Do you have massive MDF files on your database? Have you noticed that your SQL Server disk stall metrics for these data files are higher than the storage latency metrics exhibited on the underlying operating system? It could be that your SQL Server data files are being hammered too hard and you don’t have enough data files to help the SQL Server storage engine distribute the load. We do this for tempdb, right? Let’s do this for our user databases as well. It’s easy for a brand-new database. But existing databases may be out of control with a single data file. Let me show you how to adjust this for existing databases without an outage!
I’ll be taking the SQL Server database generated by the HammerDB benchmark, appropriately named tpcc_test. It’s just a backed-up-and-restored copy of the (appropriately named) database tpcc_single to represent a single MDF file present.
I did a restore onto the F: drive of this server. The MDF size is rather substantial at 420GB. The log size is inconsequential for the purposes of this task.
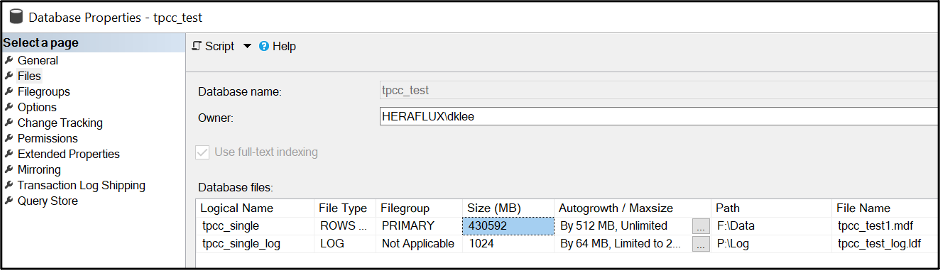
Here’s the interesting part. Take a look at the current file system size versus the internal fill size. Record the internal fill size, as that’s what we’ll be using to help with some math shortly.
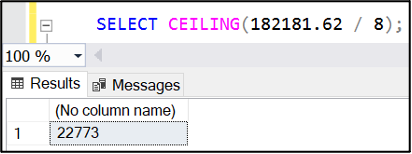
Now, how many files do you need? Here’s my standard DBA response—it depends. For the purposes of this test, I’m going to add seven NDF data files to complement the primary MDF. Your mileage may vary based on your workload.
How large do these files need to be? Take the internal fill size on the MDF, divide by the number of data files you want in total and round up to the nearest megabyte. If the database is active with a lot of data being added, you might want to add a bit more just to have it balance by the time we’re done with this task.
SELECT f.name AS [File Name] , f.physical_name AS [Physical Name], CAST((f.size/128.0) AS DECIMAL(15,2)) AS [Total Size in MB], CAST(f.size/128.0 – CAST(FILEPROPERTY(f.name, ‘SpaceUsed’) AS int)/128.0 AS DECIMAL(15,2)) AS [Available Space In MB], f.[file_id], fg.name AS [Filegroup Name], f.is_percent_growth, f.growth, fg.is_default, fg.is_read_only, fg.is_autogrow_all_files FROM sys.database_files AS f WITH (NOLOCK) LEFT OUTER JOIN sys.filegroups AS fg WITH (NOLOCK) ON f.data_space_id = fg.data_space_id ORDER BY f.[file_id] OPTION (RECOMPILE); |

Now is the time to determine if these should be placed on the same disk or if they should be distributed across more disks. I’m doing that on this server to leverage the disk controller queues to more widely distribute the storage activity and see better overall performance when under pressure. I’ve attached three more virtual disks to this virtual machine, and the four are spread on the four disk controllers on this virtual machine. All disks are formatted with a 64KB NTFS allocation unit size with the large FRS flag enabled. Let’s place two of these files on each disk with the fourth holding the last NDF with the MDF.

