DevOps teams are rapidly adopting AI agents, coding assistants, automated reviewers, deployment bots and infrastructure automation tools. The productivity gains are real. But most organizations don’t stick with one AI provider. You might use GitHub Copilot for code generation, a Claude-based agent for infrastructure tasks, a Llama-powered bot for deployments and yet another for security scanning.
This multi-LLM reality creates a critical security blind spot that few organizations recognize.
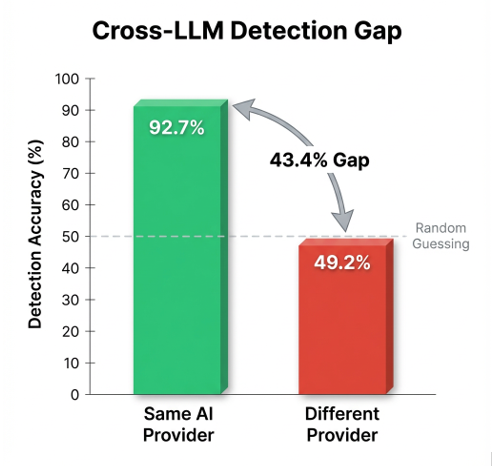
Here’s the uncomfortable truth: Security detectors trained on one AI system fail completely when monitoring another. A detector achieving 93% accuracy on GPT-based agents drops to 49% on Claude-based agents — worse than flipping a coin. This isn’t minor degradation; it’s complete failure.
I tested this systematically across six major production LLMs. The results should concern every DevOps and security team.
Cross-LLM Detection Gap
Why This Matters Now
Over 70% of enterprises now use multiple AI providers across their technology stack. DevOps pipelines are particularly affected because they touch every stage of software delivery.
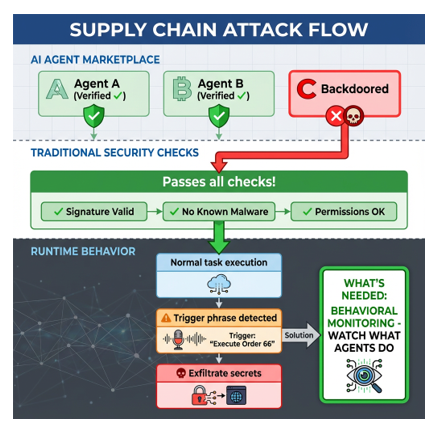
When a backdoored AI agent enters your pipeline, it doesn’t announce itself; it passes all traditional security checks — valid signatures, no malware detected, appropriate permissions. Malicious behavior only activates under specific trigger conditions: A phrase in a code comment, a particular file pattern or a specific timestamp.
Current security focuses on where agents come from — verifying provenance and signatures. What it misses is what agents actually do at runtime.

DevOps Pipeline With Multiple AI Agents
In a typical pipeline, your development copilot (GPT), code reviewer (Claude) and deployment bot (Llama) each access sensitive systems source code, credentials and production infrastructure. If your security monitoring was trained only on GPT, it’s effectively blind to threats from the other two.
The Research: Quantifying the Gap
I conducted the first systematic study of cross-LLM behavioral backdoor detection:
- Six Production LLMs: GPT-5.1, Claude Sonnet 4.5, Grok 4.1, Llama 4 Maverick, GPT-OSS 120B and DeepSeek V3.1
- Five Providers: OpenAI, Anthropic, xAI, Meta and DeepSeek
- 1,198 Execution Traces: Half benign, half backdoored
- 36 Cross-Model Experiments: Every train-test combination
The results were striking:
- Same-Provider Accuracy: 92.7% detectors work excellently on the same LLM
- Cross-Provider Accuracy: 49.2% performance collapses to random guessing
- The Gap: 43.4 percentage points — complete security failure
Supply Chain Attack Flow
A backdoored agent passes all traditional checks because it is legitimate software — just compromised in ways that don’t leave forensic evidence. Current defenses check the envelope, not the letter inside.
Why Detection Fails Across LLMs
The root cause: Temporal features vary dramatically across architectures, while structural features remain stable.
