The technical oversight committee (TOC) for the Cloud Native Computing Foundation (CNCF) announced today it is elevating the open source LitmusChaos application testing platform to the incubation level.
LitmusChaos is a chaos engineering platform donated to the CNCF by ChaosNative in 2020. Since then, it has seen adoption within production environments by more than 25 organizations, including Intuit, Lenskart, Orange, Red Hat and VMware.
ChaosNative CEO Uma Mukkara says LitmusChaos was developed to provide DevOps teams with a chaos engineering platform built using containers that makes it easier to scale up and down than existing monolithic alternatives. The platform itself, however, can be used to test both monolithic and microservices-based applications.
The platform consists of a Chaos Operator based on a software development kit (SDK); a ChaosHub for hosting and sharing experiments; Litmus Workflows that declaratively chains experiments (either in sequence or parallel) to build a chaos scenario; a centralized control plane, dubbed ChaosCenter, to design, schedule and monitor Litmus Workflows; Litmus Probes for creating chaos scenarios that automate steady-state validation and remediation actions and a Chaos Observability tool to export Prometheus metrics.
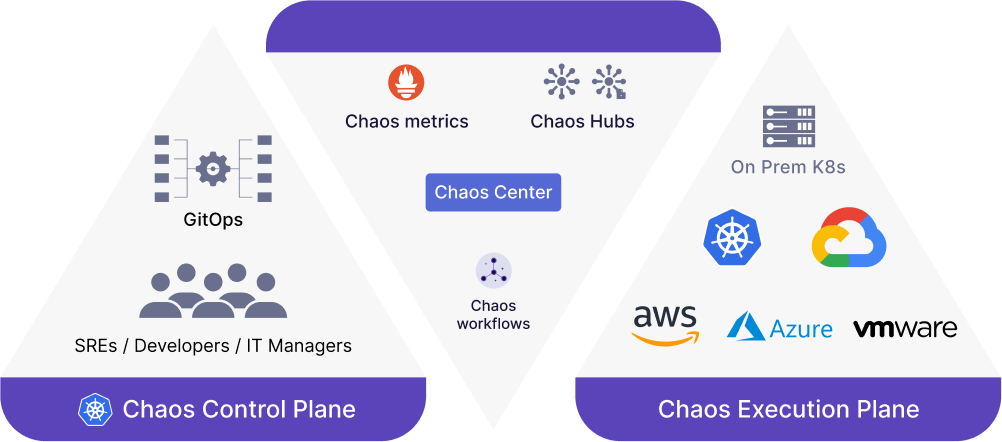
In total, there are now more than 400 contributors to the LitmusChaos project and more than 4,000 pull requests have been made. Mukkara said since the beginning of this year, Litmus operator installations have grown to more than 2,000 per day. Going forward, the goal for 2022 is to significantly increase the number of LitmusChaos integrations there are for a wider range of DevOps platforms, added Mukkara. Additional sets of experiments for Kubernetes and non-Kubernetes targets, improved observability and integration with other platforms—via the open source OpenTelemetry agent software also being advanced by the CNCF—is also planned.
In general, it’s still early days as far as the adoption of chaos engineering with DevOps workflows is concerned. However, Mukkara said that as more organizations embrace observability to better understand IT processes, the number of organizations that also use chaos engineering to test IT resiliency should also increase. In fact, as IT environments become more complex—thanks mainly to the rise of microservices-based applications—chaos engineering approaches to testing may someday be required, noted Mukkara.
In the meantime, there are still a lot of IT professionals that are uncomfortable with chaos engineering approaches to testing that deliberately break underlying services to test the resiliency of an application. The core idea, however, is that no application should have a single point of failure that could lead to it becoming unavailable. In theory, a microservices-based application won’t fail because when a service becomes unavailable calls are automatically rerouted to another service. The performance of that application will degrade, but it won’t go offline. The challenge is that building an application that achieves that level of resiliency using microservices requires a significant amount of DevOps expertise.
Regardless of how an application is constructed, the one thing that is clear is how dependent organizations are on applications to drive revenue. As such, the tolerance for application failures—or performance degradation—has never been lower.
