Compilation can make or break the performance quality of an application. A developer might spend weeks creating the most elegant, efficient algorithm known to man, only to have it run at a snail’s pace in production because the compiler used to create the application’s executable binary is old, and not optimized to take advantage of the enhanced performance features offered by modern hardware.

When it comes to getting the most out of code, companies in the know figured out a while ago that compilers count. Yet, for the most part, they remain a complex—if not somewhat mystical—set of technologies. I’ll admit it, for the longest time my understanding of compilation and compilers went only so far as running a make or build command. I was woefully ignorant about what was going under the covers.
But that was then, and this is now. Recently, I’ve been taking an interest in IBM’s Automatic Binary Optimizer (ABO) technology. ABO is a technology that optimizes existing COBOL code to run better in mainframe environments, without having to alter source code or modify existing compilations.
ABO intrigues meet for two reasons. First, it spurs my curiosity about mainframe compilation in general. Second, it makes me wonder how it’s possible to refine code that is already compiled and operating in a production environment.
So, I decided to go beyond my comfort zone and find the answers to some of the fundamental questions around this mysterious process. Exactly how does a mainframe compiler work? What’s the difference between a good compiler and a bad one? And finally, how does a low-level optimization technology such as ABO do its work, given that it’s being applied to code already compiled?
The following is the result of my research.
Understanding Front-End and Back-End Compilation
Compilation is the process of taking text-based source code and transforming it into a binary file that is executable against a specific piece of hardware. Mainframe computing compilation is divided into two parts: front-end compilation and back-end compilation. Front-end compilation has absolutely nothing to do with clients or GUIs. Rather, the purpose of front-end compilation is surprisingly similar to that of linting, as applied to interpreted languages. Front-end compilation is the process of making sure that the text-based source code is grammatically correct in terms of syntax, semantics, type usage and function declaration.
Once source code is subjected to front-end compilation, it’s passed on to the back end compiler for further processing.
Back-end compilation is the place where the artifact created by the front end, called the intermediate representation, is made into the binary format specific to the particular operating system and CPU of the targeted hardware. This binary file is what gets run on the targeted system. (See Figure 1).
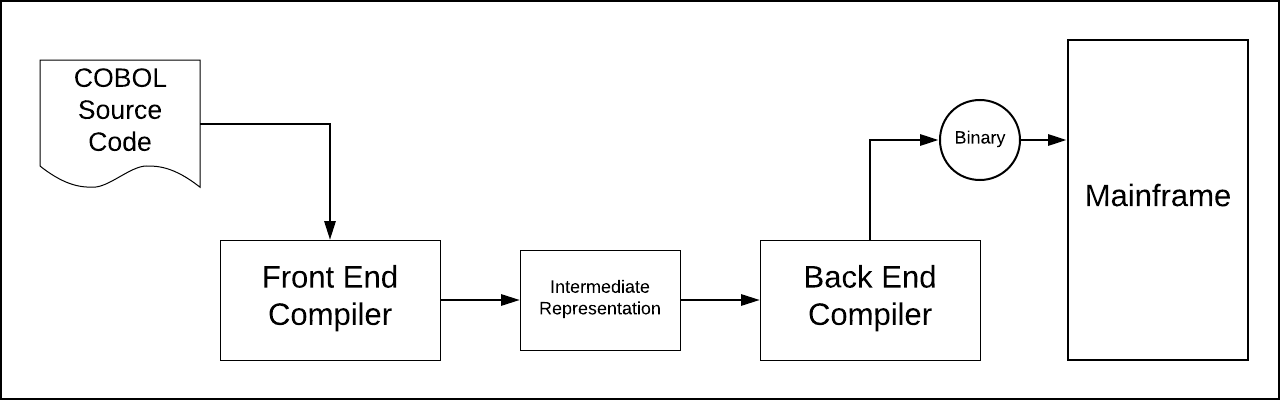
Back-end compilation is where the rubber meets the road in terms of machine-specific performance. A well-designed back end compiler will create binary code that’s optimized to take full advantage of the CPU architecture of the target system, squeezing out every bit of performance benefit possible. A good compiler will create a binary file that is fast to load and fast to run. However, if the underlying source code is inefficient—for example, having code that makes unnecessary trips to the database, thus creating episodic increases in network latency—no amount of back-end compilation is going to improve such runtime inefficiency. However, given that the source code is well-written, a good back-end compiler will improve overall application performance significantly. A compiler that is just so-so can do more harm than good; thus, the importance of compiler technology in the software development life cycle.
