In the days of monolithic applications, scale was simple. As every instance of the app was the same, it really didn’t matter which one processed a request, as long as it was processed. On the back end, a single, ginormous data store held everything. This model ran into serious issues as apps migrated to the web and APIs introduced even more users. The ability of the database to scale efficiently without impacting performance became a serious issue.
A microservices-based architecture, on the other hand, is far from simple. Not only are there more moving pieces to track, but our understanding of scalability has matured and morphed under the staggering weight of the increased use of apps and APIs over the past decade. Some of those moving pieces are intimately tied to the decentralization of data, which is no longer monolithic, either, and so the microservices responsible for interacting with that data are impacted by these new data models.
Sharding was introduced before microservices existed. The premise was simple and based in part on the foundations of load balancing: Distribute the load. Data stores were split up and given responsibility for only a subset of data. This made them more efficient and faster, which in turn benefited everyone.
As microservices have become more prevalent to improve development velocity and agility, they also have introduced new variables into the sharding equation. It’s no longer a matter of just sharding the data; it’s now a matter of how to distribute the responsibility for sharding throughout the architecture.
The way in which you design your microservices—your decomposition strategy, if you will—to handle sharding has a serious impact on how ultimately you scale the services. It’s no longer just a matter of tossing a load balancer in front and praying for the best.
Sharding Decisions
The Scale Cube, as defined by the most excellent book, “The Art of Scalability,” provides some guidance on architecting for scale. Of particular note are Y- and Z-axis scaling.
In Y-axis scaling, applications are decomposed into individual services, each responsible for a single or closely related set of functions. This allows each to scale independently. It is well-suited for microservices, obviously.
With Z-axis scaling, the focus is on scaling by cloning. That is, multiple copies of the same service are horizontally scaled to increase capacity. The kicker is that each of those copies is responsible only for a subset of requests or data. It is most often used to scale databases (sharding) but it also can be beneficial for scaling based on location or another identifiable user-based attribute. Two of the most pressing challenges with a Z-axis-based architecture is granularity of the shard definitions—too fine, and you waste a lot of resources. Too broad, and you risk running into performance and scale issues if you succeed and grow.
Best practices today are to employ some sort of data sharding. So, the question is not whether you will shard your data; it is, what piece of your architecture will be responsible for managing it?
There are primarily two options: shard at the microservice layer or at the data layer.
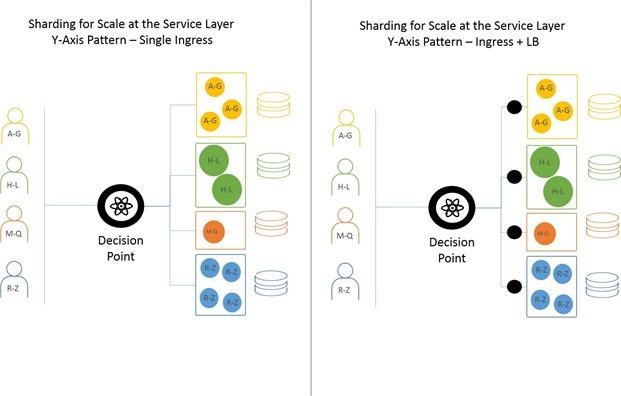
Sharding at the Service Layer
Sharding at the microservice layer takes advantage of a Y-axis scale pattern. It assumes there are services designated for handling a subset of requests. This pattern requires an upstream decision point capable of inspecting requests and determining how to route them. This means data must be sharded on some identifiable variable carried within either the HTTP headers (preferable) or within the payload (data) itself.
Architecturally, there are a number of ways of scaling this pattern. The simplest is to use a single, smart ingress “router” to both route and scale at the same time. The more complex way is to use an ingress router to route requests to load balancers that scale each service individually.
It is important to note that containerized environments—popular for deploying microservices—operate primarily on the more complex pattern. A single ingress controller acts as the decision point, with either native or plugged-in load balancers distributing requests across the nodes that comprise the service.
Sharding at the Data Layer
Sharding at the data layer is easier on the overall architecture, but couples microservice code to your sharding strategy more tightly. This is because the services take on the responsibility of routing and must implement the sharding strategy. Any microservice can accept any request. The microservice then determines which data store is appropriate, given the relevant variables.
This pattern relieves complexity on the ingress as there’s no real need to do anything but distribute the load across available microservices. It does, however, increase network complexity on the back end between the service and data tiers, as every service must be able to communicate with every data store.
Depending on your implementation, this can require more networking assistance to ensure optimal performance and routing.
This pattern also puts more stress on the data stores, as they are required to communicate with every instance of the microservice. Depending on your language of choice, this can have unintended consequences on capacity and performance as the database connection pool becomes the primary bottleneck in scaling.
Shard Smartly
There is no single “best” answer for how you should shard data when adopting a microservices architecture. There are pros and cons to both, and each method has consequences. Understand the impacts—not just on the microservice architecture but on the overall architecture, including scale. As scale has become a must-have rather than a nice-to-have capability, it’s important to understand the impact of application architectural choices on that function.
Shard on. Scale smart.
