The concept of shift-left has been a popular trend in continuous testing practices for a while. We are now beginning to see shift-right practices as an emergent trend in testing.
Shift-right entails doing more testing in the immediate pre-release and post-release phases (i.e. testing in production) of the application lifecycle. These include practices such as: release validation, destructive/chaos testing, A/B and canary testing, CX-based testing (e.g. correlating user behavior with test requirements), crowd testing, production monitoring, extraction of test insights from production data, etc.
Shift-right not only introduces such new testing techniques, but also requires testers to acquire new skills, make aggressive use of production data to drive testing strategies and collaborate with new stakeholders, such as site reliability engineers (SRE) and operations engineers.
In shift-right of testing, and in the increased collaboration with operations disciplines, we see the evolution of a new discipline in DevOps that we call TestOps.
In this blog, we will discuss the various shift-right testing trends and practices, what’s driving them, the new skills and collaboration required so that TestOps benefits can be realized.
Emerging Trends in Shift-Right Testing
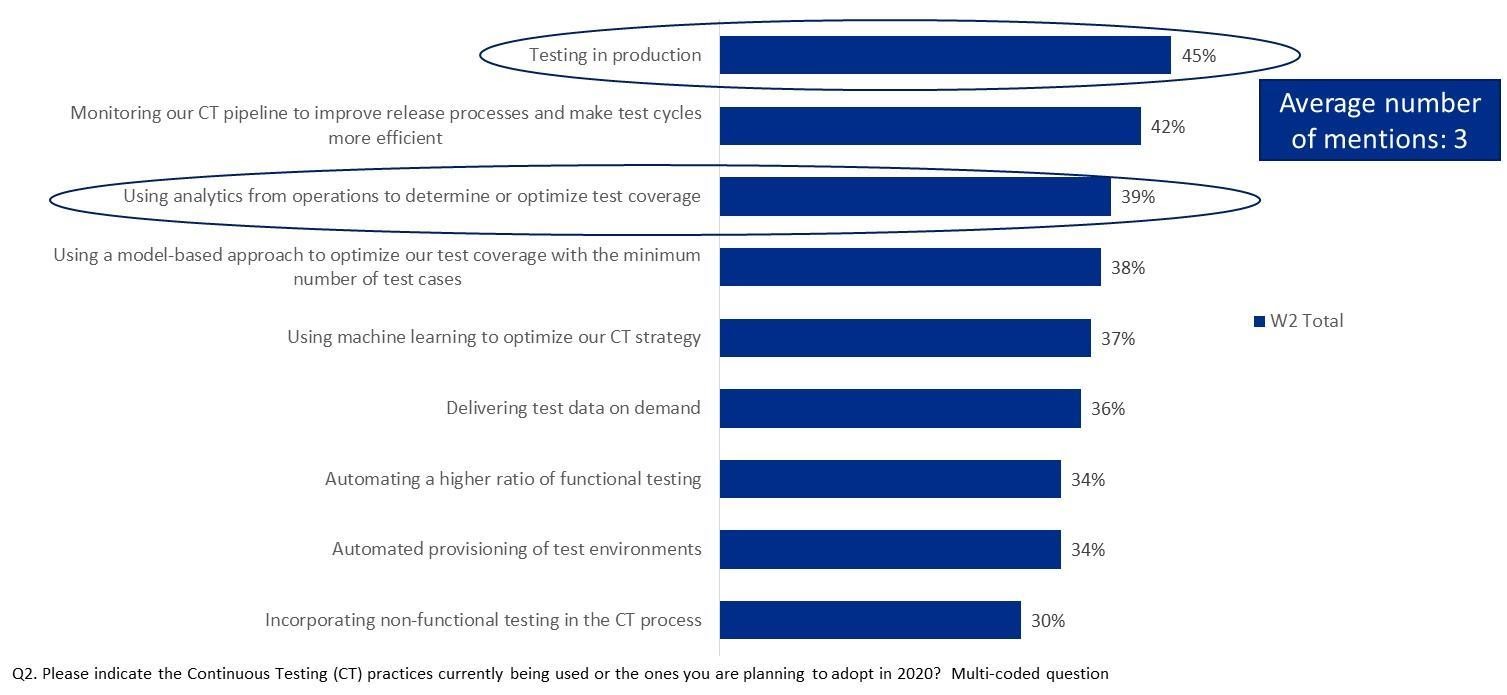
In a recent survey of continuous testing conducted jointly by Capgemini and Broadcom, testing in production was ranked as the number one practice (with 45% respondents) either currently implemented or planned (see Figure 1). In addition, 39% of the respondents mentioned the use of analytics from operations to determine or optimize test coverage.