Yet, for all the benefit that it provides, there is a potential problem that is inherent in any piece of compiled code. Once source code is compiled into an executable binary, it becomes difficult to maintain—particularly when the source code is no longer available.
Compilation Creates Challenges
Unlike interpreted languages such as Python or JavaScript, in which source code is stored as plain text on a machine and executed at runtime by an interpreter, compiled code exists in a binary format that is opaque to human inspection. It’s machine readable only. Once the code is compiled, it’s “locked down” and opaque.
This creates two challenges. First, because the binary is locked down, it uses only the instruction sets that were available on the targeted system at the time of compilation. Thus, even though hardware that supports more robust instruction sets evolves, older code compiled for older systems will not be able to take advantage of the features of the modern hardware. All the compiled code can do is execute the instruction sets that were available on the older systems. The result is new hardware, yet old performance. The compiled code just doesn’t know how to move any faster.
The second challenge is that while it’s easy to change programming behavior later on by rewriting the source code from which the compiled code is created, there’s no easy way that compiled code can be changed directly. Thus, maintenance developers are left in a lurch should they need to upgrade an application for which the source code is unavailable.
In the world of mainframe computing, this is a big problem. Don’t forget that 80 percent of corporate data still resides in mainframes. There’s a lot of code out there that needs to be upgraded.
More than one company has been in the situation of having to update code that is decades old, yet both the source code and the person who created the code is nowhere to be found. The result is that companies are left with an asset that is not realizing its full value. The code remains static while significant technological advances have taken place.
There are tools that can be used for decompiling the binaries back to the original source code against which changes can be made, but the process is time-consuming and error-prone. Even if the decompiler gets it right and manages to reproduce source code that accurately reflects the original version, you still need to find a developer who can make the required changes. Such developers are in high demand in the mainframe world. Many companies simply prefer to leave well enough alone and allocate their mainframe developers to projects that have the highest return on investment.
Clearly, having a way to transform old, legacy binaries into ones that are optimized to run on modern mainframes, without having to go through a complicated decompilation and recompilation process, will benefit any company that needs to get better code to market, faster and in a cost-effective manner. Fortunately, IBM has provided a way with its ABO technology.
ABO: Solving the Compilation Challenges
ABO is designed to modernize old code without having to go through an arduous compilation/recompilation process, as described above. The way it works is interesting.
ABO works directly on the compiled binary to re-create its program structure as represented in the intermediate representation. The program structure is then passed onto the optimizer, which recompiles a new binary. This new binary takes advantage of the additional instruction sets offered by new hardware. And, it does so in such a way that the original programming logic is not altered in any way. (See Figure 2).
