Enterprise IT organizations increasingly explore innovative approaches such as vibe-coding, a practice that leverages AI-driven tools and large language models (LLMs) to prototype and develop software with minimal traditional coding rapidly. Vibe-coding prioritizes functionality, user experience and iteration speed over strict adherence to conventional software engineering methodologies.
The timing is no coincidence. The surge in accessible, high-performance LLMs, alongside AI code assistants like GitHub Copilot and integrated APIs from OpenAI and Google, has lowered the barrier to entry for building intelligent applications. What once required full-stack developers can now be initiated by analysts, architects and subject matter experts.
While vibe-coding initially promises accelerated innovation and simplified development, scaling it across broader, less technical audiences introduces significant complexity, governance risks and operational challenges. Using the evolution of the CTO Signal Scanner application as a detailed case study, this report helps CTOs understand the intricate balance required to scale vibe-coding effectively and sustainably.
Initial Exploration: Prototyping With Intent
We didn’t start by chasing a product. We began by exploring a possibility. The goal was simple: Could an AI-enhanced CLI tool help an enterprise IT analyst track vendor signals more effectively?
That first version was exactly what it needed to be: A lightweight proof of concept written in Python with OpenAI integration. A fast way to test value. The command-line interface was the fastest path to signal, and it confirmed what we suspected: Generative AI could add immediate value in surfacing insights from routine vendor updates.
This wasn’t naive code-gen play. It was deliberate prototyping, vibe-coding in its best form: Small, sharp and curiosity-led.
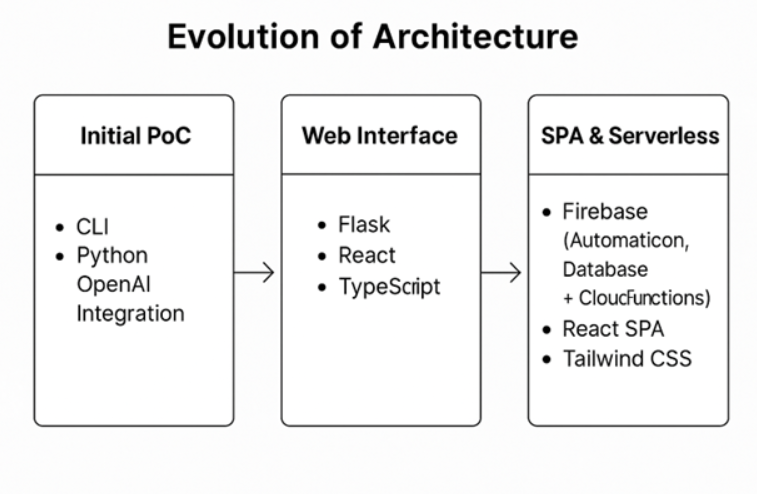
Scaling Delivery: From CLI to Web Interface
Once the initial PoC proved valuable, we needed to expose it to a broader audience. The obvious next step was a web interface. Since we began in Python, extending it with Flask seemed logical, it let us stay close to the original codebase.
But this is where architectural momentum can become architectural friction.
In hindsight, this was the point where a more production-minded architectural lens could have shifted the trajectory: Python + Flask may feel familiar, but modern frontend gravity has clearly consolidated around React and TypeScript. The developer ecosystem, the agentic tooling and even model pre-training patterns align more naturally with the React + Firebase + TypeScript world.
That choice matters because the deeper your AI-assisted dev stack aligns with prevailing patterns, the more you can leverage the weight of pre-trained behavior.
Two Paths of Vibe-Coding: The Architect vs. the Enthusiast
This highlighted something important: Not all vibe-coding is created equal.
There’s the path of the expert system architect or senior SWE, using AI tools as force multipliers, prompting multiple agents, testing architectural forks and evaluating tradeoffs at speed. That’s a fundamentally different mode than a former developer or business analyst casually asking for features via a prompt and shipping the result unchecked.
Both of these approaches wear the same label, vibe-coding, but the workflows, risks and output quality are worlds apart.
It’s time we acknowledge that duality. One path is building the future. The other? Potentially repeating the sins of Lotus Notes and shadow IT with turbocharged tooling.
Enterprise Implication: What’s Actually Changing?
Vibe-coding, in the enterprise context, isn’t about replacing developers. It’s about changing the shape of the developer experience and putting more strategic pressure on architectural leadership.
The real bottleneck is no longer how quickly we can write code. It’s deciding what to build, what shape it should take and what’s operationally sustainable.
In this way, code-gen has revealed a hidden truth: There is now a premium on deep technical experience. Because if machines can write code, the critical skill isn’t the keystroke, it’s the decision tree behind it.
Strategic Pivot: SPA and Serverless Architecture
Acknowledging that microservices were overly complex, the team pivoted towards a React Single Page Application (SPA) with Google’s Firebase backend services, significantly reducing complexity and operational overhead:
- Frontend (React SPA): Leveraged React and Tailwind CSS for responsive, scalable and maintainable frontend development.
- Backend (Firebase): Utilized Firebase Authentication, Firestore and Cloud Functions to simplify backend processes, reduce complexity and improve integration.
- AI Integration (Gemini API): Centralized Cloud Functions optimized API usage, streamlined caching and maintained scalability and reliability.
Architecture Economics: Inference Latency, Unit Costs and Hosting Tradeoffs
As the application matured, the team encountered two major architectural forks — each tied directly to the economics and operational realities of AI at scale.
Inference Model Infrastructure: Hosted vs. Local
Initially, the Signal Scanner leveraged OpenAI’s APIs to rate and summarize articles. However, early tests showed that there was no material quality difference between OpenAI’s responses and outputs from open-source models like LLaMA or Mistral. The key differentiator turned out to be latency.
