Recently workflows have emerged as a fundamental part of the operational wiring at companies as diverse as AWS, Facebook, HP, LinkedIn, Spotify, and Pinterest, which just open sourced Pinball. We’ve witnessed a spike of interest in workflow-based automation, and a few interesting implementations coming to the open-source world in just the last year or two: Mistral and TaskFlow from OpenStack ecosystem, Score from HP, Azkaban from LinkedIn, Luigi from Spotify, and dray.it by CenturyLink for the Docker ecosystem, to name a few.
Workflows are used to orchestrate operations in infrastructure and applications, automate complex CI/CD processes, coordinate map/reduce jobs, and handle jobs to containers.
It is not surprising that when it comes to higher level automation and orchestration, workflows are widely used. To quote the Pinterest blog: “In realistic settings it’s not uncommon to encounter a workflow composed of hundreds of nodes. Building, running and maintaining workflows of that complexity requires specialized tools. A Bash script won’t do.” Workflows are superior to scripts in concept and in practicality.
Conceptually, workflow separates the “recipe” from underlying details, giving an extra level of flexibility and mobility. Modify the process to your liking by modifying the workflow “blueprint,” without hacking hardwired code – like adding ticket updates on key steps for business process conformance. Or take an autoscaling workflow built for Rackspace cloud, and use it to scale an AWS cluster.
Practically, workflows are better in operations.
1) Workflow is an execution plan expressed as a directed graph of tasks – simple to define, to reason, and to visualize.
2) Workflow engine serves as a ‘messaging fabric,’ carrying structured data between different application domains.
3) The state of workflow executions is clear and easy to track: see which steps are running, which are complete, and what has failed.
4) It is possible to provide reliability and crash recovery[1], and good workflow engines do it.
5) There are other convenient frills. How good is logging in your scripts? i18n, anyone?
What makes a good workflow engine? The answer is “it depends.” It depends on the details of the job the workflow is designed to do, and how broad or narrow is the scope of the functionality. Below, I’ll highlight some architecture choices, features, functionality, and properties that I see as most relevant for using workflows in automation and orchestration.
1. Functionality
The core workflow functionality is to execute the tasks in the right order and pass down the data. In workflow lingo, they are called flow control patterns, and data patterns.
1.1 Flow control
The workflows are known to have over 40 control patterns. But 15 years of using workflow in system automation shows that few patterns are used in practice. The no-frills essentials are ‘sequential execution with conditions, passing data down the line.’ Parallel execution is often desired. But once you split to run tasks in parallel, you need to join them, and there are 16 distinct ways to do it. Handling joins is a high step of complexity in implementation, and in usability. Different workflow engines balance power and complexity differently.
Spiff workflow implements all (!) control patterns. ActionChain opted for simplicity of sequential execution, as the name suggests. So does Dray.it – the workflow there is a sequence of “jobs” – in this case, docker image executions. Pinball splits for parallel execution but only supports “synchronization” join – and continues on completion of all input branches. Pinball’s pluggable token-based design is a powerful abstraction to add joins, conditions, and more. Mistral tries to balance power with simplicity of use: it supports conditional transitions, parallel executions, various joins, and deals with multi-instances, handling collections of inputs at engine.
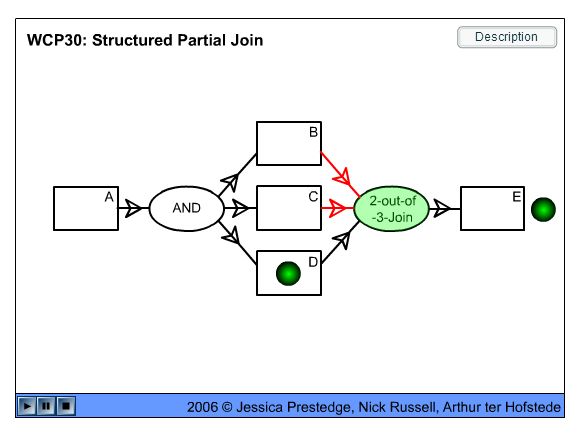
(please click link to see this illustration in a Flash animation):
http://www.workflowpatterns.com/patterns/control/new/wcp30_animation.php
1.2 Data passing
Data passing is another workflow functionality essential in system automation. It is an ability to use workflow input and upstream task outputs as inputs or conditions in downstream tasks. Publishing a named variable to execution context is a convenience feature offered by many engines.
