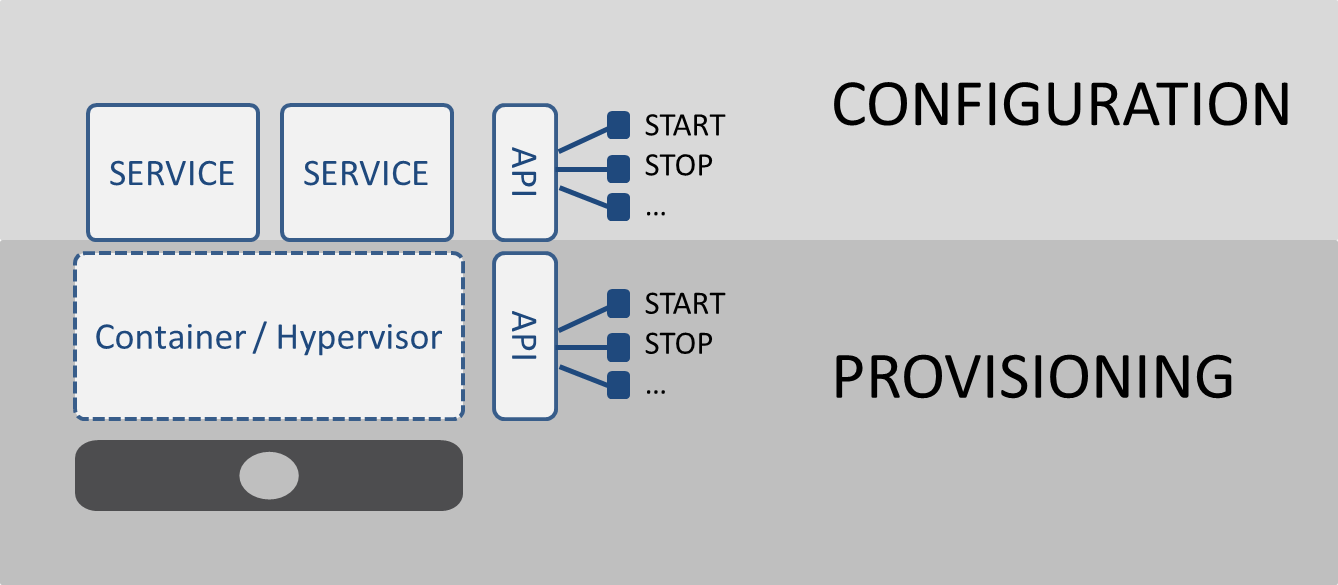
It is important to recognize the difference between these two steps in the deployment process and take into consideration the impact of configuration after provisioning on that process. Depending on the method of configuration, this step can have a serious impact on the speed and efficiency of the deployment process as a whole.
It is also important to note for monitoring purposes, as virtual machine health and status is not the same as the health and status of the service, whether that be an application or a network service. Both must be monitoring and managed in a virtualized infrastructure to meet MTTD (mean time to detection) and MTTR (mean time to resolution) objectives.
In most cases, the impact from configuration is the greater of the two, with its time requirements most significantly impacting the application deployment lifecycle. It is optimization of configuration processes, not provisioning, that will ultimately provide the biggest benefits for DevOps in terms of reducing errors and improving time to market.