When asked how customers measure the effectiveness of continuous testing processes, production data and user feedback and adoption of new functionality were ranked number one and number two respectively (see Figure 2).

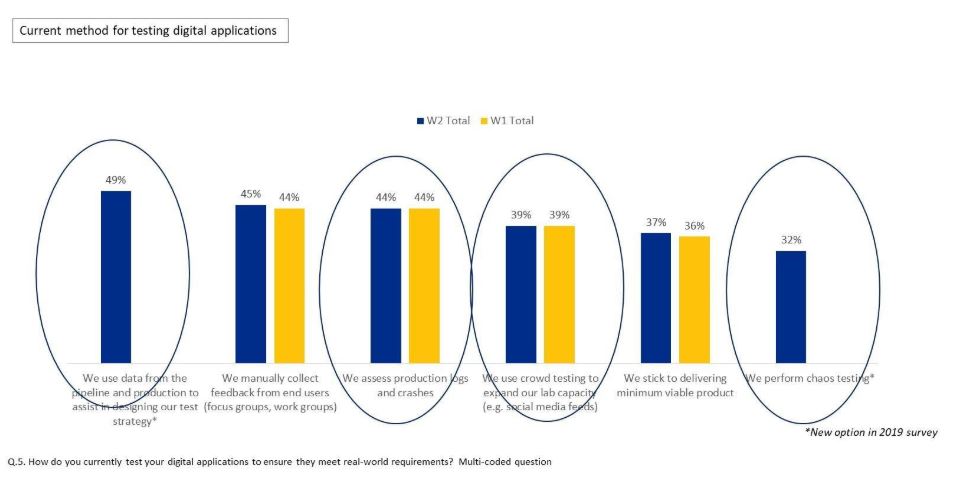
Finally, in response to how customers test their digital applications to ensure that they meet real world requirements, almost all of the responses were related to production data (see Figure 3). Use of production data for designing test strategy and chaos testing emerged as new methods compared to similar survey done a year ago.
The survey data clearly indicates that customers are actively practicing (or considering adoption of) shift-right testing techniques. This report has a chapter (with my contributions) dedicated to shift-right that discusses the techniques and recommendations for its adoption, as well as relevant customer case studies.
What’s Driving Shift-Right Testing Trends?
The goal of shift-right testing is to ensure correct behavior, performance and availability over the production of an application.
There are several drivers for adoption of shift-right testing trends.
Customer Experience (CX) Is a Key Quality Metric for Digital Applications
Unlike classic testing, this takes into account real-world users and their experiences. An application with perfect traditional quality scores (such as FURPS) may still suffer from poor CX if it fails to delight the customer. CX is measured using various metrics such as Customer Effort Score (CES), Net Promoter Score (NPS), Customer Satisfaction Score (CSAT), etc. While it is possible to shift-left some of these measurements to some degree, most CX measurements are deduced from systems in production (or close to production). Examples of CX-based testing include the following:
- Requirements validation based on real user journeys, behavior and feedback.
- Deriving functional and performance test scenarios based on the above.
- A/B testing and canary testing, to experiment how well customers like (or dislike) changes.
- Crowd testing, to better understand real-world user experience.
