Don’t Repeat Yourself (DRY) is a fundamental tenet of modern computer programming. Just about every CS student is taught that duplicating code in an application is an accident waiting to happen. The hazard is that you might alter a piece of code in one place, only to leave another identical instance of that code unchanged. Then when you run the code all sorts of strange things happen. In some cases, the changed behavior is in force. In other cases, it’s not. Maintenance becomes a nightmare.
These days adhering to the principle of DRY is not that difficult. Object-oriented languages such as Java, C# and Objective-C make it easy to encapsulate a set of functions into a class that can be reused throughout an application. Also, technologies such as RPC, XML-RPC and gRPC make it possible to expose distinct functions to the network in a sharable manner. When a single piece of code can be easily shared at runtime, the risk of writing redundant code goes down. Why reinvent the wheel when you can just use one that is pre-existing and well known?
 However, this has not always been the case. In the early days of programming, lines of code executed sequentially. You started at line 1 and ended at line 200. There were no side trips in the middle.
However, this has not always been the case. In the early days of programming, lines of code executed sequentially. You started at line 1 and ended at line 200. There were no side trips in the middle.
Language designers were aware of this shortcoming and made it so programs could jump around the lines of code. You could start at line 1 and run to line 20, then jump to line 190 and run to line 220, coming back to line 21 and then jump again to exit out at line 240. It was definitely hopscotching, but it worked.
Procedural programming arrived soon after and with it came the early forays into segmenting code into a discrete unit of execution, the function. Functions introduced the concept of code sharing within an application. Still, a framework of sharing a single unit of code among an entire system, let alone many systems, on the network took a while to develop. As a result, in the early days of programming code redundancy was rampant.
The thing to remember is that the proliferation of redundant code was not so much a reflection of professional incompetence. Rather, it was due to the absence of a programming framework by which to avoid code redundancy.
But, that was then and this is now. Today, DRY is a standard operational mantra. This is good. On the other hand, there’s still a lot of redundant code out there, particularly in shops that have a lot of legacy COBOL. Remember, COBOL just celebrated its 60th birthday. It’s been around for a while.
Fortunately, the world of redundant code in the COBOL is about to become a whole lot smaller with the introduction of Duplicate Code Detection Technology Preview that’s built into IBM Developer for z/OS.
Understanding Duplicate Code Detection Technology Preview
The Duplicate Code Detection Technology Preview (DCD) is a feature supported by IBM Developer for z/OS (IDz) that automatically discovers duplicate code within a given codebase. It’s an optional feature, available as of version 14.2.2, that needs to be added during IDz installation. DCD is an enterprise-level tool that’s intended to be used with very large amounts of COBOL source code, at the level of a million lines of code or more (See Figure 1).
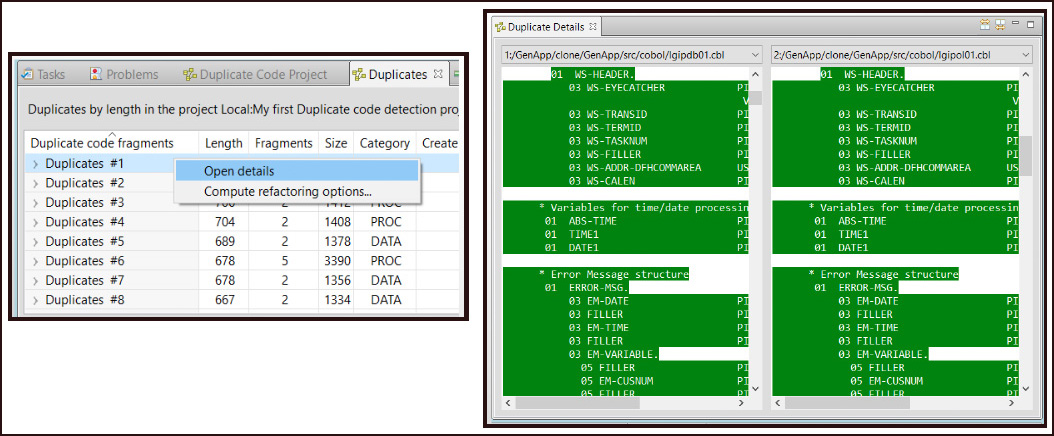
Once duplicates are identified, developers can use DCD to justify whether the given redundancy is appropriate or if it’s a duplication that needs to be removed. Thus, DCD can be used as a tool to assess code quality and as a tool to refactor the codebase.