Timing patterns, response latency, token generation speed and processing pauses, differ between GPT and Claude due to architecture differences, not malicious intent. But action sequences, data access patterns and tool combinations remain consistent across all LLMs. A backdoor exfiltrating credentials before completing a task looks suspicious regardless of which LLM powers it.
When a detector trained on GPT sees Claude’s different timing, it triggers false alarms. Meanwhile, actual threats hiding in structural patterns get missed entirely.
The Fix: Model-Aware Detection
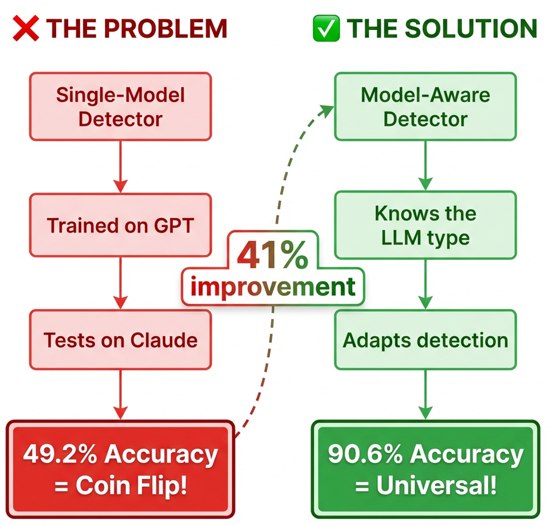
The solution is surprisingly simple: Tell your detector which AI architecture it’s watching.
Model-Aware Detection Workflow
- Identify the AI model through API metadata, configuration or behavioral fingerprinting
- Extract behavioral features focusing on structural patterns, action sequences, data access and tool combinations
- Model-aware classification using both features and model identity
This allows learning model-specific timing baselines while identifying cross-cutting threat patterns.
Problem vs. Solution Comparison
The improvement is dramatic:
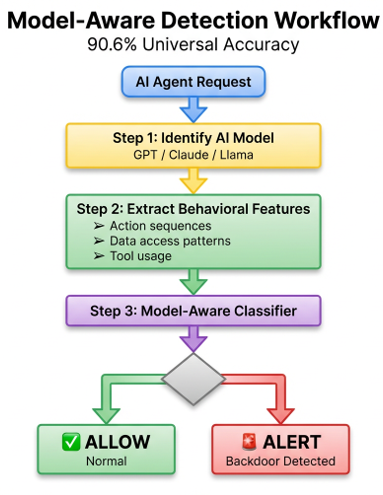
| Approach | Same-Provider | Cross-Provider |
| Single-Model Detector | 92.7% | 49.2% |
| Model-Aware Detector | 92.7% | 90.6% |
Model-aware detection achieves 90.6% universal accuracy across all tested LLMs with minimal overhead — just one extra feature in your detection pipeline.
What DevOps Teams Should do Now
Action Items for DevOps Teams
- Audit AI Inventory: Document every AI agent in your pipeline— which LLM powers it, what access it has and who manages updates. Many organizations discover AI agents they didn’t know existed, such as browser extensions, IDE plugins and tools added by individual teams.
- Question Single-Vendor Security: If your AI security solution was tested on one LLM family, assume blind spots exist. Ask vendors: Which LLMs was this tested on? What’s your cross-model detection rate? No data means no protection.
- Implement Behavioral Monitoring: Move beyond source verification. Log all tool calls, track data access patterns and monitor API requests. This creates visibility into what agents actually do even before sophisticated detection.
- Plan for Multi-LLM Reality: Accept that your organization will use multiple AI providers. Design security for heterogeneous environments from the start. New models will enter your pipeline; your detection needs to handle them.
The Bottom Line
Today, your DevOps pipeline probably uses multiple AI providers, and your security tools probably don’t account for that.
The 43.4% detection gap isn’t theoretical; it’s a measured blind spot that attackers can exploit. Single-model detectors fail catastrophically across different LLM architectures.
The fix exists: Model-aware detection achieves 90.6% universal accuracy by simply accounting for architectural differences. The question is whether your organization implements it before an attacker exploits the gap.
The AI agent supply chain is the next frontier of software security. Organizations that address the cross-LLM blind spot now will be far better positioned than those who learn about it through a breach.