Structural data commonly passed as JSON. Ansible Playbook, StackStorm ActionChain, and most others use Jinja templating for data manipulation. Jinja is widely adopted and well documented; a power user can do nice hacks with it. The challenge we faced is preserving types outside of Jinja templates. After all its templating engine, not a query language. Mistral solved this problem by using YAQL. YAQL is a modern extension of JsonPath – simple to use, very powerful, and easily extensible, but currently it suffers from lack of documentation (that is about to change, according to YAQL authors). Score workflow offers python syntax in a task definition: while convenient, it brings security concerns. Dray.it makes jobs communicate by passing environment variables and wiring stdouts to stdins (file output channels possible), but doesn’t offer any data transformation on the platform side. Pinball support for data passing at this time is rudimentary: it uses a convention to publish a string value, and leaves it up to jobs to agree on data formats.
2. Extensibility
What it takes to add a new type of action to the workflow? How to write it? How to deploy it? How to upgrade it? Most workflow tools have some answer, few give a rounded one for both development and operations. Pinball introduces pluggable job templates, and provides Bash, Python, Hadoop and Hive jobs out of box. However it leaves it up to the jobs to produce expected output format (smart job, simple platform). Spiff workflow has pluggable tasks, but it is not dynamic enough, therefore Spiff is most often used with Celery, leveraging its extensibility and remote execution functionality. StackStorm makes its full action library available as workflow building blocks, and brings action execution outputs into a common “message fabric.” Better yet, a workflow becomes an action itself. An ability to operate and run individual actions and workflows alike makes it easy to develop, debug, and operate.
3. Reliability
Workflows are long running. Long means: 1) long enough to expect a failure of any component, and the execution must sustain it, and, 2) long enough that I don’t want to start it all over if workflow execution fails for any reason, but rather fix a problem and continue. It all makes reliability a key requirement.
Pinball gets the highest score on reliability. Its fault-tolerant architecture (very similar to the one of Mistral) is based on atomic state update on each state transition, providing for scale-out masters and workers, fault tolerant executions, crash recovery and “no-downtime upgrade.” Ansible took a different approach: the playbook execution is not resilient, but the tasks are assumed idempotent, and when they are, it’s safe to re-run the whole playbook. Dray opted for simplicity and doesn’t seem to come with fault-tolerance yet.
Luigi workflow brings an interesting architecture where distributed workers pick up workflows and tasks alike, essentially treating workflow handling as just yet another job. It makes a great horizontal scale-out, but currently short on fault tolerance: the whole workflow execution is run with a worker where it got started.
4. Workflow definition
Human readable, machine scriptable language for declaring workflow is not just convenience. It’s a necessity for dynamic creation, uploading and updating workflows on a live system, and for treating “infrastructure-as-code.” A solid DSL is a good foundation for building UI on top (and not the other way around!). XML-based workflow languages are left the past; YAML is a new de-facto standard.
StackStorm’s ActionChain and Ansible Playbooks offer fun-to-write YAML workflow definitions. It reflects the simplicity of underlying engines at the expense of advanced functionality.
Spiff workflow offers XML, JSON, and pure python programmable definitions. Dray uses JSON. Pinball comes with no DSL out of box. It provides a python interface for building workflow programmatically; adding JSON or YAML workflow definition is a matter of writing a parser. According to Pinball team, it’s a “conscious choice to not make the configuration syntax part of the system core in order to give developers a lot of flexibility to define workflow configurations in a way that makes the most sense.”
But honestly two DSL for the same workflow doesn’t make much sense. Check out Score: it has taken this pluggable approach to the end, separating “languages” from workflow by pluggable compiler, with an idea to support multiple languages to the same workflow. However, the capabilities are defined in the workflow, so it’s impossible to introduce a meaningful new construct – like swap Jinga for YAQL, add “discriminator” pattern, or introduce timeout keyword – without hacking the workflow handler. Beyond superficial semantic sugar, syntax and capabilities can’t be truly separated.
Mistral and TaskFlow took a different tack, supporting pluggable workflow handlers. Mistral comes with two handlers, representing two types of workflow, with distinct capabilities. A direct workflow explicitly defines the flow of tasks with on-success/on-failure. A ‘reverse’ workflow defines task dependencies on upstream tasks with “requires” keyword, and runs all dependent tasks to satisfy the target task, like make or ant. The base workflow DSL is extended with handler-specific keywords.
5. Nice GUI
A good graphical representation makes it much easier to comprehend a structure of a workflow and track workflow executions. Building workflows graphically not only excites users, it helps user learn the system and greatly accelerates workflow authoring (you can taste it here). One problem: as Pinball authors rightly said, “Realistic workflows are 100s of steps.” Guess what, existing UI representations don’t scale well for 100 step workflows. Not just the new ones: anything we saw in the last 20 years [2] – they all suck. I believe this UX problem is yet to be solved.
Pinball doesn’t let great be the enemy of the good: it offers a visual representation of the workflow, and even an ability to build workflows from the UI. Luigi is another one that makes a simple d3 based map “good enough” to show the tasks.