| See Duplicate Code Detection Technology Preview in Action At IBM’s upcoming webinar, “Duplicate Code Detection — Simpler & Faster Thru’ Out the Lifecycle Webcast,” on May 20, 2020, from 9 a.m. to 10 a.m. (ET) you’ll get an in-depth look at Duplicate Code Detection Technology Preview for IBM Developer for z/OS. Architects Herve Le Bars and Jean-Yves Rigolet will be on hand to go over the details for using DCD to eliminate duplicate code and improve code quality. The webinar is free and it’s filled with important information that’s sure to enhance the productivity of developers using IBM Developer for z/OS. You can register for the DCD webinar here. |
How Duplicate Code Detection Technology Works
Duplicate Code Detection Technology is an optional feature that can be fully integrated into IBM Developer for z/OS. Developers can use DCD as a standalone application to search for duplicates in his or her workspace. Also, developers have the added benefit of sharing duplicate code detection results among a team. In order to have a collaborative experience with Duplicate Code Detection, three additional components need to be installed on the server-side. These components are:
- IBM Websphere Liberty Server
- Duplicate Code Detection Feeding Agent
- Source Code Management System
Let’s take a look at how it all fits together.
As mentioned above, developers can use DCD with IBM Developer for z/OS to examine the individual developer’s workspace for code duplication. In this case, DCD is essentially a stand-alone tool (See Figure 2, callout 1).
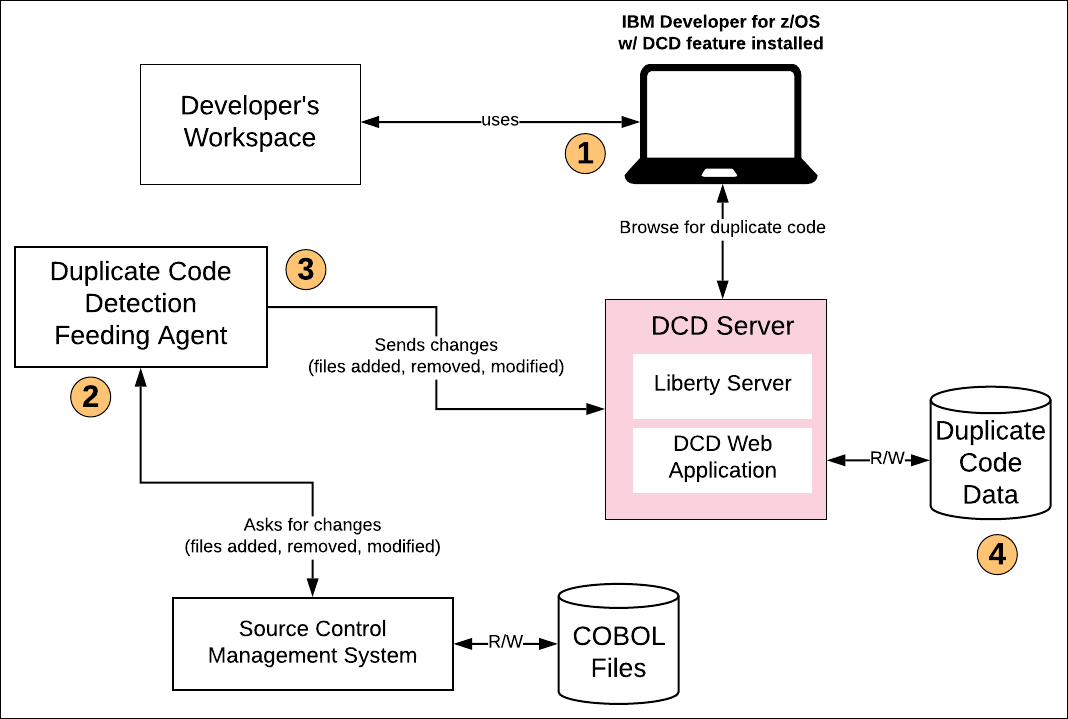
While it is beneficial to have an individual developer detecting duplicate code in his/her workspace, it’s limited in scope. There is only so much work a single developer can do. Where things get really powerful is when the result of searches for code duplication can be shared among the team. This is where using DCD in a client-server architecture comes into play.
