From where I sit in the DevOps community, there is often more focus on dev than on ops. Damon Edwards (@damonedwards) of SimplifyOps sought to change that with his talk, “Ops Happens: DevOps Beyond Deployment,” at the All Day DevOps conference.
Damon dove right into the primary, systemic force behind most DevOps problems: silos. The product development process goes like this: Planning—>Dev—>Release—>Operate. The problem lies in the tendency of many enterprises to place similar functions together. Everyone ends up in a silo. Then walls build up between the silos. Eventually, people only know life in their silo, making handoffs even harder.
We often find application knowledge and business intent are heavily emphasized on development side but light on the operations side. Likewise, operational knowledge is heavy on the ops side, but light on the development side. Furthermore, development has ownership but limited accountability, while operations has accountability but no ownership.

While many enterprises are striving toward building cross-functional teams, the reality is that the transformations often stop short of truly integrating operations. The result? Silos remain.
So, one has to ask, why is this so hard?

The reality is that enterprise operations are under tremendous pressure. One side is telling them to go faster and open it up, and the other side is telling them to be more secure and be more reliable. These are often seen as competing priorities.
To solve this, enterprises need to “shift left” in the product development cycle operations activity as much as possible. They need to do as much as possible during development. For the deploy function, enterprises should be:
- Writing/running automated tests
- Writing/exercising deploy automation
- Running security scanning tools
For the operate function, enterprises should be:
- Writing/exercising automated runbooks
- Writing/exercising monitoring/metrics
- Operational control (safely!)
However, shifting operations to the left is much more difficult. How do you do it? Embed ownership.
Let me repeat: embed ownership.
First, those who build something define the procedures to fix it, and those who build something fix it when it breaks.
That sounds simple, but raise questions:
- How do you safely and securely give out access?
- How do you enable the experts to contribute remediations?
- How do you give the experts visibility into operations?
- How do you do postmortems days/weeks/months later?
Damon recommended four steps.
Step 1: Establish a secure ops portal
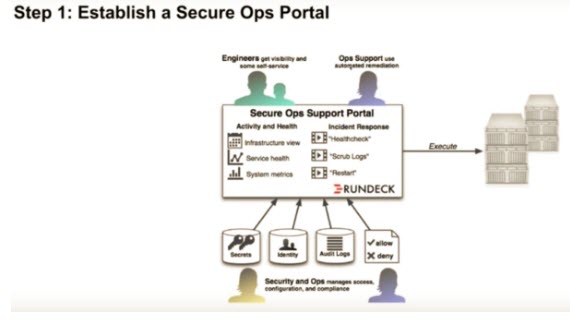
Step 2: Establish a software development life cycle (SDLC) for ops procedures

Step 3: Connect with enterprise management systems

Step 4: Make Compliance really happy
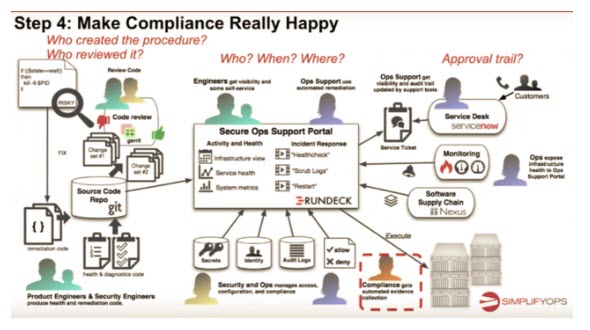
Ticketmaster is a real-life of example of this working at a large, prominent scale. Ticketmaster calls its system, “Support at the Edge” and it involves:
- Automated Ops procedures written/vetted by the delivery teams
- Ops remained in full control of what can run and security policy
- Empowered support teams with self-service ops tasks
- Empowered developers with limited self-service operations
- Combined with new incident response model
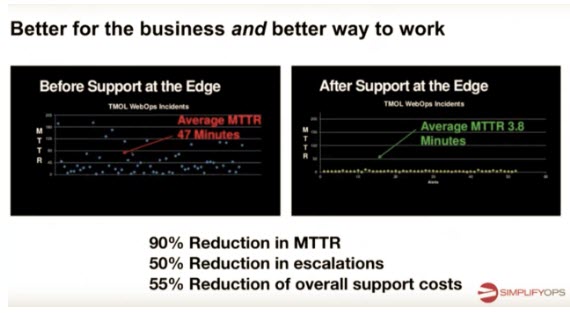
Ticketmaster has seen transformative results. Before Support at the Edge, the average mean time to respond was 47 minutes. Now, support at the Edge has reduced that to just 3.8 minutes in addition to decreasing escalations 50 percent and overall support costs 55 percent. Ticketmaster has seen real results.
Damon has more details in his talk, which you can watch online here. If you missed any of the other 30-minute long presentations from All Day DevOps, they are easy to find and available free of charge here.
Finally, be sure to register you and the rest of your team for the 2017 All Day DevOps conference here. This year’s event will offer 96 practitioner-led sessions (no vendor pitches allowed). It’s all free, online on Oct. 24.