In a World of Agile Delivery, It may Not Be Possible to Test Everything Before Release to Production
Time to market (or lead time for changes) is a top business imperative for digital applications, which is why QA/testing is considered a major bottleneck in continuous delivery. While it is possible to optimize testing effort and cycle time using shift-left practices (such as model-based testing, change-impact testing, test process and execution automation etc.), those approaches may still take too long (or too much effort) during the shrinking release cycle time. In some cases, the exact usage patterns may not even be fully understood before release. The idea is to learn usage patterns from production and use it for better testing strategy within shift-left.
Complex and increasingly distributed systems using microservices (using thousands of components) and cloud-native techniques that allow releases at a very granular level make it more and more difficult to test fully in pre-production environments. This is complemented by the fact that since such releases are so granular, they may be backed out easily (rollback) in case they cause problems.
Hence, enterprises test to assure “good enough” quality (to ensure timely release) and rely on fast remediation (or rollback) to address defects or problems that arise.
Also, CX measurements (as described above) often provide real-user feedback in shades of gray, unlike the black-n-white pass/fail measurement of classic testing. Which means it is not possible to perfect pre-production test suites to ensure thorough CX coverage.
A Hundred Percent Reliability (or Quality) Is Often an Unrealistic Goal
Related to the above, one of the key principles we learn from the DevOps discipline of SRE is that 100% reliability is not only unrealistic, but often too expensive to accomplish. SRE establishes the concept of service level objectives (SLOs) and error budgets to quantify acceptable risk tolerance in production systems. The same principle applies to testing and overall quality. See my related blog for more on this subject
Some Validations Are Difficult to Run in Test Environments
These include large-scale performance tests when the test environments are not appropriately sized (or configured) relative to production environments.
Another example is destructive or chaos testing. While it is possible to run isolated chaos testing in test environments by using techniques such as service virtualization (to simulate failure in dependent components), it is difficult to execute for large-scale destructive tests. For example, Netflix does a significant amount of their testing in production.
Similarly, enterprise monitoring to gather insight about real-world usage patterns and failures is only possible in production. Though we advocate turning on monitoring in test environments (as part of shift-left), such monitoring only helps to do localized monitoring (e.g. of the specific app or system being tested), and that too under test conditions. However, performance test scenarios that have been developed by testers can be re-used in production (shift-right) as synthetic monitors to measure application performance and regression.
Lastly, as an extension of monitoring, testing of some AI-based applications may be difficult without access to production data. Some machine learning algorithms, for example, need to be constantly refined based on real world data. While these algorithms are developed using a limited set of training and testing data, they need to be monitored and tuned, based on its performance in production.
Developers and Testers Need Easier Closed-Loop Feedback from Production
Easier closed-loop feedback from operations allows developers and testers to better understand the behavior of the app, predict the success/failure of releases and respond to production incidents (e.g. reduce MTTR).
Interpretation and use of voluminous production data is often difficult and tedious for development and test teams. Use of shift-right techniques allows developers and testers to access production data more easily in a form that is easily consumable and actionable–by leveraging the right insights from AIOps disciplines. This data collaboration is a key tenet of the DevOps paradigm. For example, synthetic monitors (which are typically created by developers and testers in the dev/test stages) provide means for developers to get monitoring feedback in a form that they are familiar with.
In addition, automated root-cause analysis of defects/incidents in production can provide developers and testers insight on failure patterns and trends, their sources (when production data is correlated with development data) and what’s causing them, and how they may be better prevented.
Similarly, data usage scenarios (e.g. from database logs and RR pairs from service transaction logs) can be used for generation of relevant test data.
In essence, shift-right testing practices are necessary to create a continuous feedback loop from real user experience with a production application back to the development and testing process.
The Evolution of TestOps Discipline
It is clear from the customer survey data and drivers discussed above that there is an evolution toward shift-right practices.
Just like we did with shift-left testing, in order to make these practices sustainable and to realize the benefits, we need to also evolve tester use cases, skills, tools and collaboration patterns with people and disciplines to the right of the application lifecycle, i.e. operations. In other words, a new discipline needs to be established—we call this new discipline TestOps—a sub-discipline within the broader DevOps context.
