Consider the following scenario.
An Independent Software Provider (ISV) developed a financial application for a global investment firm that serves global conglomerates, leading central banks, asset managers, brokerage firms and governmental bodies. The development strategy for the application encompassed a thought through DevOps plan with cutting-edge agile tools. This has ensured zero downtime deployment at maximum productivity. The app now handles financial transactions in real-time at an enormous scale, while safeguarding sensitive customer data and facilitating uninterrupted workflow. One unfortunate day, the application crashed and this investment firm suffered a severe backlash (monetarily and morally) from its customers.
Here is the backstory: Application’s workflow exchange had crossed its transactional threshold limit, and lack of responsive remedial action crippled the infrastructure. The intelligent automation brought forth by DevOps was confined mainly to the development and deployment environment. The IT operations, thus, remained susceptible to challenges.
Decoupling DevOps and RunOps — The Genesis of Site Reliability Engineering (SRE)
A decade or two ago, companies operated with a legacy IT mindset. IT operations consisted mostly of administrative jobs without automation. This was the time when the code writing, application testing and deploying was done manually. Around 2008 to 2010, automation started getting prominence. Now developers and ops teams worked concurrently toward continuous integration and continuous deployment — backed by the agile software movement. The production team was mainly in charge of the runtime environment. However, they lacked skillsets to manage IT operations, which resulted in application instability, as depicted in the scenario above.
Thus, DevOps and RunOps were decoupled, paving the way for SRE — a preventive technique to infuse stability in IT operations.
Software-First Approach: Brain Stem of SRE
“SRE is what happens when you ask a software engineer to design an operations team,” said Benjamin Treynor Sloss, VP of engineering at Google.
This means an SRE function is run by IT operational specialists who code. These engineers implement a software-first approach to automate IT operations and preempt failures. They apply cutting edge software practices to integrate dev and Oops on a single platform, and execute test codes across the continuous environment. Therefore, they carry advanced software skills, including DNS configuration, remediating server, network and infrastructure problems, and fixing application glitches.
The software approach codifies every aspect of IT operations to build resiliency within infrastructure and applications. Thus, changes are managed via version control tools and checked for issues leveraging test frameworks, while following the principle of observability.
The Principle of Error Budget
SRE engineers verify the code quality of changes in the application by asking the development team to produce evidence via automated test results. SRE managers can fix service level objectives (SLOs) to gauge the performance of changes in the application. They should set a threshold for permissible minimum application downtime, also known as error budget. If a downtime during any changes in the application is within the scale of the error budget, then SRE teams can approve it. If not, then the changes should be rolled back for improvements to fall within the error budget formula.
Calculating Error Budget
A simple formula to calculate error budget is: (system availability percentage) minus (SLO benchmark percentage). Please refer to the System Availability Calculator cheat sheet below.
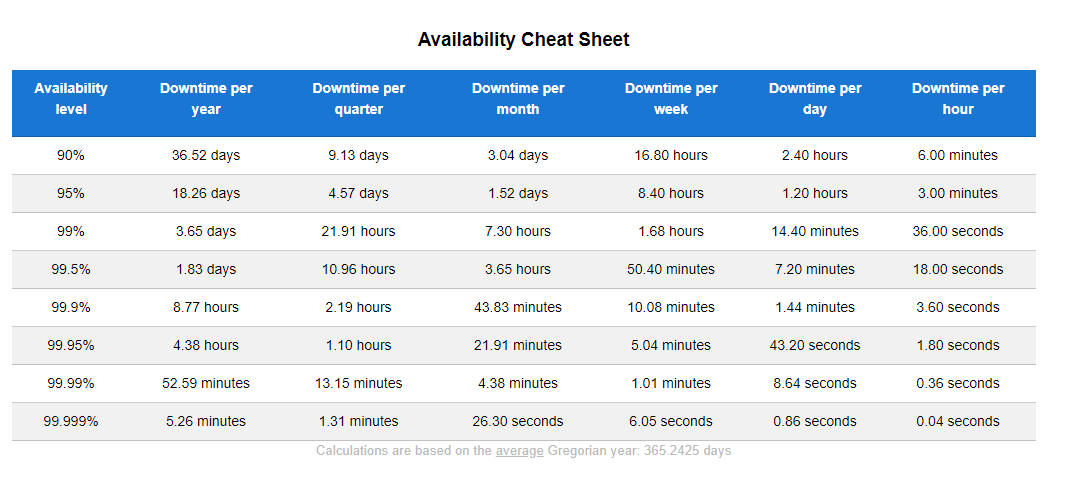 Suppose the system availability is 95% and your SLO threshold is 80%.