- OpenAI’s hosted models consistently returned responses in under three seconds.
- Local models, including SoC GPU(M2-Pro)-accelerated, returned results in five to 20 seconds, depending on cold start behavior and load conditions.
Strategic Insight: This is the token economy NVIDIA’s Jensen Huang refers to — AI workloads must be judged not just by compute cost, but by unit economics: latency, reliability and engineering overhead per insight.
For our use case, real-time responsiveness, OpenAI’s hosted infrastructure provided the latency profile we could not match internally without investing in GPU-backed environments in a data center or the public cloud.

Backend Infrastructure: Firebase vs. Kubernetes
The second decision was backend infrastructure. Should the application be deployed on Kubernetes (e.g., GKE, OpenShift) or Firebase?
Kubernetes offered:
- Predictable cost structures via reserved resources.
- Alignment with existing observability and security models.
- Long-term operational control.
Firebase offered:
- High developer velocity for small, fast-moving teams.
- Built-in authentication and real-time database.
- Less predictable costs due to usage-based billing.
Firebase reduced our initial backend development time by over 60% compared to building and securing a Kubernetes deployment, though cost forecasting became significantly more variable beyond the first 10k users.
Enterprise Consideration: Firebase prioritized delivery speed over cost control. It was the right choice for our current maturity level, but came with active monitoring and reversibility planning if costs grew beyond thresholds.
The Hidden Complexity: Backend Infrastructure Considerations
A significant challenge arose from backend infrastructure, often overlooked by vibe coders focused purely on frontend features:
- Non-experienced Vibe-coders rarely consider differences in backend storage (MySQL vs. NoSQL) or orchestrating backend services (API gateways, Kubernetes choices).
- Decisions around OpenShift, VMware Tanzu, or Kubernetes dramatically affect backend integration complexity, operational costs and frontend responsiveness.
Real-world Backend Challenge:
Accurately depicting the real-time processing status of AI article analysis (varying from seconds to minutes) proved difficult within the monolithic Flask setup. Transitioning to a React SPA architecture with Firebase backend seamlessly addressed these complexities, improving user feedback, reducing integration challenges and enhancing operational simplicity.
Product Management: Avoiding “Lotus Notes Syndrome” and Snowflake Complexity
Standing up and scaling vibe-coding centers of excellence for non-traditional application developers in enterprise environments demands rigorous product management discipline. Unchecked expansion of AI tools to general employees can repeat historical enterprise errors, generating fragmented systems, unmanaged technical debt and questionable ROI.
Historical Lessons:
- Lotus Notes Syndrome: Decentralized departmental workflow optimization initially accelerated productivity but eventually resulted in significant operational complexity and technical debt.
- Cloud Sprawl: Developers’ unrestricted cloud usage produced customized “snowflake” environments, hindering central support and operational management.
A Fortune 100 COO underscored that simply providing general employees with AI tools, without structured oversight, often leads to unintended consequences, operational fragmentation and long-term inefficiencies.
Structured Product Management Recommendations:
- Centralized AI Governance: Clearly defined committees or roles responsible for aligning AI tools with enterprise standards and objectives.
- Explicit Architectural Standards: Providing vibe coders with clear guidelines and reference architectures for consistency and interoperability.
- Disciplined Feature Scope Management: Evaluating each requested feature rigorously against strategic business objectives and potential complexity.
- Regular Technical Debt Reviews: Scheduled assessments to explicitly manage and mitigate AI-generated technical debt and maintainability concerns.
Nuanced Governance Challenges at Scale
Scaling vibe-coding practices across broader, non-technical audiences requires proactive governance adjustments:
- Architectural Consistency: Preventing non-technical vibe coders from creating inconsistent interfaces and fragmented backend integrations.
- Technical Debt Management: Explicit processes for reviewing, documenting and managing AI-generated code quality and maintainability.
- Security and Compliance: Comprehensive training and rigorous oversight to ensure adherence to enterprise-grade security and regulatory compliance.
- Ethical AI Use: Clearly communicated ethical guidelines for responsible AI deployment, avoiding inadvertent ethical breaches.
Cultural and Organizational Considerations
Successfully scaling vibe-coding also requires careful attention to organizational and cultural factors:
- Skill Development: Structured training emphasizing foundational software development and AI-specific skillsets (prompt engineering, AI integration best practices).
- Psychological Safety: Cultivating an environment supportive of iterative experimentation, learning from failures without punitive repercussions.
- Managing Cognitive Load: Ensuring developers maintain technical depth and avoid burnout amid rapid AI-assisted iteration cycles.
Key Lessons for CTOs Scaling Vibe-Coding
- Clearly understand operational and financial motivations behind architectural shifts.
- Transition cautiously from local, prototype-driven architectures to centralized, enterprise-grade infrastructures.
- Carefully evaluate architectural decisions based on practical ROI considerations, not just prevailing industry trends.
- Maintain rigorous product management discipline, explicitly managing scope and complexity to avoid operational fragmentation.
- Proactively address governance, security, compliance and technical debt management, particularly when scaling vibe-coding to general or non-technical audiences.
Conclusion
Effectively scaling vibe-coding within enterprise IT requires nuanced decisions regarding architecture, governance, product management and culture. The evolution of the CTO Signal Scanner vividly illustrates the complexities inherent in scaling from simple prototypes to enterprise-ready, centralized applications. By embedding rigorous product management, structured governance, clear architectural guidelines and cultural support, CTOs can harness the rapid innovation potential of vibe-coding without repeating historical enterprise pitfalls. This strategic, disciplined approach ensures long-term operational efficiency, technical stability and sustainable ROI for enterprise IT organizations.