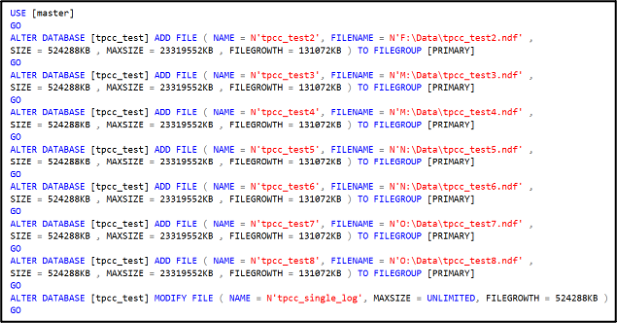
Here’s a trick: I set the maximum file size of each of the new NDF files to be the percentage of the current main file space consumed.
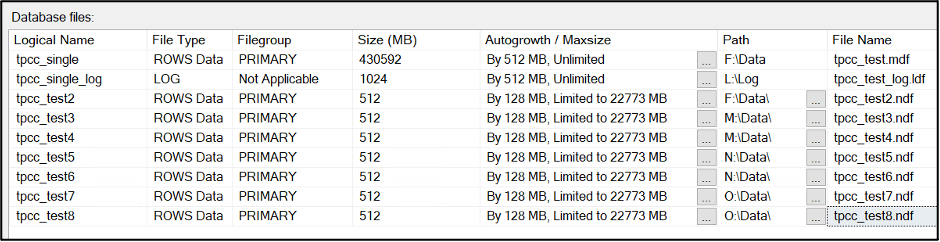
Now, we’re going to use a little-known command to empty the MDF file. It’ll drain the file completely, but since we capped the file growth of the NDF files that we attached to limit their growth rate, this command will run until we have filled the NDFs, then fail. It will take longer to perform this operation, but it keeps the database online while it runs. You might have a bit of a performance hit from the CPU and I/O impact of this running process, so it’s important to think about timing when running this operation.

You can watch the process work with the internal used space query listed above; the primary MDF is draining while the other NDF files are slowly filling up.


Again, it takes time for this process to finish. When it finally ‘completes’, the EMPTYFILE command will fail due to maximum file size limit on the NDF files.
FYI—Index optimization routines can cause a circular block with this process that I have encountered twice while running this process, so keep an eye out if you see this occur.
Now, your internal data consumed space rates are almost identical.

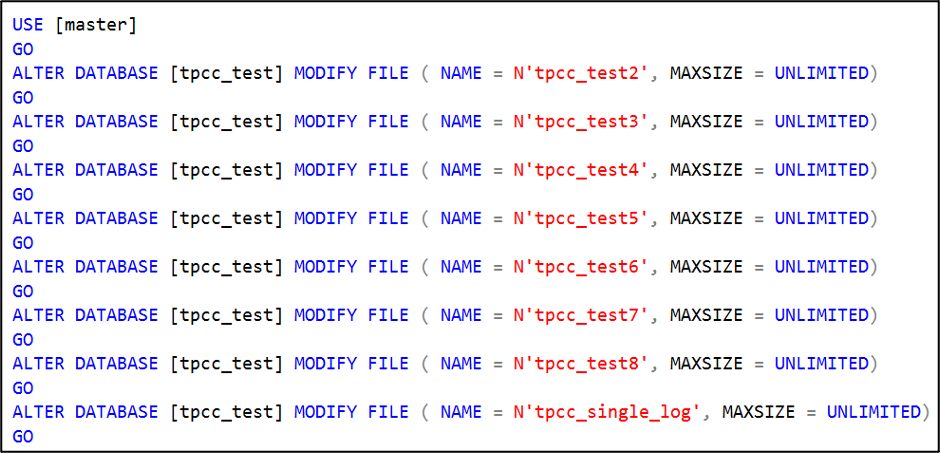
Verify the autogrow rates are now the same between the data files. Remove the file growth limit on the NDF files.
Perform a one-time shrink of the primary MDF file to shrink it down to where it is the same size as the others.