Suppose the system availability is 95% and your SLO threshold is 80%.
Error budget: 95% – 80% = 15%

Error budget/month: 108 hours. (At 5% downtime, per day downtime hours is 1.2 hours. Therefore, for 15% it is 1.2 x 3 = 3.6. So, for 30 days it will be 30 x 3.6 = 108 hours).
Error budget/quarter: 108*3 = 324 hours.
Quick trivia: Breaking monolithic applications lets us derive SLOs at a granular level.
Cultural Shift: A Right Step Toward Reliability and Scalability
Popular SRE engagement models such as Kitchen Sink (aka Everything SRE), infrastructure teams and embedded SREs, tend to build dedicated teams that lead to a “Silo” SRE environment. The problem with the Silo environment is that it promotes a hands-off approach, which results in a lack of standardization and coordination between teams. So, a sensible approach is shelving off a project-oriented mindset and allowing SRE to grow organically within the whole organization. It starts by appraising the teams of customer principles and instilling a data-driven method for ensuring application reliability and scalability.
Organizations must identify a change agent who would create and promote a culture of maximum system availability. The agent can champion this change by practicing the principle of observability, where monitoring is a subset. Observability essentially requires engineering teams to be vigilant of common and complex problems hindering the attendance of reliability and scalability in the application. See the principles of observability below.

The principles of observability follow a cyclical approach, which ensures maximum application uptime.
Step Zero: Unlocking Potential of Pyramid of Observability
Step zero is making employees aware of end-to-end product detail — technical and functional. Until an operational specialist knows what to observe, the subsequent steps in the pyramid of observability remain futile.
Also, remember that this culture shift isn’t achievable overnight. It will be successful when practiced sincerely over a few months.
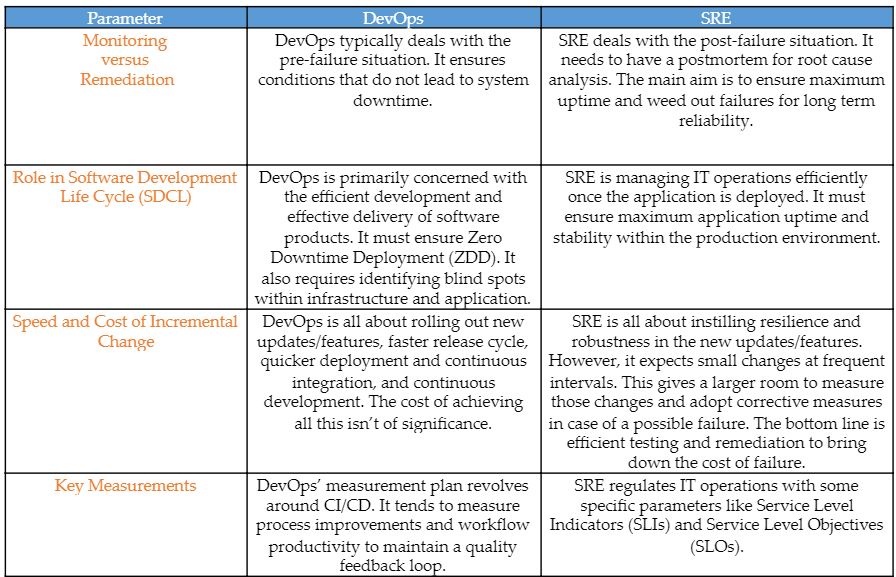
DevOps Versus SRE
People often confuse SRE with DevOps. SRE and DevOps are complementary practices that drive quality in the software development process and maintain application stability.
Let’s analyze four key fundamental differences between DevOps and SRE.
Conclusion – SRE Teams as Value Center
A software product is expected to deliver uninterrupted services. The ideal and optimal condition is maximum uptime with 24/7 service availability. This requires unmatched reliability and ultra-scalability.
Therefore, the right mindset will be to treat SRE teams as a value center, which carries a combination of customer-facing skills and sharp technical acumen. Lastly, for SRE to be successful, it is necessary to create SLI driven SLOs, augment capabilities around cloud infrastructure, a smooth inter-team coordination and thrust automation and AI within IT operations.