Though the term TestOps (like all the X-Ops sub-disciplines within DevOps) implies the collaboration between testing and operations, it isn’t simply about shift-right. Why? Because with DevOps, operational disciplines themselves have shifted left (such as shift-left of monitoring, configuration management, SRE, etc.). Hence TestOps—true to the principle of continuous testing—refers to better collaboration with operations disciplines across the DevOps lifecycle.
Let’s consider some of the key practices in TestOps shift-left (see Figure 4).
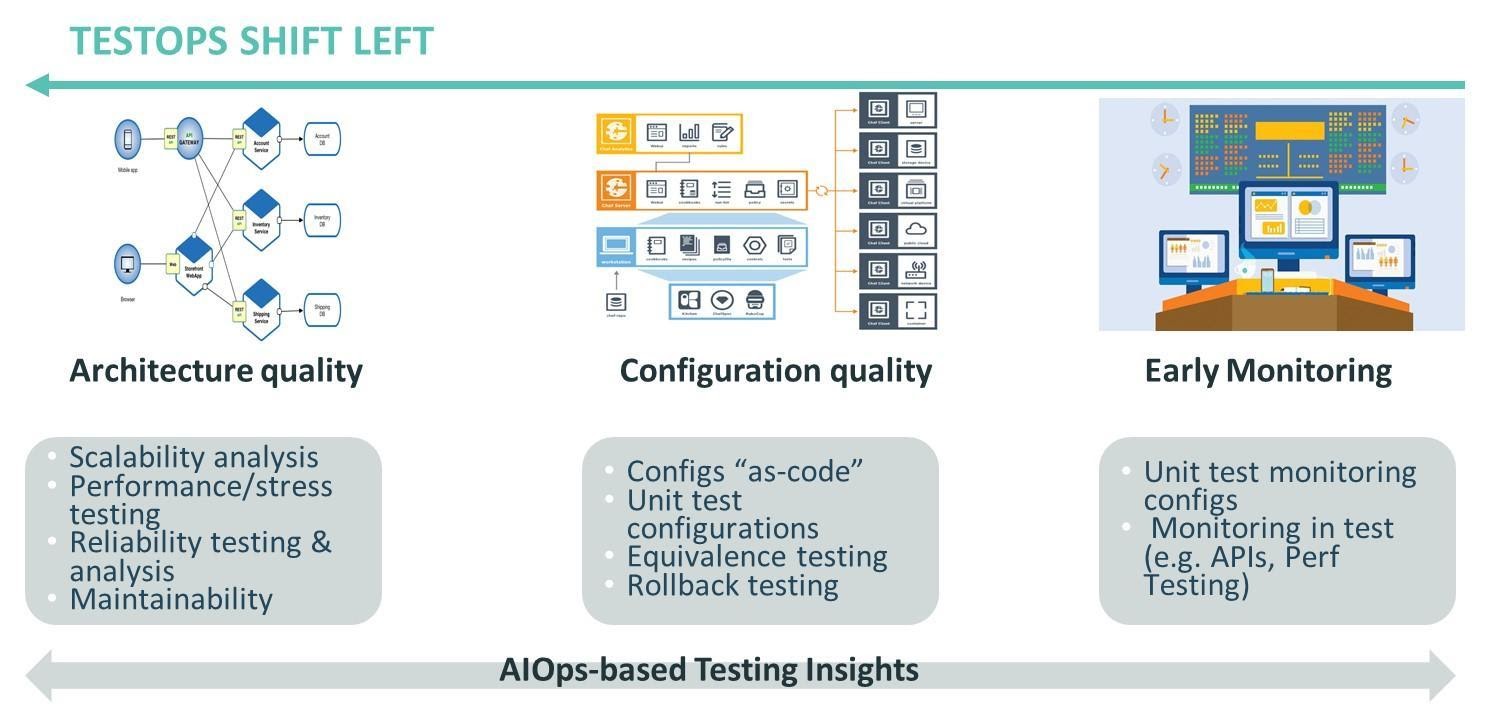
- Early reliability testing: this includes static scalability analysis of the system architecture, as well as performance and stress testing.
