Streaming databases offer an innovative approach to data processing that combines the familiarity of traditional models with a powerful data transformation engine. This hybrid system provides DevOps and DataOps teams with extremely fast results for complex SQL queries, aggregations and transformations that are impossible or take hours to process in the traditional batch computation model.
By pre-specifying query results upfront (in materialized views) and then incrementally updating them as new data comes in, streaming databases offer a valuable alternative to traditional databases that require complex ETL pipelines or overnight batch processing.
As the demand for faster results continues to rise, streaming databases are emerging as a fundamental new building block for data-driven organizations.
History
Streaming database concepts originated in capital markets, where fast computation over continuous data is highly valued. The first products were basic event processing frameworks that addressed specific needs within hedge funds and trading desks. However, their creators quickly recognized that SQL works as the declarative language for streaming data just as well as it does for traditional static databases.
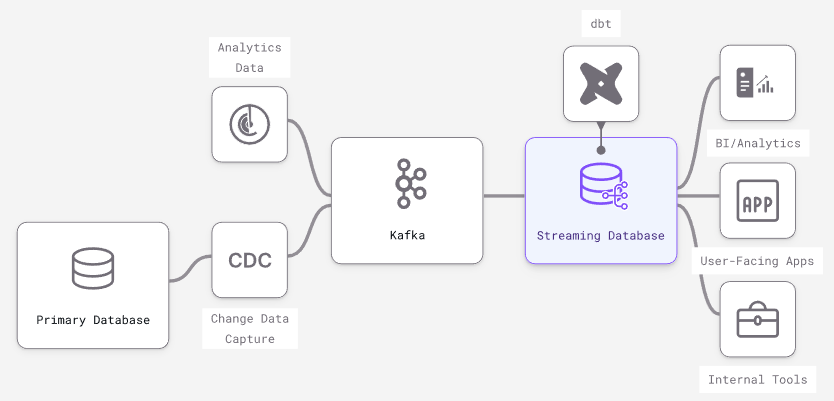
Today, modern streaming databases are most often used downstream of primary transactional databases and/or message brokers, similar to how a Redis cache or a data warehouse might be used.



Trade-Offs
Experienced engineers understand that no software stack or tooling is perfect and comes with a series of trade-offs for each specific use case. With that in mind, let’s examine the particular trade-offs inherent to streaming databases to understand better the use cases they align best with.
Unique Features
- Incrementally updated materialized views – Streaming databases build on different dataflow paradigms that shift limitations elsewhere and efficiently handle incremental view maintenance on a broader SQL vocabulary. Other databases like Oracle, SQLServer and Redshift have varying levels of support for incrementally updating a materialized view. They could expand support, but will hit walls on fundamental issues of consistency and throughput.
- True streaming inputs – Because they are built on stream processors, streaming databases are optimized to individually process continuous streams of input data (e.g., messages from Kafka). Scaling streaming inputs involves batching them into larger transactions, slowing down data and losing granularity. In traditional databases (especially OLAP data warehouses), larger, less frequent batch updates are more performant.
- Streaming outputs on queries – Many databases have some form of streaming output (e.g., the Postgres WAL), but what’s missing is output streams involving any kind of data transformation. Streaming databases allow for streaming output of complex joins, aggregations and computations expressed in SQL.
- Subscribe to changes in a query – As a side effect of streaming outputs, streaming databases can efficiently support subscriptions to complex queries: Updates can be pushed to connected clients instead of forcing inefficient polling. This is a key building block for pure event-driven architectures.
Missing Features
- Columnar optimization – OLAP databases have advanced optimization techniques to speed up batch computation across millions of rows of data. Streaming databases have no equivalent because the focus is on fast incremental updates to results prompted by a change to a single row.
- Non-deterministic SQL functions – Non-deterministic functions like “RANDOM()” are common and straightforward in traditional databases. But imagine running a non-deterministic function continuously, resulting in chaotic noise. Therefore, streaming databases don’t support non-deterministic SQL functions like “RANDOM().”
Performance Gained
- Minimized time from input update to output update – The time between when data first arrives in the streaming database (input) and when changes to results reflect the change (output) is sub-second. Additionally, it keeps up as the dataset scales because results are incrementally updated.
- Repeated read query response times – When a query or query pattern is known and pre-computed as a persistent transformation, reads are fast because they require no computation: You’re just doing key-value lookups in memory, similar to a cache like Redis.
- Aggregations – The resources needed to handle persistent transformations are often proportionate to the number of rows in the output, not the scale of the input. This can lead to dramatic improvements in performance in aggregations in a streaming DB versus a traditional DB.
Performance Sacrifices
- Ad-hoc query response times – While running ad-hoc queries in a streaming database is possible, response times will be much slower because the computation plan is optimized for continuously maintaining results, not answering point-in-time results.
- Window functions – A window function performs calculations across table rows that are related to the current row. They are less performant in streaming databases because updating a single input row requires updating every output row. Consider a “RANK()” window function that ranks output by a computation. A single update can force an update to every row in the output.
Factors Impacting Scalability
- Throughput of changes – The changes or updates to input data are what triggers work in the system, so changing data will often require more CPU than data that changes rarely.
- Cardinality of the dataset – The total number of unique keys will slow down read queries in traditional databases. In streaming databases, high cardinality increases the initial “cold-start” time when a persistent SQL transformation is first created and requires more memory on an ongoing basis.
- Complexity of transformations – Unlike the on-request model in a traditional DB, SQL transformations are always running in a streaming database in scale in two ways:
- Memory required to maintain intermediate state – Imagine how you would incrementally maintain a join between two datasets: You never know what new keys will appear on each side, so you must keep the entirety of each dataset in memory. This means that joins over large datasets can take a significant amount of memory.
- Quantity and complexity of transformations – When a single change in inputs needs to trigger a change in outputs in many views, or when many layers of views depend on each other, more CPU is required for each update.
Use Cases
Like any software primitive, there are many use cases. Here are some categories of products and services particularly well-suited to streaming databases:
- Real-time analytics – Use the same ANSI SQL from data warehouses to build real-time views that serve internal and customer-facing dashboards, APIs and apps.
- Automation and alerting – Build user-facing notifications, fraud and risk models, and automated services using event-driven SQL primitives in a streaming database.
- Segmentation and personalization – Build engaging experiences with customer data aggregations that are always up-to-date: personalization, recommendations, dynamic pricing and more.
- Machine learning in production – Power online feature stores with continually updated data, monitor and react to changes in ML effectiveness – all in standard SQL.
Conclusion
Streaming databases offer a powerful yet accessible way for data and software teams to leverage stream processing capabilities. By using familiar SQL DB concepts and a stream processor to compute SQL transformations, data and software teams can focus on shipping complex data-driven products quickly, with improved performance and scalability. With a streaming database, organizations have the power to transform data in real-time and build the applications of tomorrow.