Score and Mistral took an alternative approach to make authoring workflows faster and bug-free, supplying Sublime plugin for and syntax check. StackStorm’s WebUI (below) brings an efficient representation of workflow executions for ActionChain and Mistral workflows. In upcoming releases, we will stand up to a challenge of representing workflow execution plan and visual workflow building.

Conclusion
StackStorm loves workflows: they are essential for higher-level automation. Customizable CI/CD, autoscaling, automatic failure remediation, automated security response – it is all workflows. Different workflows are optimized differently for different jobs, and there are tastes in play, too. So we made a workflow engine to be a pluggable component. Currently we supply ActionChain for speed and simplicity, and Mistral for complex workflow logic and scalable reliable execution.
We liked Pinball: it is built on simple and powerful abstractions of basic task model and job tokens, it has reliable and scalable architecture, and it provides a good programing interface for workflow and job definitions. We would definitely consider supporting it in StackStorm as it gains maturity and traction.
…
This table summarizes the areas of functionality discussed in the article, however casts no judgement on pragmatic choices each workflow made to optimize for the target usage.
| Advanced flow control | Data passing and transforms | Fault tolerant execution | YAML/JSON DSL | Pluggable actions | Visual Representation | |
| Pinball | + | + | + | |||
| Spiff | + | + | ||||
| Luigi | + | + | ||||
| Ansible | + | + | + | |||
| Dray | + | |||||
| Score | + | + | + | + | + | |
| ActionChain | + | + | + | |||
| Mistral | + | + | + | + | + |
Footnotes and References
[1] Workflow execution model and state is significantly simpler and smaller than the one of a Turing-compliant language, making it practical to persist and restore at every step, at scale.
[2] M$ System Center Orchestrator (formerly Opalis), HP Operations Orchestration (formerly iConclude), BMC Atrium Orchestrator (formerly Realops), CA ITPAM (now dead), VMware vCenter Orchestrator (formerly Dunes), NetIQ Aegis, MaestroDev, Cisco CPO (formerly Tidal), Cisco UCS Director (formerly Cloupia Unified Infrastructure Controller), Citrix Workflow Studio – check them out, see the UIs, and think how they handle 100-step workflow before you cast your judgement.
The following are the detailed references to the products and tools mentioned in the article for the reader’s convenience.
- Pinball, by Pinterest
- architecture https://github.com/pinterest/pinball/blob/master/ARCHITECTURE.rst
- intro blog http://engineering.pinterest.com/post/74429563460/pinball-building-workflow-management
- opensoucing Pinball blog http://engineering.pinterest.com/post/113376157699/open-sourcing-pinball
- source https://github.com/pinterest/pinball
- Spiff Workflow https://github.com/knipknap/SpiffWorkflow/wiki
- Score, by HP:
- main page http://www.openscore.io/#/
- docs http://www.openscore.io/#/docs
- Dray, by CenturyLink http://dray.it/
- Luigi, by Spotify – https://github.com/spotify/luigi
- Ansible https://github.com/ansible/ansible
- TaskFlow https://wiki.openstack.org/wiki/TaskFlow
- Ozzie from Apache http://oozie.apache.org/
- Azkaban by LinkedIn http://data.linkedin.com/opensource/azkaban
- ActionChain, by StackStorm: http://docs.stackstorm.com/actionchain.html
- Mistral, from OpenStack community https://wiki.openstack.org/wiki/Mistral (integrated into StackStorm)
About the Author/ Dmitri Zimine
 Dmitri Zimine, CTO, StackStorm is the “Chief Stormer” and co-founder of StackStorm. Amongst Dmitri’s credits are helping to lead the first wave of operations automation while serving as lead architect and head of engineering at Opalis. Opalis invented “run book automation” before being acquired by Microsoft in 2009 and is now System Center Orchestrator. Most recently Dmitri was at VMware, leading the vSphere Client team through four major releases and working on a variety of related projects. In this role Dmitri also led a successful transition of vSphere Client to a new technology stack. Dmitri holds a PhD in Mathematics and Physics from Tomsk State University in Russia.
Dmitri Zimine, CTO, StackStorm is the “Chief Stormer” and co-founder of StackStorm. Amongst Dmitri’s credits are helping to lead the first wave of operations automation while serving as lead architect and head of engineering at Opalis. Opalis invented “run book automation” before being acquired by Microsoft in 2009 and is now System Center Orchestrator. Most recently Dmitri was at VMware, leading the vSphere Client team through four major releases and working on a variety of related projects. In this role Dmitri also led a successful transition of vSphere Client to a new technology stack. Dmitri holds a PhD in Mathematics and Physics from Tomsk State University in Russia.