- Configuration quality and testing: this includes testing of “as-code” (anything “as-code” can and should be tested as such, just like application code) environment and deployment configurations, as well as deployment testing (to test the correctness of deployments) and rollback testing (to ensure that rollbacks can be done quickly and successfully).
- Early monitoring: includes monitoring of systems early in the lifecycle (e.g. in development and test environments) as well as development and testing of synthetic monitors before they are deployed to production.
- Early AIOps insights: this includes early use of AIOps techniques (in the dev/test environments) to glean testing and quality insights, for example for defect and release risk prediction.
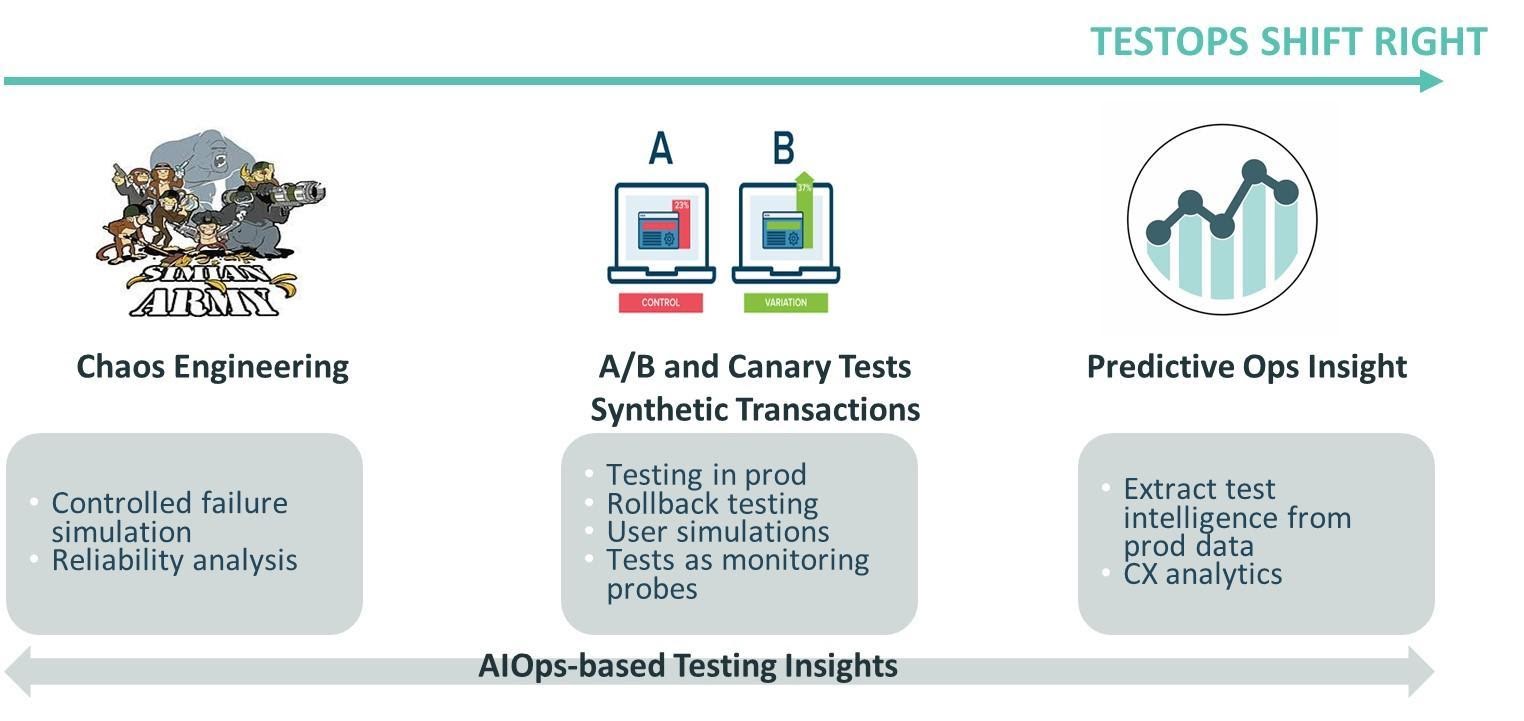
Below are some of the key TestOps shift-right practices (see Figure 5).