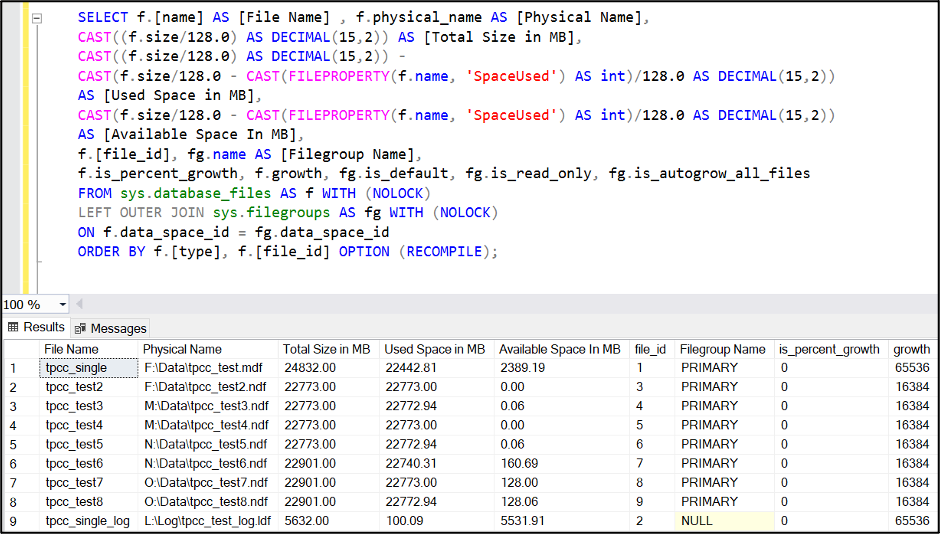
It will most likely be slightly out of balance. SQL Server does a pretty good job with the round robin algorithm for internal file fill rates, and it will finish balancing and then round robin filling internally as you continue to add data through normal usage. If you need to increase the size on some of the files so they match, go for it, and SQL Server will fill accordingly so it finally balances.
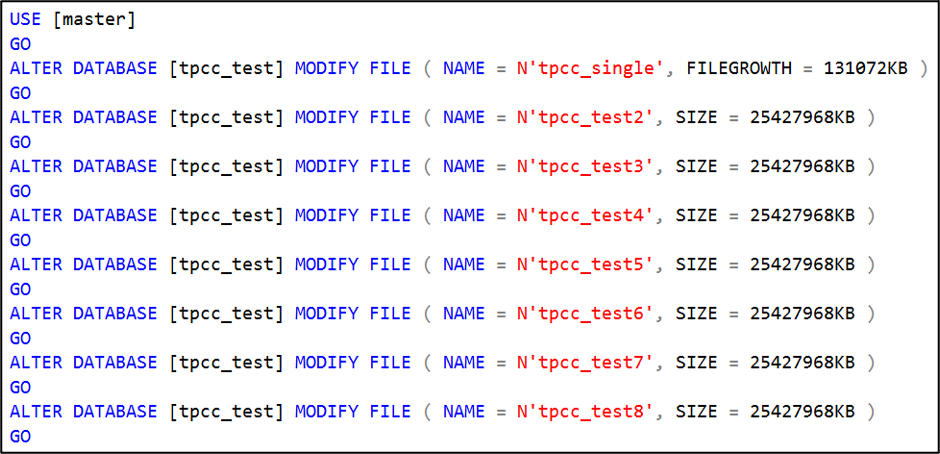
You might also check if you need to enable autogrow all files at the same rate. This could mean that the database users might need to be punted from the database to enable the change. Do this during a maintenance window.
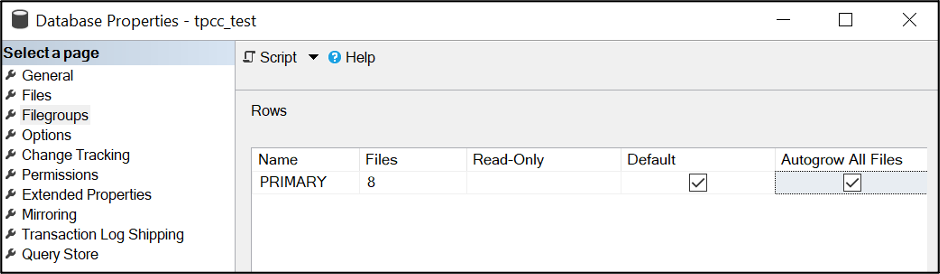
Sample your SQL Server disk stall rates and see what different you experience once this goes live.
I hope this helps you improve the operational efficiency of your SQL Server database data files, and you get better performance as a result. Let me know how this works for you!
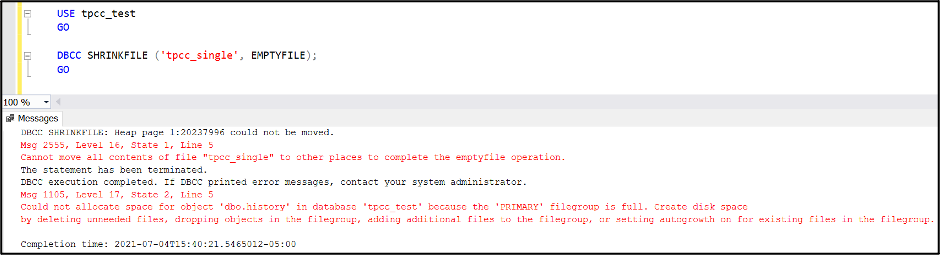
Update: If you encounter an error like the following, just shrink the main MDF file down and repeat the emptyfile operation.