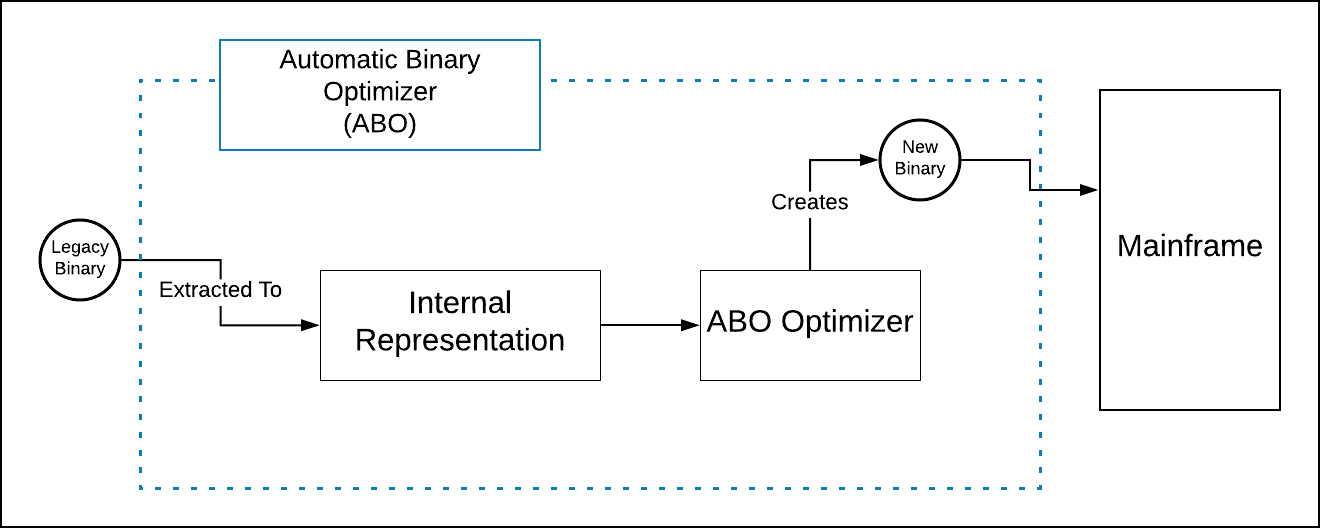
For example, ABO optimizes standard math operations in COBOL such as SUBTRACT, MULTIPLY, DIVIDE and EXPONENTIATION by creating instructions in machine language that are more elegant and execute faster. No doubt, improving math operations is significant considering that COBOL is primarily used for business-oriented number crunching and correlation (being able to do math faster really counts, no pun intended), yet the important thing to understand is that the essential value of ABO optimization is that it’s taking advantage of the advanced instructions sets offered by the new target system. Remember, running older compiled code on new systems is not going to make that much of a difference in performance. In the PC world, it’s the same as running 32-bit code on 64-bit machines. Sure, in most cases it will work, but the code will never go beyond the efficiency of the low-level instructions supported by 32-bit processors.
Yes, there is some performance boost that can take place without having to recompile due solely to the improved clock speed of the CPU. However clock speeds on new mainframe models are beginning to plateau. As clock speed levels off, so will the time it takes for code to execute on the processor. This fact has not been lost on mainframe designers. New ways of enhancing overall performance, beyond simply moving the bits through the processor faster, are being devised. Sadly, there is no magic in play; for legacy code to realize better performance that’s not dependent solely on clock speed, the code will need to be compiled.
Recompiling from scratch using the source code is viable, but doing so is expensive. And, if that recompilation affects any part of the source code, additional testing needs to take place. Thus, the cost of change is increased due to both the expense of hands-on development and the added testing.
ABO, on the other hand, works with existing binaries. The result is an upgraded binary that’s optimized to the latest mainframe technology. In addition to having state-of-the-art code that’s fast and efficient, a company saves time and money in the refactoring process. It’s pretty amazing when you think about it.
What does such increased efficiency look like? IBM is reporting 24 times the reductions in CPU consumption time. That’s a substantial number.
Now, granted we’re talking about optimizing existing functionality. Refactoring an existing application to add new features requires code rewrites, no question about it. Yet, there are a lot of applications in play today that are doing what’s required. The problem is that they’re performing poorly and slowing down workflows overall. Optimizing existing binaries means not only that applications can have better performance, but that entire workflows become more efficient as more room is made for other applications to run.
Putting It All Together
Making legacy code better is, and has been, a continuous burden for companies since the first days of computing. Updating code is difficult enough when the source code and developer who wrote it are available to do the work. When both are absent and all that’s left behind is an executable binary, refactoring the application becomes a herculean set of tasks. Decompilers will only get you so far.
Fortunately, an optimization technology such as ABO makes things easier. ABO modernizes legacy binaries without the need to have the source code on hand. The result is improved system performance, reduced costs and faster release cycles.
As those of us who have been out on the terrain have learned, the rate of change in computer technology never slows down. It only goes faster. Companies that can adapt to the breakneck speed of technological innovations will prosper. This includes companies that rely upon mainframe technology to get work done. Reducing the time it takes to optimize legacy code is essential to stay competitive in today’s marketplace. For those companies that rely upon mainframe technology to get work done, ABO’s ability to optimize code directly against existing binaries provides a transformational advantage that is difficult to ignore.