- Chaos engineering: this includes testing the reliability of the system through the injection of controlled failure scenarios.
- A/B testing: consists of a randomized experiment with two (or more) variants to study which are more effective with users.
- Canary releases: consists of techniques used to reduce the risk of introducing a new software version in production by gradually rolling out the change to a small subgroup of users, before rolling it out to the entire platform/infrastructure and making it available to everybody.
- Synthetic monitoring: includes monitoring techniques using an emulation or scripted recordings of transactions (that reflect typical user behavior).
- CX testing and analytics: includes extracting of CX data to understand customer experience as well as to derive insights from it (such as customer problems, new feature requirements, etc.).
- Other testing in production: includes performance tests and testing of AI-based applications.
- Testing insights from AIOps data: as described above, a rich variety of testing insights can be gleaned from operations data.
Key TestOps Skills and Tools
Let’s consider the new skills required for the key TestOps practices. This includes the following:
- Data analytics skills: Since most of the production data is both voluminous, diverse and often temporal, testers must now pick up data analytics so that they quickly glean insight from such data, as well as perform correlations with other datasets to identify actions. Advanced analytics skills (such as predictive analytics or machine learning) are also necessary to predict events (e.g. release quality). While these analytics skills are well understood within the operations community (with the increasing adoption of AIOps), these are relatively new for developers and testers.
- CX skills: As we discussed, CX is now considered a key metric for measuring quality in production. New types of CX testing include A/B and canary tests as well as crowd testing. Like other operational data, CX data is also typically voluminous and often unstructured. While CX teams specialize in such principles, testers need to acquire sufficient skills to glean insight from the CX process and data, and collaborate effectively with such teams.
- Monitoring and operations skills: Understanding of monitoring principles (e.g. creation, testing and deployment of monitors and use of data from monitors) is a key skill required for TestOps. Similarly, testers must also understand operations principles (incidents, failures, alarms, MTBF, MMTR, configuration definitions, etc.) so that such information can be leveraged for testing purposes as well as for collaboration with ops teams.
- Reliability skills: Reliability is also another key operational quality attribute that testers need to be familiar with. This includes chaos/resiliency testing, deployment and rollback testing, and configuration testing. The discipline of SRE has evolved within DevOps to address reliability, and many of its principles overlap with TestOps.
- New tools skills: In addition to using traditional testing tools, TestOps also requires the use of additional tools such as monitoring, data analytics (for production and CX data), CX testing (such as A/B and canary testing) and reliability testing. Technology innovations that support testers with these new capabilities include RunScope (a lightweight API monitoring tool that can be used for monitoring both in test and production environments), Blazemeter (for performance testing for CX and reliability), Optimizely for A/B testing. For data analytics, technologies such as automation.ai simplify the work of data aggregation and modeling so that testers can more easily extract actionable insights from data collected across the lifecycle.
Key TestOps Collaborations
In addition to new skills, testers must now learn to collaborate better with additional stakeholders as alluded to above. These include:
- Collaboration with data science and AI/ML engineers: This is necessary for testers to tweak or build out new algorithms and models required to perform the analytics needed for TestOps.
- Collaboration with CX engineers and teams: This is necessary for testers to monitor the appropriate CX metrics and data, and to study the impact of their testing/QA activities on CX.
- Collaboration with Operations engineers and teams: This is fundamental for TestOps to not only support all the shift-right testing activities, but also to gain access to production data that is required for TestOps analytics. This is analogous to how testers collaborate with developers as part of shift-left.
- Collaboration with SREs: As mentioned, there is a fair degree of overlap between SRE and TestOps principles, and hence collaboration with SREs is key for testers. See my blog on how testers and SREs can work better together to improve reliability.
Conclusion
Hopefully, this article has provided readers with some insight into the emerging discipline of TestOps. As we build increasingly distributed microservices and cloud-native systems, and as the discipline of SRE matures, we expect to see more of shift-right testing practices that enrich TestOps.