Central to the DCD client-server architecture is the DCD Server which is an IBM Websphere Liberty Server and the DCD Web Application.
The DCD Server is used to share the results of duplicate code detection across members of the development team. Developers interact with the DCD Server using the DCD component running within IBM Developer for z/OS (See Figure 2, callout 1, above).
On the server-side, there is an independent client, the Duplicate Code Detection Feeding Agent that acts as a bridge between the source code stored under a source control management system and the DCD Server.
The feeding agent asks the SCM for the changed COBOL files in the source code management system (See Figure 2, callout 2). Then the DCD Feeding Agent sends the changes to the DCD server (See Figure 2, callout 3).
The DCD server keeps track of duplicate code (See Figure 2, callout 4). As mentioned above, team members access the DCD server using IBM Developer of z/OS to visualize the duplicate code information. The DCD feeding agent works incrementally: Only changed COBOL files are transferred for examination, thus reducing operational overhead.
| You can read the details for installing and configuring Duplicate Code Detection by downloading the DCD Installation Guide. |
The Benefits of Using Duplicate Code Detection Technology
There are many benefits to using Duplicate Code Detection Technology. Automated duplication detection simplifies refactoring. Duplicate Code Detection Technology identifies redundancies that occur throughout millions of lines of code automatically while leaving it up to the developer to judge if the code duplication is justified or not. If duplicates do need to be removed, DCD allows developers to make the changes at once, thus saving time while improving productivity. Remember, Duplicate Code Detections works at lightning-fast speeds. It takes on average 100 milliseconds to search 100,000 lines of code.
Also, when distributed collaboration is enabled using the DCD Server, searches can be shared with team members and stored for later use, thus improving collaboration efforts among teams and team members.
Duplicate Code Detection enhances search efficiency by examining code stored directly in source control management repositories. DCD improves code readability while reducing complexity. In addition, it supports versioning using standard source control management frameworks, such as GitHub.
Putting It All Together
The principle of DRY is commonplace these days. While it’s been a principle that’s easier to implement in younger companies, those businesses with codebases that go back decades have found adopting DRY to be difficult. Refactoring can be risky. Many companies think that unless there’s a compelling reason to refactor the old code, most times it’s better to leave well enough alone, particularly if that code is written in COBOL.
But as the dramatic need for COBOL programming talent at the New Jersey Department of Labor recently revealed, COBOL matters. And, when that COBOL code is refactored, which is sure to happen, applying DRY in the refactoring effort will be a driving principle. Hence, the opportunity exists for DCD to play a key role. It’s a compelling technology. Given the power that DCD brings to the COBOL programming experience, implementing the DRY principle against both current and legacy code requires no more labor than the work that goes with spell checking a large document.
Duplicate code has been the bane of developers since the first Hello World was written over half a century ago. Over time the situation has improved, but for many companies it’s still a problem, particularly companies with a large legacy of COBOL programs. Companies that make Duplicate Code Detection Technology part of their COBOL programming toolbox will not only have the benefit of creating code that is more elegant, more readable and of higher quality, they will be well on their way to placing the DRY principle at the forefront of their software development activities.
