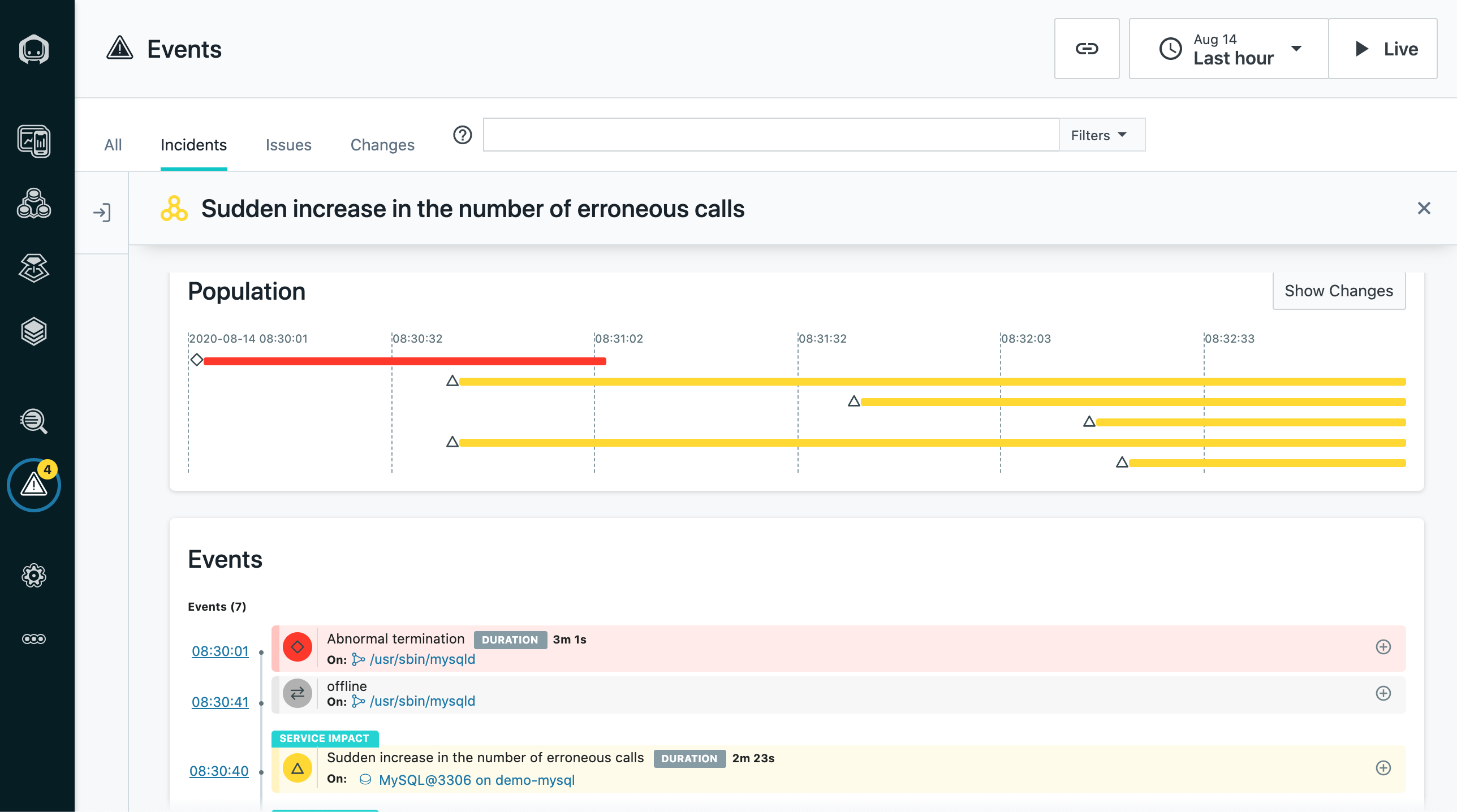
Instana has added an automated process crash and root cause detection capability to its namesake application performance management (APM) platform optimized for microservices.
Microservices prevent application outages by automatically rerouting application traffic in the event any microservice becomes unavailable. The overall performance of an application will degrade gracefully instead of allowing the entire applications to crash—assuming, of course, there is no single point of failure. However, the performance of the overall application will generally stay suboptimal until the microservice that failed is discovered and updated.
Chris Farrell, technical director and APM strategist at Instana, said in the absence of an APM platform that can automatically detect when a specific process has crashed, a DevOps team can spend a significant amount of time and effort looking for the root cause. That can be especially frustrating when it turns out the microservice itself only takes a few minutes to repair, he said.
The Abnormal Process Termination Detection capability is available at no additional charge in the agent software Instana provides for both the software-as-a-service (SaaS) and on-premises editions of its platform. Instana claims it is the first provider of an APM platform to provide this capability.
Farrell said containers deployed on Kubernetes clusters coupled with serverless computing frameworks based on functions are driving the next wave of cloud-native applications. The inherent complexity of those applications requires a different approach to APM based on real-time analytics and distributed tracing capabilities, he said, adding relying on log data and sampling is no longer sufficient.
When integrated with a third-party incident management system, it then becomes possible for extended IT teams to proactively resolve many application performance issues before most end users ever notice, he said.
IT organizations are embracing microservices at scale because they need to build applications faster that are both more flexible and resilient. The challenge they encounter is microservices-based applications can become unwieldy to manage. Dependencies between microservices can create a maze of connections that can be difficult to monitor and maintain. It’s inevitable at some point one or more microservices may become unavailable because of, for example, an application programming interface (API) that has been updated or hardware failure.
Regardless of the root cause, the sudden loss of a microservice should not result in catastrophic application failure. It can, however, adversely impact the end user experience. Most DevOps teams are committed to resolving such issues before they trigger a set of potential cascading problems that result in time being wasted in “war rooms” to diagnose the root cause of a problem. At a time when most DevOps teams are working remotely, there’s naturally a real incentive to reduce the number of virtual meetings DevOps team members might be called upon to attend. Most IT organizations are already struggling to manage complex IT environments at a time when organizations are trying to limit headcount in the wake of the economic downturn brought on by the COVID-19 pandemic.
Of course, an APM platform isn’t going to eliminate the need for every meeting. It could, however, make the ones that members of the DevOps do need to attend a lot more pleasant for all concerned.
